







2025 年 2 月 21 日,阿里巴巴国际化团队宣布其新型多模态大语言模型Ovis2 系列正式开源。
Ovis2 是阿里巴巴国际化团队提出的Ovis系列模型的最新版本。与前序1. 6 版本相比,Ovis2 在数据构造和训练方法上都有显著改进。它不仅强化了小规模模型的能力密度,还通过指令微调和偏好学习大幅提升了思维链(CoT)推理能力。此外,Ovis2 引入了视频和多图像处理能力,并增强了多语言能力和复杂场景下的OCR能力,显著提升了模型的实用性。
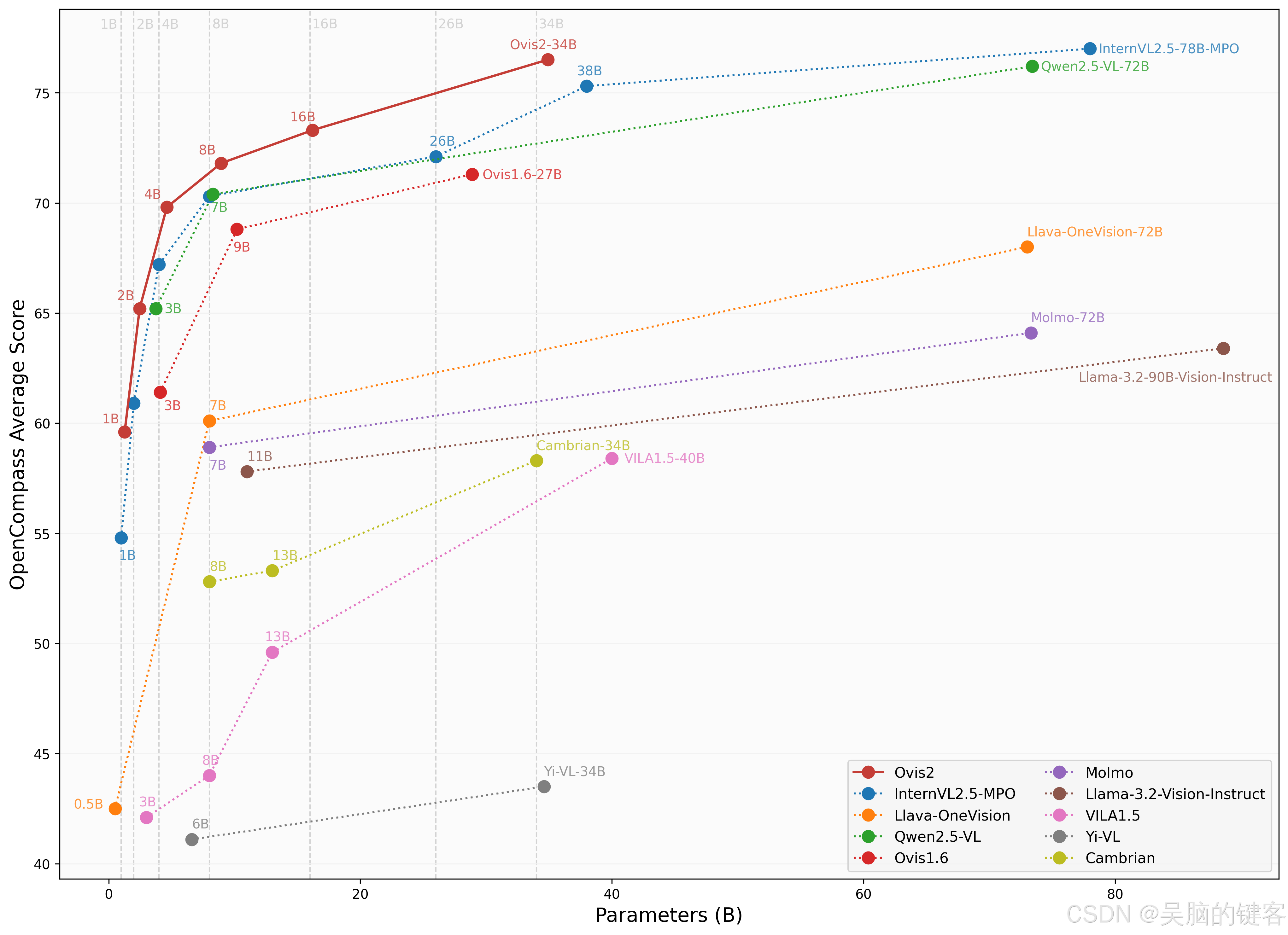
此次开源的Ovis2 系列包括1B、2B、4B、8B、16B和34B六个版本,各个参数版本均达到了同尺寸的SOTA(State of the Art)水平。其中,Ovis2-34B在权威评测榜单OpenCompass上展现出了卓越的性能。在多模态通用能力榜单上,Ovis2-34B位列所有开源模型第二,以不到一半的参数尺寸超过了诸多70B开源旗舰模型。在多模态数学推理榜单上,Ovis2-34B更是位列所有开源模型第一,其他尺寸版本也展现出出色的推理能力。这些成绩不仅证明了Ovis架构的有效性,也展示了开源社区在推动多模态大模型发展方面的巨大潜力。
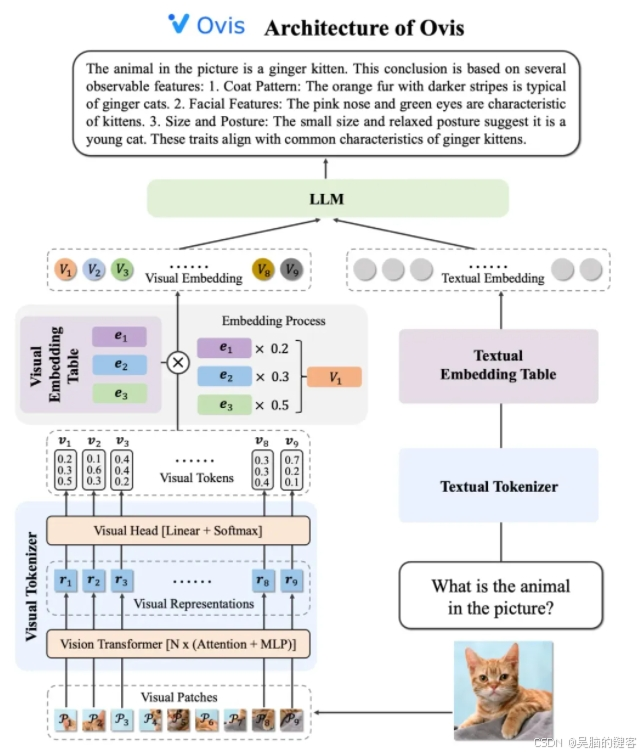
Ovis2 的架构设计巧妙地解决了模态间嵌入策略差异这一局限性。它由视觉tokenizer、视觉嵌入表和LLM三个关键组件构成。视觉tokenizer将输入图像分割成多个图像块,利用视觉Transformer提取特征,并通过视觉头层将特征匹配到“视觉单词”上,得到概率化的视觉token。视觉嵌入表存储每个视觉单词对应的嵌入向量,而LLM则将视觉嵌入向量与文本嵌入向量拼接后进行处理,生成文本输出,完成多模态任务。
