






一、Vit模型介绍
Vit(Vision Transformer)即将Transformer应用于视觉领域。
Transformer输入输出都是一个序列,若需要应用于视觉领域,则需要考虑如何将一个2d图片转化为一个1d的序列,最直观的想法将图片中的像素点输入到transformer中,模型训练中图片的大小是224*224=50176,而正常的bert的序列长度是512,复杂度太高。
1.Vit在输入序列长度的改进
(1)使用网络中间的特征图
用res50最后一个stage res4的feature map size只有14*14=196,序列长度是满足预期的
(2)孤立自注意力
使用local window而不是整张图,输入的序列长度可以由windows size来控制
(3)轴自注意力
将在2d图片上的自注意力操作改为分别在图片的该和宽两个维度上做self-attention,可以大大降低复杂度,但是由于目前硬件没有对这种操作做加速,很难支持大规模的数据量级。
当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。
2.Vit的缺点
(1)如果出现了一张图,其中包含模型从来没见过的类别,那么模型就不能输出正确的结果
(2)如果输入数据出现了分布偏移,那么模型可能也无法输出正确的结果
二、CLIP模型介绍
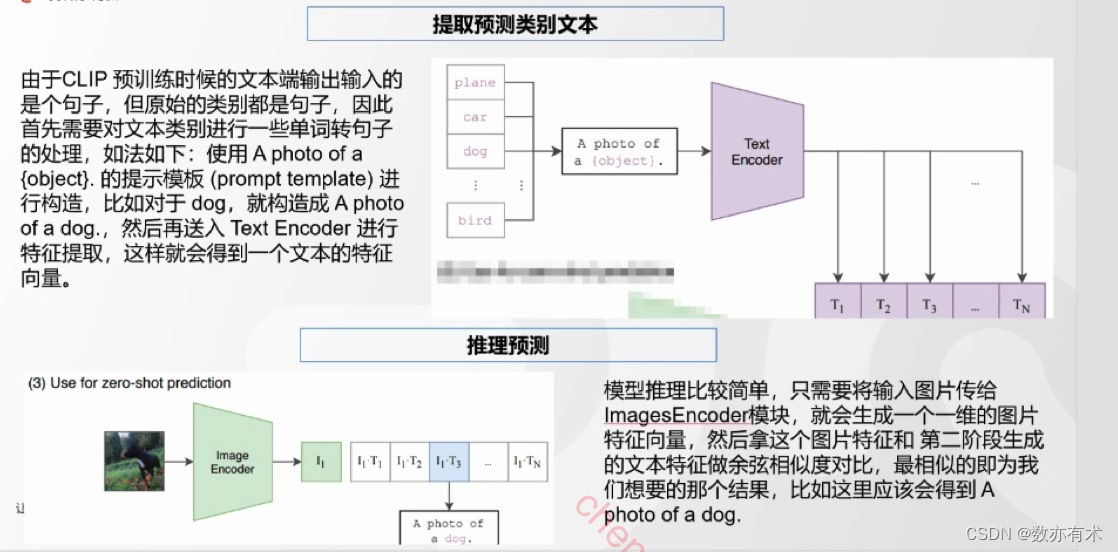
CLIP(Contrastive Language-Image Pre-training)由两个主体部分组成:Text Encoder和Image Encode——文本和图像的特征提取器。
CLIP预训练方法:对比学习
三、Vision-Language Model模型介绍
- 预训练阶段(PreTraining):通常是为了实现视觉特征与文本特征的堆砌,有些模型的这一阶段也会分为两个子阶段,比如针对弱标签数据训练和人工标注训练,或者在训练中增加图片分辨率等
- 微调阶段(Finetune):此阶段通常是使用指令或特定任务数据进行微调,以增强模型遵循指令能力和对话能力等,有些也会分为两个子阶段
四、Flamingo
Flamingo:a Visual Language Model for Few-Shot Learning

五、BLIP模型介绍


















 6114
6114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









