








本文是对 A survey of Transformer的提炼和总结。
0 前言
Transformer在人工智能领域取得了巨大的成功, 如NLP, CV, 音频处理等等。 针对Transformer的改进工作也层出不穷, 这些Transformer的变体大概可以分为3类:模型结构的优化, 预训练, 以及Transformer的应用。
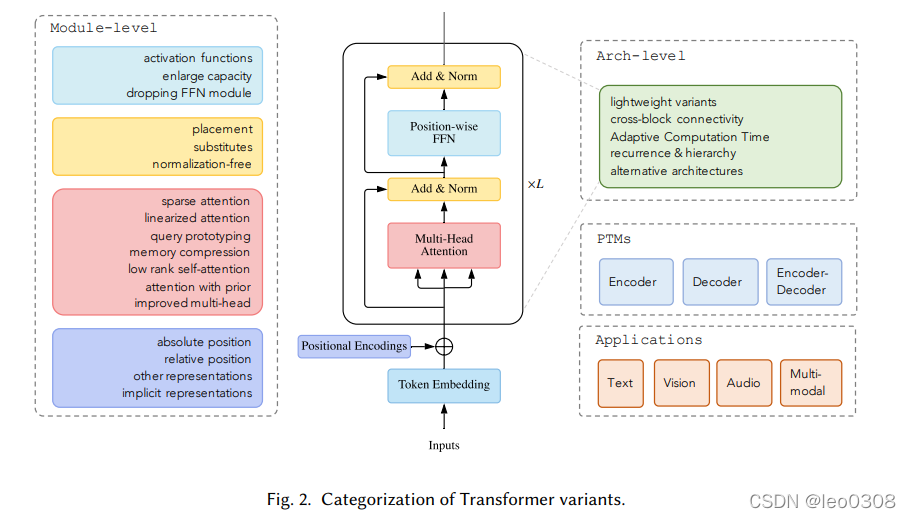 上图是总体的分类。
上图是总体的分类。
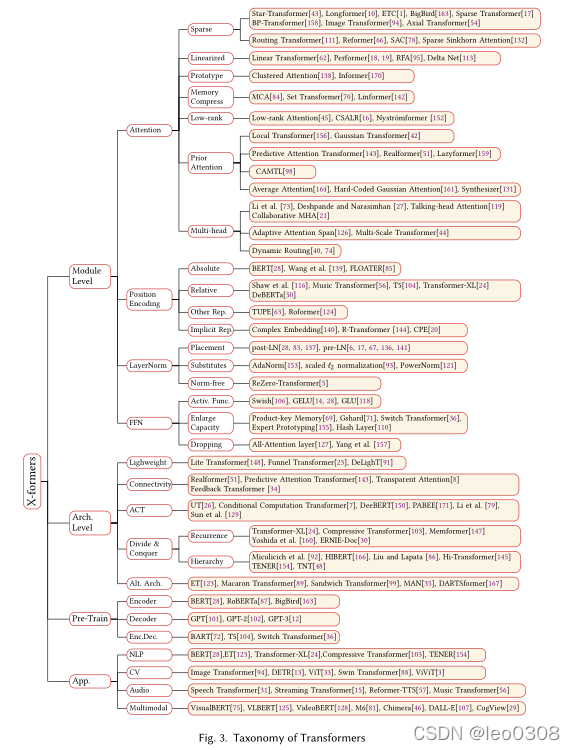
上图列出了每个分类里面的相关工作, 可以作为一份学习指南。
1 模型结构的优化
1.1 模块级的优化
1.1.1 注意力机制
Attention优化的相关工作是最多的。 这也很好理解, 因为Transformer中最核心的模块就是Attention了。 Attention机制虽然很成功, 但存在一个很大的问题, 就是计算复杂度很高, 其复杂度为
O
(
T
2
)
O(T^2)
O(T2), 其中T是输入序列的长度。 这对长序列是非常不友好的。
关于复杂度可参考下表:

可以看到, 当序列长度比较短的时候, 计算量主要在FFN, 当序列比较长的时候, 计算量主要在Attention. 关于Attention优化的工作基本都是致力于减少Attention的计算量和存储。
