







近日,字节跳动发布了名为 LatentSync 的新型口型同步框架,旨在利用音频条件潜在扩散模型实现更精确的口型同步。该框架基于Stable Diffusion,针对时间一致性做了优化。
与以往的基于像素空间扩散或两阶段生成的方法不同,LatentSync 采用端到端的方式,无需中间运动表示,能够直接建模复杂的音频与视觉之间的关系。
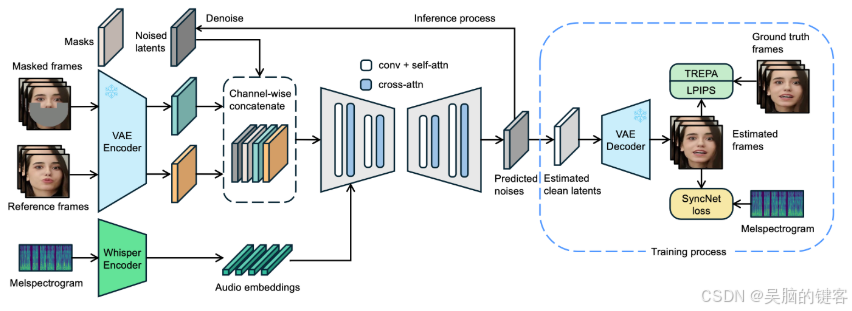
在 LatentSync 的框架中,首先使用 Whisper 将音频频谱图转换为音频嵌入,并通过交叉注意力层将其集成到 U-Net 模型中。框架通过将参考帧和掩码帧与噪声潜在变量进行通道级拼接,作为 U-Net 的输入。
在训练过程中,采用一步法从预测噪声中估计出干净的潜在变量,然后进行解码以生成干净的帧。同时,模型引入了 Temporal REPresentation Alignment(TREPA)机制,以增强时间一致性,确保生成的视频在口型同步准确性的同时,能够在时间上保持连贯。
为了展示该技术的效果,项目提供了一系列示例视频,分别展示了原始视频与经过口型同步处理后的视频。通过示例,用户可以直观地感受到 LatentSync 在视频口型同步方面的显著进步。
此外,项目还计划开源推理代码和检查点,方便用户进行训练和测试。对于想要尝试推理的用户,只需下载必要的模型权重文件,即可进行操作。完整的数据处理流程也已设计好,涵盖了从视频文件处理到面部对齐的各个步骤,确保用户能够轻松上手。
模型项目入口:https://github.com/bytedance/LatentSync
追加
模型要是用whisper large v3 就 perfect 了
Colab T4
下载代码
!git clone https://github.com/bytedance/LatentSync.git
部署环境
!pip install -q condacolab
import condacolab
condacolab.install()
import condacolab
condacolab.check()
!cd LatentSync && source setup_env.sh
推理
%%bash
source /usr/local/envs/latentsync
cd LatentSync && ./inference.sh

















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









