








简介
Sana 是一个文本到图像的框架,能高效生成分辨率高达 4096 x 4096 的图像。它能以极快的速度合成高分辨率、高质量的图像,并具有很强的文本图像对齐能力,可部署在笔记本电脑的 GPU 上。

核心设计
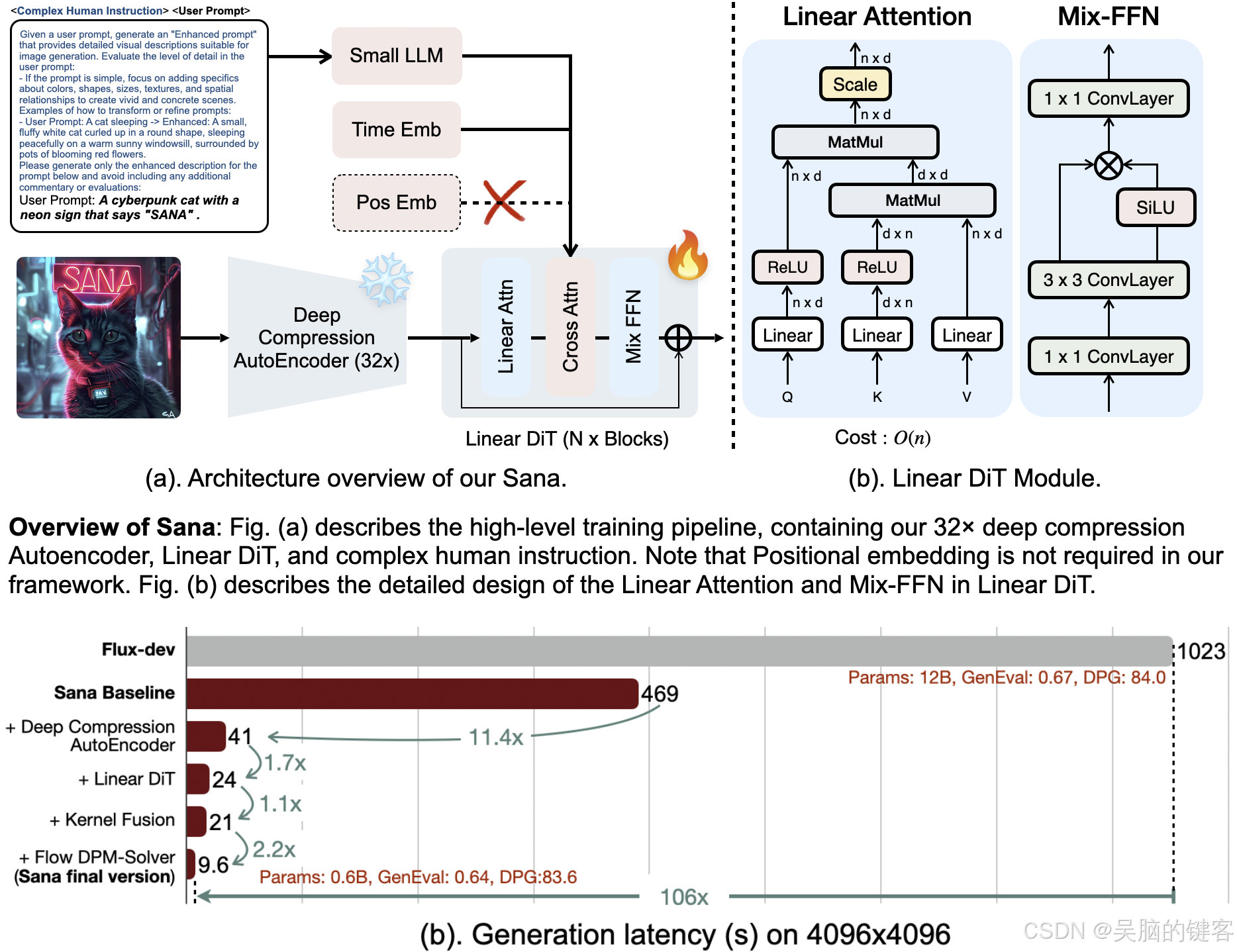
DC-AE
与只能将图像压缩 8 倍的传统 AE 不同,Sana 训练的 AE 可将图像压缩 32 倍,从而有效减少潜在标记的数量。
线性 DiT
萨纳用线性注意力取代了 DiT 中的所有虚无注意力,这种注意力在高分辨率下效率更高,而且不会降低质量。
纯解码器文本编码器
Sana 使用现代的纯解码器小型 LLM 作为文本编码器,取代了 T5,并设计了具有上下文学习功能的复杂人工指令,以增强图像与文本的对齐。
高效的训练和采样
Sana 提出了 Flow-DPM-Solver 来减少采样步骤,并通过高效的标题标注和选择来加速收敛。
性能
Sana-0.6B 与现代巨型扩散模型(如 Flux-12B)相比具有很强的竞争力,体积小 20 倍,测量吞吐量快 100 多倍。它可以部署在 16GB 的笔记本电脑 GPU 上,生成 1024 x 1024 分辨率图像的时间不到 1 秒。Sana 能够以低成本创建内容。
| Methods (1024x1024) | Throughput (samples/s) | Latency (s) | Params (B) | Speedup | FID 👆 | CLIP 👆 | GenEval 👆 | DPG 👆 |
|---|---|---|---|---|---|---|---|---|
| FLUX-dev | 0.04 | 23.0 | 12.0 | 1.0× | 10.15 | 27.47 | 0.67 | 84.0 |
| Sana-0.6B | 1.7 | 0.9 | 0.6 | 39.5× | 5.81 | 28.36 | 0.64 | 83.6 |
| Sana-1.6B | 1.0 | 1.2 | 1.6 | 23.3× | 5.76 | 28.67 | 0.66 | 84.8 |
依赖和安装
Python >= 3.10.0(建议使用 Anaconda 或 Miniconda)
PyTorch >= 2.0.1+cu12.1
💻如何玩转 Sana(推理)
💰硬件要求
0.6B 模型需要 9GB 内存,1.6B 模型需要 12GB 内存。
所有测试均在 A100 GPU 上完成。不同版本的 GPU 可能会有所不同。
🔛 官方在线演示
DEMO_PORT=15432 \
python app/app_sana.py \
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth
import torch
from app.sana_pipeline import SanaPipeline
from torchvision.utils import save_image
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
generator = torch.Generator(device=device).manual_seed(42)
sana = SanaPipeline("configs/sana_config/1024ms/Sana_1600M_img1024.yaml")
sana.from_pretrained("hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth")
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = sana(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=5.0,
