






新智元报道
编辑:Joey David
【导读】近日,谷歌团队推出了一项新Transformer,可用于优化全景分割方案,还登上了CVPR 2022。
最近,谷歌AI团队受Transformer和DETR的启发提出了一种使用Mask Transformer进行全景分割的端到端解决方案。
全称是end-to-end solution for panoptic segmentation with mask transformers,主要用于生成分割MaskTransformer架构的扩展。
该解决方案采用像素路径(由卷积神经网络或视觉Transformer组成)提取像素特征,内存路径(由Transformer解码器模块组成)提取内存特征,以及双路径Transformer用于像素特征和内存之间的交互特征。
然而,利用交叉注意力的双路径Transformer最初是为语言任务设计的,它的输入序列由几百个单词构成。
而对视觉任务尤其是分割问题来说,其输入序列由数万个像素组成,这不仅表明输入规模的幅度要大得多,而且与语言单词相比也代表了较低级别的嵌入。
全景分割是一个计算机视觉问题,它是现在许多应用程序的核心任务。
它分为语义分割和实例分割两部分。
语义分割就比如为图像中的每个像素分配语义标签,例如「人」和「天空」。
而实例分割仅识别和分割图中的可数对象,如「行人」和「汽车」,并进一步将其划分为几个子任务。
每个子任务单独处理,并应用额外的模块来合并每个子任务阶段的结果。
这个过程不仅复杂,而且在处理子任务和整合不同子任务结果时还会引入许多人工设计的先验。

在 CVPR 2022 上发表的「CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation」中,文章提出从聚类的角度重新解读并且重新设计交叉注意力cross attention(也就是将相同语义标签的像素分在同一组),从而更好地适应视觉任务。
CMT-DeepLab 建立在先前最先进的方法 MaX-DeepLab 之上,并采用像素聚类方法来执行交叉注意,从而产生更密集和合理的注意图。

kMaX-DeepLab 进一步重新设计了交叉注意力,使其更像一个 k-means 聚类算法,对激活函数进行了简单的更改。
结构总览
研究人员将从聚类的角度进行重新解释,而不是直接将交叉注意力应用于视觉任务而不进行修改。
具体来说,他们注意到Mask Transformer 对象查询可以被认为是集群中心(旨在对具有相同语义标签的像素进行分组)。
交叉注意力的过程类似于 k-means 聚类算法,(1)将像素分配给聚类中心的迭代过程,其中可以将多个像素分配给单个聚类中心,而某些聚类中心可能没有分配的像素,以及(2)通过平均分配给同一聚类中心的像素来更新聚类中心,如果没有分配像素,则不会更新聚类中心)。
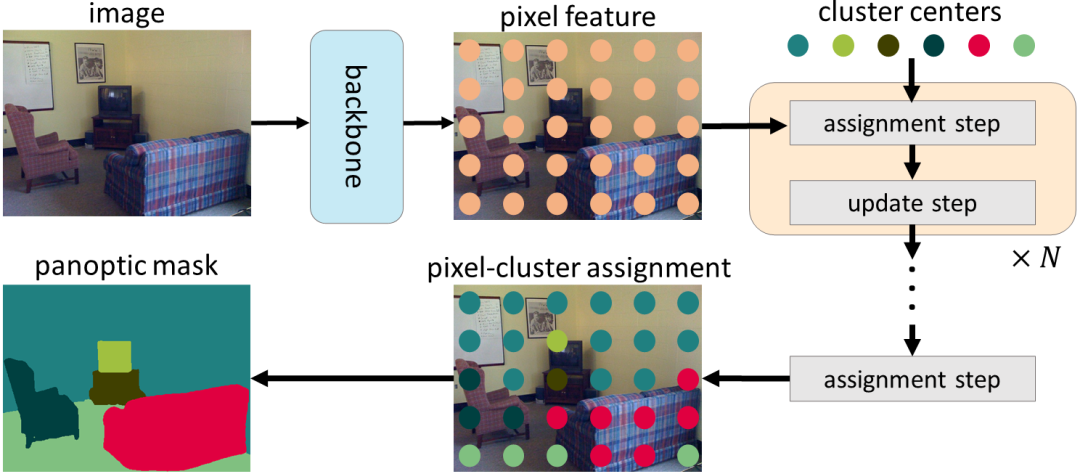
在CMT-DeepLab和kMaX-DeepLab中,我们从聚类的角度重新制定了交叉注意力,其中包括迭代聚类分配和聚类更新步骤
鉴于 k-means聚类算法的流行,在CMT-DeepLab中,他们重新设计了交叉注意力,以便空间方面的softmax操作(即沿图像空间分辨率应用的 softmax 操作),实际上将聚类中心分配给相反,像素是沿集群中心应用的。
在 kMaX-DeepLab 中,我们进一步将空间方式的 softmax 简化为集群方式的 argmax(即沿集群中心应用 argmax 操作)。
他们注意到 argmax 操作与 k-means 聚类算法中使用的硬分配(即一个像素仅分配给一个簇)相同。
从聚类的角度重新构建MaskTransformer的交叉注意力,显著提高了分割性能,并简化了复杂的Masktransformer管道,使其更具可解释性。
首先,使用编码器-解码器结构从输入图像中提取像素特征。然后,使用一组聚类中心对像素进行分组,这些像素会根据聚类分配进一步更新。最后,迭代执行聚类分配和更新步骤,而最后一个分配可直接用作分割预测。