1.1.1.1 稀疏Attention
本质上来讲, 稀疏Attention利用了这样一个事实, 虽然Attention的机制是可以关注全局的, 但实际上通常只需关注到部分特定的信息即可。举个例子, 翻译一句话的时候, 对其中的某一个字, 可能只有部分其他字的信息是有用的, 绝大多数字的信息都是不需要的。
稀疏Attention的方式有很多种, 按不同的粒度又可细分为: 1)原子稀疏注意力, 2) 复合稀疏注意力,3)扩展稀疏注意力。 每类又有很多不同方法, 这里不详细展开。
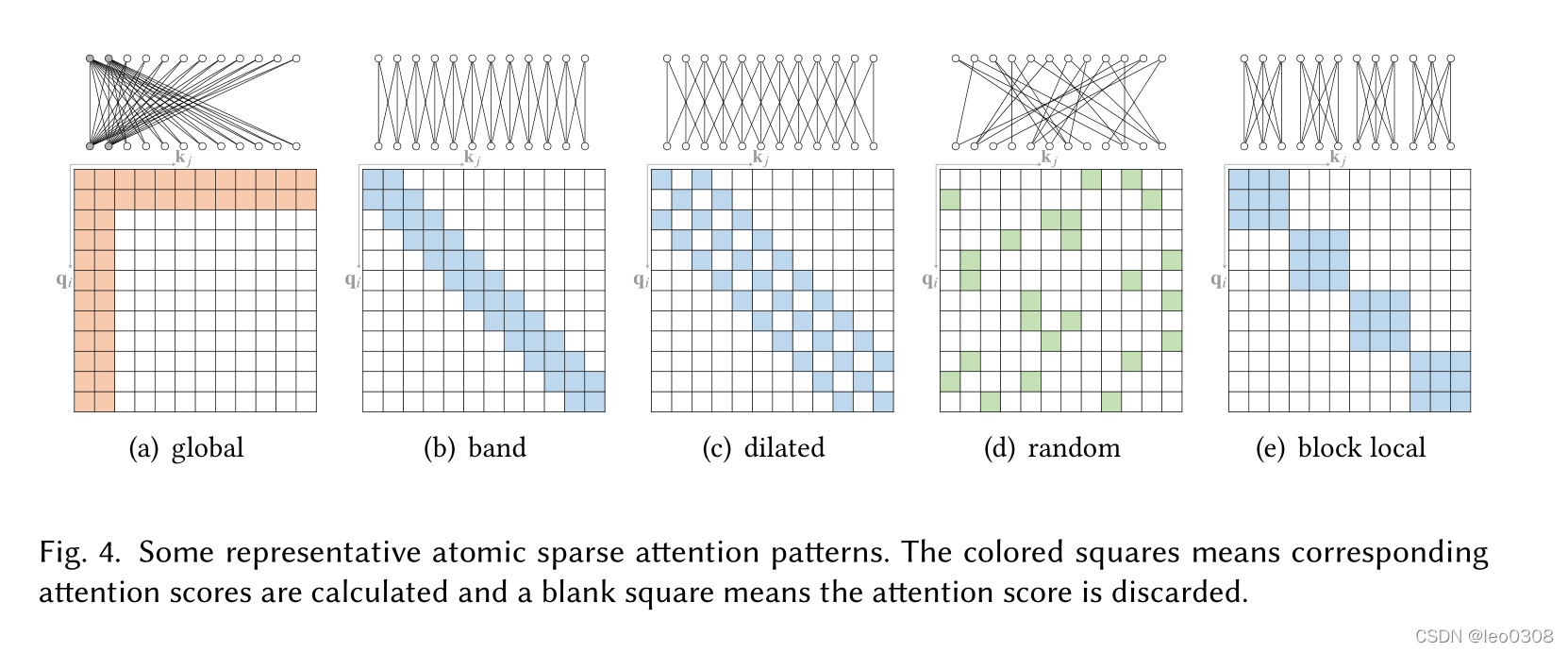
下面看图说话, 其实看图就能大概知道不同的方法都主要做了什么工作。
下图是一些原子稀疏注意力方法, 不同方法就是就用不同的方式让Attention只关注局部的一些信息。
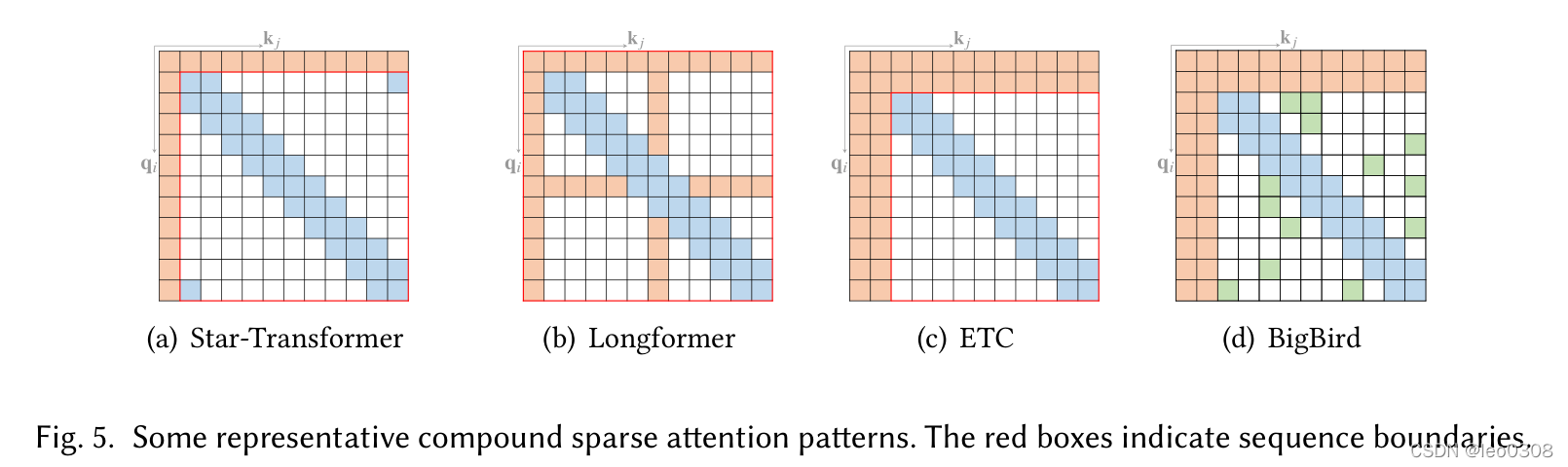
下图是一些复合稀疏Attention, 其实所谓复合就是融合使用了上面介绍的多种原子稀疏Attention。
下面是一些扩展的稀疏Attention, 就是用一些其他方法去进行稀疏处理。
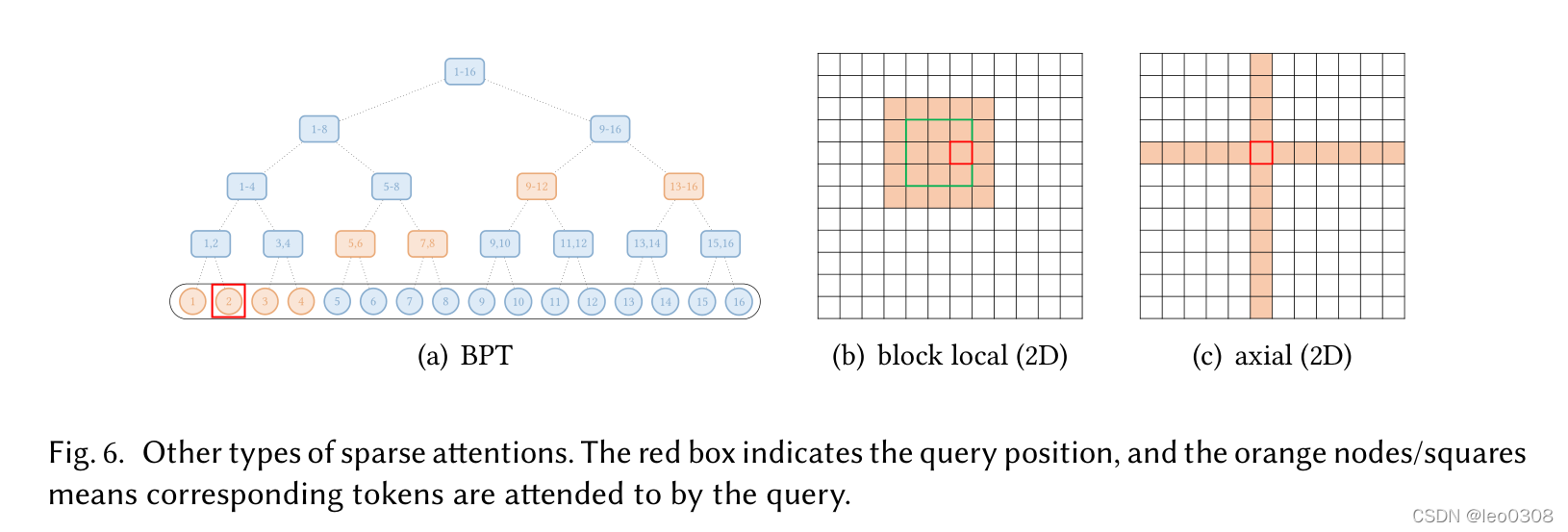
1.1.1.2 线性Attention
线性Attention是为了解决上面提到的Attention的计算是平方复杂度的问题,致力于把平方的复杂度降为线性复杂度。 这里面的方法不多, 且理论比较复杂。
