







简介
在不断发展的自然语言处理领域,大型语言模型(LLM)已成为各种应用不可或缺的工具。今天,我们将深入探讨 Sarashina2-8x70B 的世界,这是 SB Intuitions 开发的一款出色的 LLM。该模型拥有大量参数(465B)和创新的训练技术,有望彻底改变语言理解和生成任务。
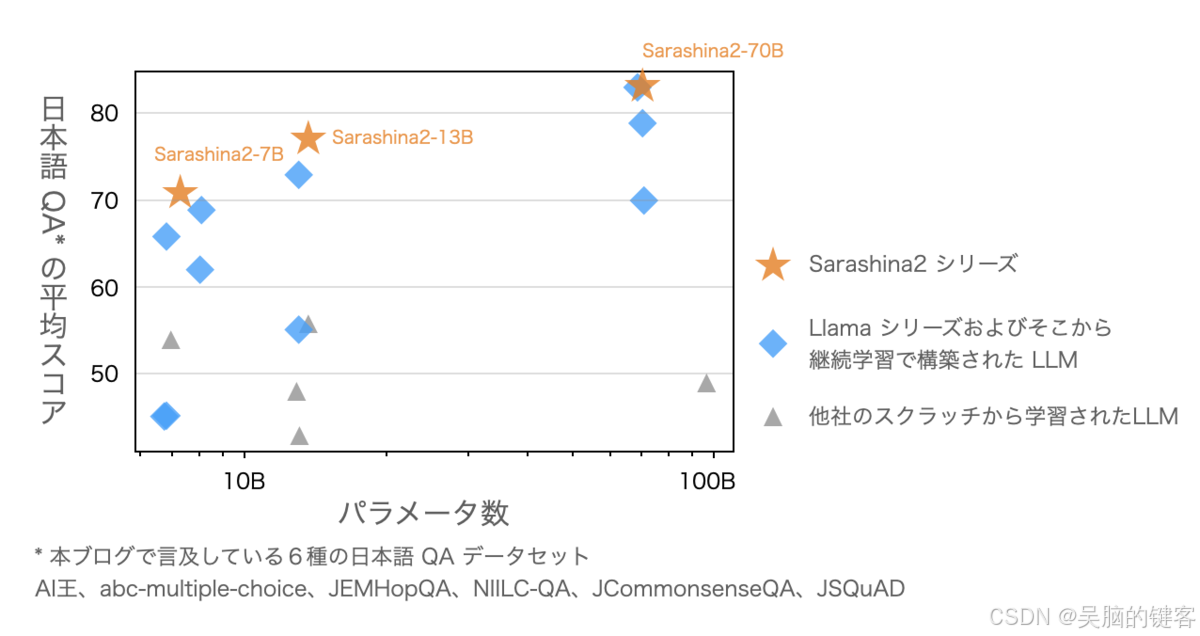
模型概述
Sarashina2-8x70B是最先进的 LLM,拥有超过 4500 亿个参数。它是 Sarashina2-70B 模型的扩展,该模型使用稀疏上循环技术进行了上循环,详见论文 “Sparse Upcycling:Efficiently Building Mixture-of-Experts Models” (arxiv: 2212.05055) 一文中所述。这项技术可以高效地构建专家混合物模型,从而增强模型的功能。
config.json
{
"architectures": [
"MixtralForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 1,
"eos_token_id": 2,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"model_type": "mixtral",
"num_attention_heads": 64,
"num_experts_per_tok": 2,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"num_local_experts": 8,
"output_router_logits": false,
"rms_norm_eps": 1e-05,
"rope_theta": 10000,
"router_aux_loss_coef": 0.001,
"router_jitter_noise": 0.0,
"sliding_window": null,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.40.1",
"use_cache": true,
"vocab_size": 102400
}
可以看到他们使用的是 Mixtral 的架构
训练数据和硬件
该模型使用了从网络数据中获取的日语和英语语料进行训练。这种双语言训练方法使 Sarashina2-8x70B 具备了理解和生成两种语言文本的能力,成为多语言应用的宝贵资产。
要训练这个庞大的模型,需要大量的硬件资源。对于 BF16 推理,推荐的设置包括 16x H100 或 16x A100 80GB GPU,以确保高效和有效的模型训练。
标记化
Sarashina2-8x70B 采用了带有 unigram 语言模型和字节回调的句子标记化器。这种标记器不需要使用日语标记器进行预标记,允许用户直接输入原始句子。这种灵活性简化了模型与各种应用程序的集成。
伦理考虑因素和限制
必须注意的是,Sarashina2 并未根据指令进行微调,这可能会导致生成无意义的序列、不准确的实例或有偏见/令人反感的输出。SB Intuitions 鼓励开发人员在部署前根据人类偏好和安全考虑对模型进行调整。
结论
Sarashina2-8x70B是自然语言处理领域的杰出成就,为日语和英语任务提供了强大的工具。其庞大的参数数量、创新的训练技术和双语言功能使其成为研究人员、开发人员和企业的宝贵资源。不过,用户应注意其局限性,并确保负责任地使用。
如需了解更多信息,请访问 Hugging Face 上的模型库,浏览模型卡片、文件和社区讨论。
https://www.sbintuitions.co.jp/
https://huggingface.co/sbintuitions
https://huggingface.co/sbintuitions/sarashina2-8x70b
感谢大家花时间阅读我的文章,你们的支持是我不断前进的动力。点赞并关注,获取最新科技动态,不落伍!🤗🤗🤗

















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