为了将典型的MaskTransformer解码器(由交叉注意力、多头自注意力和前馈网络组成)转换为上文提出的k-means交叉注意力,只需将空间方式的softmax替换为集群方式最大参数。
本次提出的 kMaX-DeepLab 的元架构由三个组件组成:像素编码器、增强像素解码器和 kMaX 解码器。
像素编码器是任何网络主干,用于提取图像特征。
增强的像素解码器包括用于增强像素特征的Transformer编码器,以及用于生成更高分辨率特征的上采样层。
一系列 kMaX 解码器将集群中心转换为 (1) Mask嵌入向量,其与像素特征相乘以生成预测Mask,以及 (2) 每个Mask的类预测。
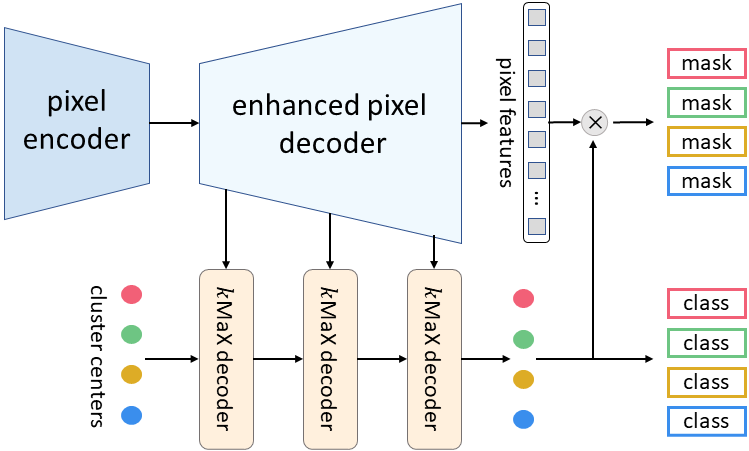
kMaX-DeepLab 的元架构
研究结果
最后,研究小组在两个最具挑战性的全景分割数据集 COCO 和 Cityscapes 上使用全景质量 (PQ) 度量来评估 CMT-DeepLab 和 kMaX-DeepLab,并对比 MaX-DeepLab 和其他最先进的方法。
其中CMT-DeepLab 实现了显著的性能提升,而 kMaX-DeepLab 不仅简化了修改,还进一步提升了,COCO val set 上的 PQ 为 58.0%,PQ 为 68.4%,44.0% Mask平均精度(Mask AP),Cityscapes 验证集上的 83.5% 平均交集比联合(mIoU),没有测试时间增强或使用外部数据集。

从聚类的角度设计,kMaX-DeepLab 不仅具有更高的性能,而且还可以更合理地可视化注意力图以了解其工作机制。
在下面的示例中,kMaX-DeepLab 迭代地执行聚类分配和更新,从而逐渐提高Mask质量。
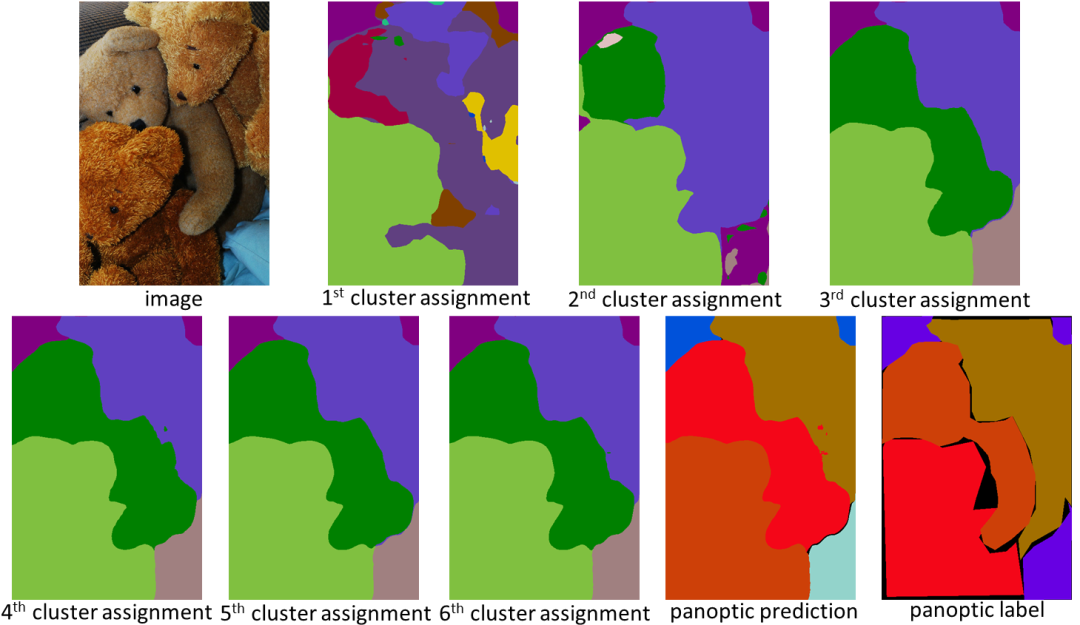
kMaX-DeepLab 的注意力图可以直接可视化为全景分割,让模型工作机制更合理
结论
本次研究展示了一种更好地设计视觉任务中的MaskTransformer的方法。
通过简单的修改,CMT-DeepLab 和 kMaX-DeepLab 重新构建了交叉注意力,使其更像一种聚类算法。
因此,所提出的模型在COCO 和 Cityscapes数据集上实现了最先进的性能。
研究团队表示,他们希望 DeepLab2 库中 kMaX-DeepLab 的开源版本有助于未来对专用于视觉Transformer架构设计的研究。
参考资料:
https://ai.googleblog.com/
- END -
















 4532
4532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