推荐一个比较值得关注的工作: Linformer: Self-Attention with Linear Complexity
关于这篇工作, 我会专门写一篇博客进行介绍。
1.1.1.3 查询原型和内存压缩
1.1.1.4 低秩自注意力
1.1.1.5 先验的注意力
1.1.1.6 改进的多头机制
1.1.2 位置表示
1.1.2.1 绝对位置表示
1.1.2.2 相对位置表示
1.1.2.3 其他表示
1.1.3 层归一化
1.1.3.1 layernorm的位置
原版的Transformer将layernorm放在残差块之间, 这种方式称为post-LN, 后来的一些研究将layernorm放在Attention和FFN之前, 残差块的内部, 并在最后一层额外添加一个layernorn控制输出的幅度, 这种方式称为pre-LN。
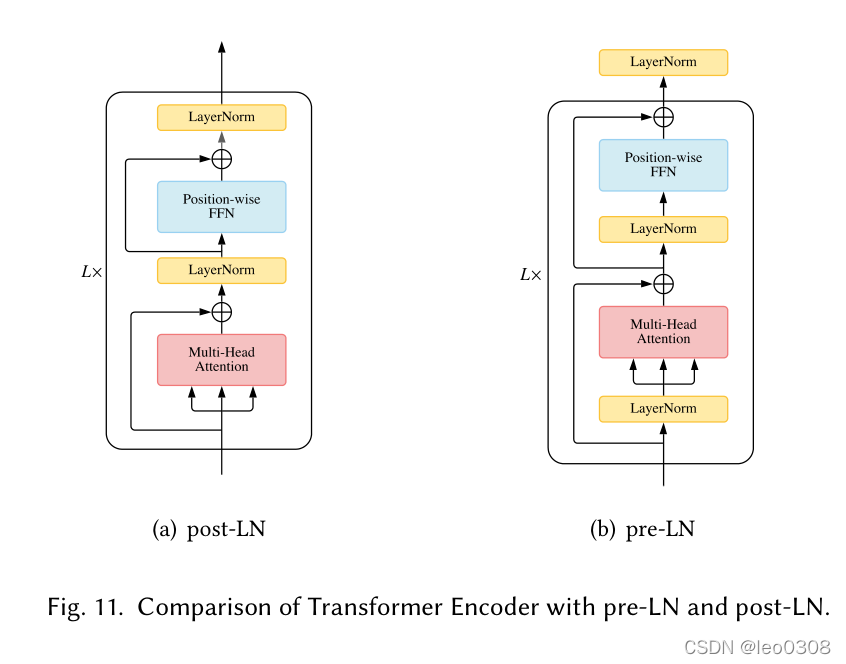
这2种方式孰优孰劣没有定论, 一些研究发现了post-LN在输出层附近的梯度会很大, 因此如果不用warn-up会导致训练的不稳定, 而pre-LN方式则不需要warm-up。 然而另一些研究得出了不同的结论。
尽管post-LN方式可能会导致训练不稳定甚至不收敛, 但是当它收敛之后的效果通常好于pre-LN。
