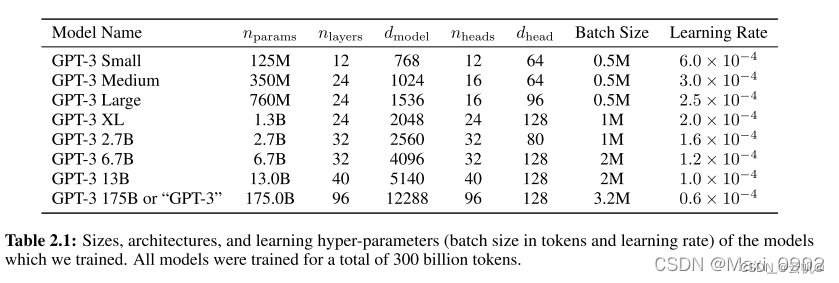
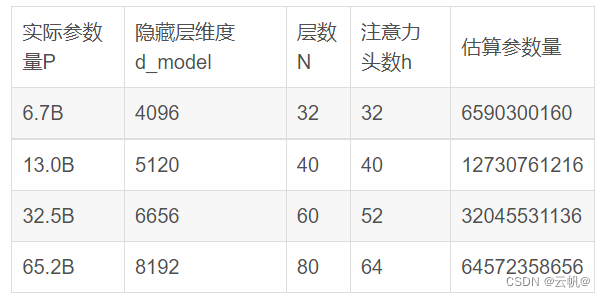
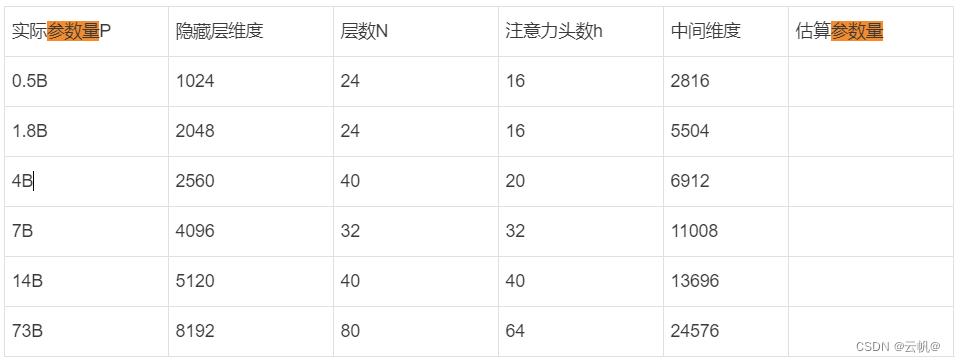
一、目录 不同大小的模型,参数应该如何确定? scale law 预训练解析 模型参数、计算量、数据量大小的关系。 二、实现 不同大小的模型,参数应该如何确定? gpt3 不同大小模型参数: llama 系列 参数统计(根据版本不同,算法会发生改变,参数估算量不同,但隐藏层、层数、注意力头数等超参数相同) baichuan系列: qwen系列5. chatglm 系列 scale law 预训练解析 以baichuan2 为例: 2.1 Log Flops: 什么意思&#x









 5. chatglm 系列
5. chatglm 系列
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3707
3707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






