







- 基本概念(Cluster Analysis)
- “物以类聚”
- 分析方法
- 系统聚类
- 快速聚类
- 类型
- Q型聚类:对 样品 的聚类
- R型聚类:对 变量 的聚类
- 聚类统计量
- 距离
- 欧氏距离
- 马氏距离
- 兰式距离
-
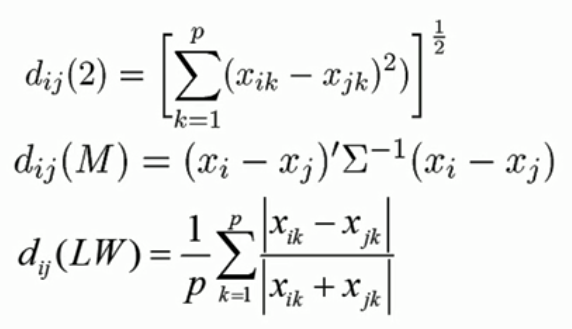
- 相关系数
-
- 距离矩阵
- 相关矩阵
- 距离矩阵计算——dist(),cor()
- 距离
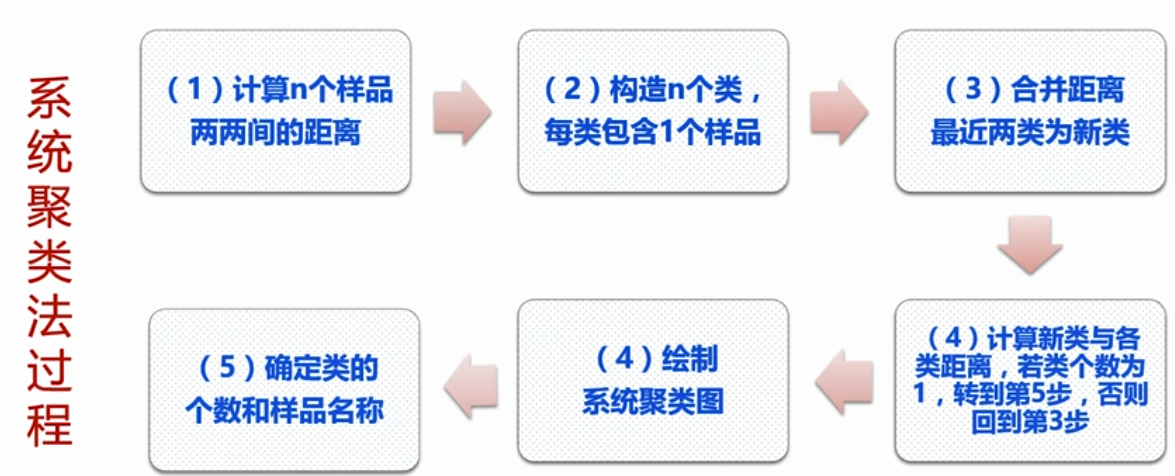
- 系统聚类法
- 基本思想:先将样品分成类,每个样品为一类,然后每次将具有最小距离的两类合并,合并后重新计算类与类之间的距离,直到所有样品归为一类为止
- 类间距离 的计算方法
- 最短距离法(single)
- 最长距离法(complete)
- 中间距离法(median)
- 类平均法(avera)
- 重心法(centroid)
- 离差平方和法(Ward)
- 通用公式
- hclust(D,method=)
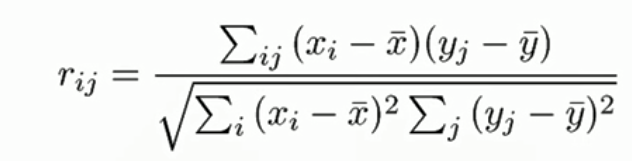
- 快速聚类法kmeans
- 概念:基本思想是将每一个样品分配给最近中心(均值)的类中
- 原理:n个对象分k类,类内 相似度 高,类间相似度低
- 相似度:类中对象的均值mean来计算
- kmeans(x,centers)
- 不足:只有在类均值被定义的情况下才能使用,对孤立点、噪声影响敏感
- knn,kmed,中位数
- 变量变换
- 平移变换
- 极差变换
- 标准差变换
- 主成分
- 对数
x1=c(2.5,3.0,6.0,6.6,7.2,4.0,4.7,4.5,5.5)
x2=c(2.1,2.5,2.5,1.5,3.0,6.4,5.6,7.6,6.9)
X=data.frame(x1,x2)
D=dist(X,diag = TRUE,upper = FALSE)
hc=hclust(D,"complete")
hc
names(hc)
hc$merge
hc$height
#系统聚类图
plot(hc)
rect.hclust(hc,3)
#显示分类步骤
cutree(hc,9:1)
#系统聚类分析步骤
library(mvstats)
d7.2=read.table('clipboard',header = T)
X7.2=msa.X(d7.2)
plot(d7.2,gap=0)
D=dist(d7.2)
D
H=H.clust(d7.2,"euclidean","single",plot=T)#最短距离法
H.clust(d7.2,"euclidean","complete",plot=T)#最长距离法
H.clust(d7.2,"euclidean","median",plot=T)#中间距离法
H.clust(d7.2,"euclidean","average",plot=T)#类平均法
H.clust(d7.2,"euclidean","centroid",plot=T)#重心法
H.clust(d7.2,"euclidean","ward",plot=T)#ward
cutree(H,3)
#快速聚类法
set.seed(123)
x1=matrix(rnorm(1000,0,0.3))
x2=matrix(rnorm(1000,1,0.3))
X=rbind(x1,x2)
H=hclust(dist(X))
plot(H)
km=kmeans(X,2)
km$cluster
plot(X,pch=km$cluster)
#10变量2000样品
set.seed(123)
x1=matrix(rnorm(10000,0,0.3),ncol = 10)
x2=matrix(rnorm(10000,1,0.3),ncol = 10)
Y=rbind(x1,x2)
km=kmeans(Y,2)
km$cluster
plot(Y,pch=km$cluster)
km















 2157
2157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