当前很多实现中采用了pre-LN方式。
1.1.3.2 layernorm的替代
1.1.3.3 不使用layernorm的Transformer
1.1.4 前馈神经网络
1.2 整体结构的优化
1.2.1 轻量化
1.2.2 加强跨block的连接
1.2.3 自适应计算时间
1.2.4 分治策略的Transformer
1.2.5 探索替代架构
2 预训练模型
Transformer 不对数据做任何先验的假设, 这一方面使得Transformer可以非常通用, 另一方面也使得Transformer在小数据上会过拟合。 最近的研究表明, 在大型预料上预训练的Transformer可以学到对下游任务有益的通用语言表示。预训练模型的做法通常是在大型预料库(如wiki等)上进行自监督训练,训练好的模型在应用到下游任务上时只需要进行fine-tune.
2.1 只使用Encoder
这类预训练模型通常用于判别式任务, 如分类,把Transformer的Encoder部分作为网络的backbone, 进行特征的提取, 然后在接上具体任务的头。 典型的代表是Bert网络。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2.2 只使用Decoder
这类预训练模型通常应用于生成式任务中,典型代表是GPT系列。
2.3 Encoder和Decoder都使用
典型代表有BART和T5等。
3 Transformer的应用
3.1 NLP
机器翻译:
语言模型:
命名实体识别:
3.2 CV
图像分类:
目标检测:
图像生成:
视频处理:
3.3 音频处理
语音识别:
语音分析:
语音增强:
音乐生成:
3.4 多模态
视觉问答:
视觉常识推理:
字幕生成:
语音到文本翻译:
文本到图像生成:
4 总结和未来方向
1 理论分析。 尽管Transformer的强大已经被验证, 但仍需要从理论上证明为什么Transformer表现这么好。
2 超越注意力的的全局交互机制。 Transformer的一个主要优势就是利用注意力机制去建模输入数据的全局依赖, 然而很多研究表明对大部分节点来说, 完全的注意力是不必要的。 因此全局交互机制还有改进空间。
3 多模态数据统一框架。Transformer在文本, 图像, 音频, 视频等领域取得了巨大的成功, 我们有机会去建立统一的框架去更好地刻画不同模态数据之间的内在联系。 然而同一模态内部,以及模态之间的注意力有待改进。
5 参考
[1] https://zhuanlan.zhihu.com/p/379510627 复旦大学邱锡鹏教授团队:Transformer最新综述

















 2288
2288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