pag_guidance_scale=2.0,
num_inference_steps=18,
generator=generator,
)
save_image(image, 'output/sana.png', nrow=1, normalize=True, value_range=(-1, 1))
🔛 使用 TXT 或 JSON 文件运行推理
# Run samples in a txt file
python scripts/inference.py \
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth
--txt_file=asset/samples_mini.txt
# Run samples in a json file
python scripts/inference.py \
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth
--json_file=asset/samples_mini.json
🔥如何训练Sana
💰硬件要求
0.6B和1.6B模型的训练都需要32GB VRAM
我们在这里提供了一个训练示例,您也可以根据自己的数据结构从配置文件目录中选择所需的配置文件。
要启动Sana培训,首先需要准备以下格式的数据
asset/example_data
├── AAA.txt
├── AAA.png
├── BCC.txt
├── BCC.png
├── ......
├── CCC.txt
└── CCC.png
然后,Sana的培训可以通过以下方式启动
# Example of training Sana 0.6B with 512x512 resolution
bash train_scripts/train.sh \
configs/sana_config/512ms/Sana_600M_img512.yaml \
--data.data_dir="[asset/example_data]" \
--data.type=SanaImgDataset \
--model.multi_scale=false \
--train.train_batch_size=32
# Example of training Sana 1.6B with 1024x1024 resolution
bash train_scripts/train.sh \
configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--data.data_dir="[asset/example_data]" \
--data.type=SanaImgDataset \
--model.multi_scale=false \
--train.train_batch_size=8
🤗致谢
感谢 PixArt-α、PixArt-Σ 和 Efficient-ViT 的出色工作和代码库!
https://github.com/NVlabs/Sana
https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px
https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px
感谢大家花时间阅读我的文章,你们的支持是我不断前进的动力。点赞并关注,获取最新科技动态,不落伍!🤗🤗🤗


















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









