







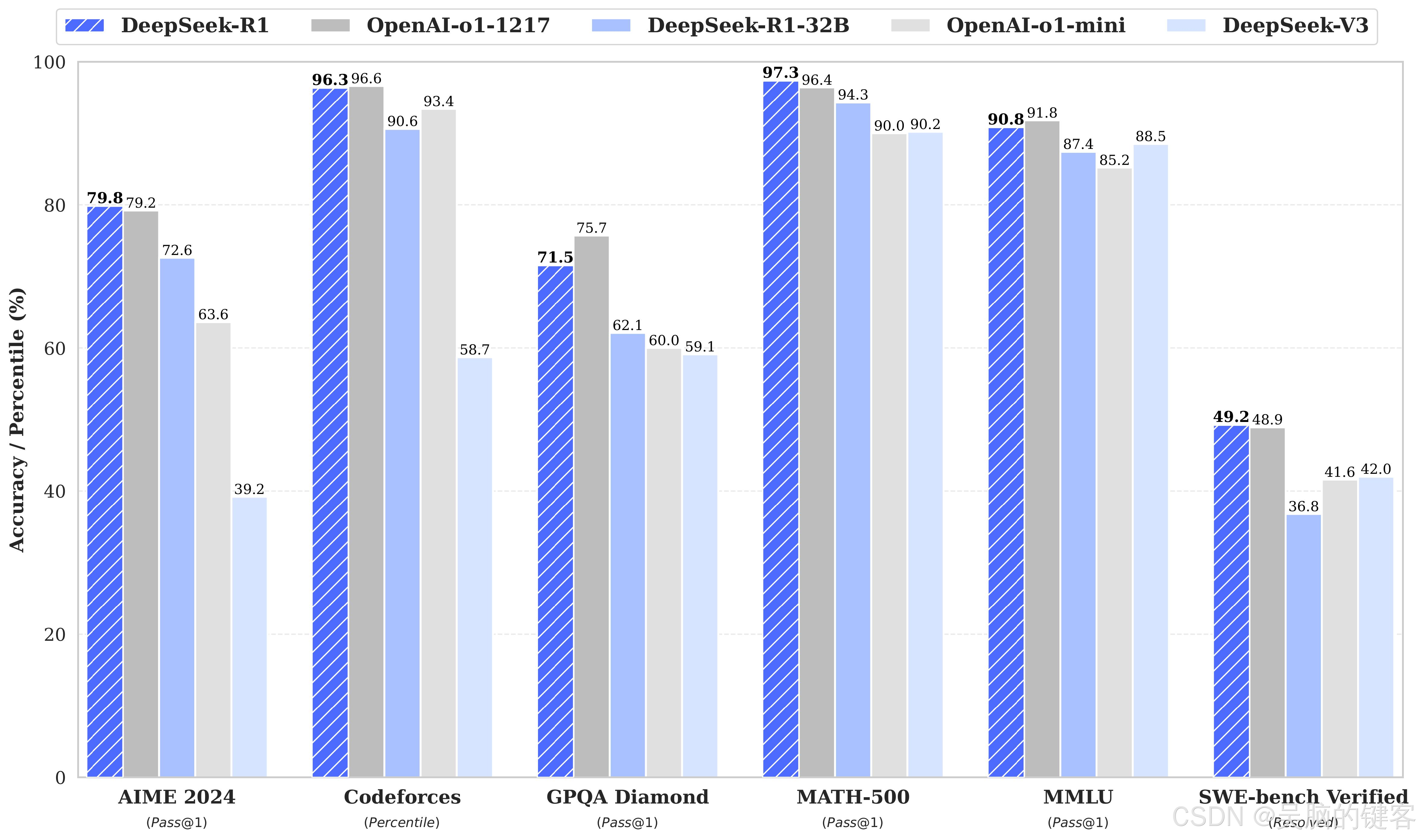
我们介绍了第一代推理模型DeepSeek-R1-Zero和DeepSeek-R1。 DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练出来的模型,在没有监督微调(SFT)作为初始步骤的情况下,它在推理方面表现出了卓越的性能。 有了 RL,DeepSeek-R1-Zero 自然而然地出现了许多强大而有趣的推理行为。 然而,DeepSeek-R1-Zero也遇到了一些挑战,如无休止的重复、可读性差和语言混杂等。 为了解决这些问题并进一步提高推理性能,我们引入了DeepSeek-R1,它在RL之前加入了冷启动数据。 在数学、代码和推理任务方面,DeepSeek-R1的性能与OpenAI-o1相当。 为了支持研究社区,我们开源了DeepSeek-R1-Zero、DeepSeek-R1以及基于Llama和Qwen从DeepSeek-R1提炼出的六个密集模型。 在各种基准测试中,DeepSeek-R1-Distill-Qwen-32B的表现都优于OpenAI-o1-mini,在密集模型方面取得了新的先进成果。
https://huggingface.co/collections/deepseek-ai/deepseek-r1-678e1e131c0169c0bc89728d
模型概要
后期训练: 基础模型的大规模强化学习
- 我们直接将强化学习(RL)应用于基础模型,而不依赖于作为初步步骤的监督微调(SFT)。 这种方法允许模型探索解决复杂问题的思维链(CoT),从而开发出 DeepSeek-R1-Zero。 DeepSeek-R1-Zero 展示了自我验证、反思和生成长 CoT 等能力,为研究界树立了一个重要的里程碑。 值得注意的是,这是第一项公开研究,验证了 LLM 的推理能力可以纯粹通过 RL 来激励,而无需 SFT。 这一突破为这一领域未来的发展铺平了道路。
- 我们介绍了开发DeepSeek-R1的流程。 该流程包括两个 RL 阶段,旨在发现改进的推理模式并与人类偏好保持一致;以及两个 SFT 阶段,作为模型推理和非推理能力的种子。 我们相信,通过创建更好的模型,该管道将使整个行业受益。
蒸馏: 较小的型号也可以很强大
- 我们证明,大型模型的推理模式可以被提炼到较小的模型中,从而比在小型模型上通过 RL 发现的推理模式具有更好的性能。 开源的 DeepSeek-R1 及其应用程序接口将有助于研究界在未来提炼出更好的小型模型。
- 利用 DeepSeek-R1 生成的推理数据,我们对研究界广泛使用的几个密集模型进行了微调。 评估结果表明,经过提炼的小型密集模型在基准测试中表现优异。 我们向社区开源了基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B 检查点。
模型下载
DeepSeek-R1 Models
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | 🤗 HuggingFace |
| DeepSeek-R1 | 671B | 37B | 128K | 🤗 HuggingFace |
DeepSeek-R1-Zero 和 DeepSeek-R1 基于 DeepSeek-V3-Base 训练。 有关模型架构的更多详情,请参阅 DeepSeek-V3 存储库。
DeepSeek-R1-Distill Models
| Model | Base Model | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 🤗 HuggingFace |
评估结果
DeepSeek-R1 评估
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|---|---|---|---|---|---|---|---|
| Architecture | - | - | MoE | - | - | MoE | |
| # Activated Params | - | - | 37B | - | - | 37B | |
| # Total Params | - | - | 671B | - | - | 671B | |
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | 91.8 | 90.8 |
| MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | 92.9 | |
| MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | 84.0 | |
| DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | 92.2 | |
| IF-Eval (Prompt Strict) | 86.5 | 84.3 | 86.1 | 84.8 | - | 83.3 | |
| GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | 75.7 | 71.5 | |
| SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | 47.0 | 30.1 | |
| FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | 82.5 | |
| AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | 87.6 | |
| ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | 92.3 | |
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | - | 53.8 | 63.4 | 65.9 |
| Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 | |
| Codeforces (Rating) | 717 | 759 | 1134 | 1820 | 2061 | 2029 | |
| SWE Verified (Resolved) | 50.8 | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 | |
| Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | 61.7 | 53.3 | |
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 | |
| CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | 78.8 | |
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | 92.8 |
| C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | 91.8 | |
| C-SimpleQA (Correct) | 55.4 | 58.7 | 68.0 | 40.3 | - | 63.7 |
蒸馏模型评估
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|---|---|---|---|---|---|---|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633 |
聊天网站和API平台
您可以在DeepSeek的官方网站:chat.deepseek.com上与DeepSeek-R1聊天,并点击 "DeepThink "按钮 我们还在DeepSeek平台上提供了与OpenAI兼容的API:platform.deepseek.com
如何在本地运行
DeepSeek-R1 模型
有关在本地运行 DeepSeek-R1 的更多信息,请访问 DeepSeek-V3 repo。
DeepSeek-R1-Distill 模型
DeepSeek-R1-Distill 模型的使用方式与 Qwen 或 Llama 模型相同。
例如,你可以使用 vLLM 轻松启动服务:
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
注意:我们建议在运行这些模型时设置适当的 temperature (0.5 至 0.7 之间),否则可能会出现无休止重复或输出不连贯的问题。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