在训练策略上,Ovis2 采用了四阶段训练方法,以充分激发其多模态理解能力。第一阶段冻结大部分LLM和ViT参数,训练视觉模块,学习视觉特征到嵌入的转化。第二阶段进一步增强视觉模块的特征提取能力,提升高分辨率图像理解、多语言和OCR能力。第三阶段通过对话形式的视觉Caption数据对齐视觉嵌入与LLM的对话格式。第四阶段则是多模态指令训练和偏好学习,进一步提升模型在多种模态下对用户指令的遵循能力和输出质量。
为了提升视频理解能力,Ovis2 开发了一种创新的关键帧选择算法。该算法基于帧与文本的相关性、帧之间的组合多样性和帧的序列性挑选最有用的视频帧。通过高维条件相似度计算、行列式点过程(DPP)和马尔可夫决策过程(MDP),算法能够在有限的视觉上下文中高效地选择关键帧,从而提升视频理解的性能。
Ovis2 系列模型在OpenCompass多模态评测榜单上的表现尤为突出。不同尺寸的模型在多个Benchmark上均取得了SOTA成绩。例如,Ovis2-34B在多模态通用能力和数学推理榜单上分别位列第二和第一,展现了其强大的性能。此外,Ovis2 在视频理解榜单上也取得了领先性能,进一步证明了其在多模态任务中的优势。
阿里巴巴国际化团队表示,开源是推动AI技术进步的关键力量。通过公开分享Ovis2 的研究成果,团队期待与全球开发者共同探索多模态大模型的前沿,并激发更多创新应用。目前,Ovis2 的代码已开源至GitHub,模型可在Hugging Face和Modelscope平台上获取,同时提供了在线Demo供用户体验。相关研究论文也已发布在arXiv上,供开发者和研究者参考。
我们使用 OpenCompass 多模态和推理排行榜中使用的 VLMEvalKit 来评估 Ovis2。
图像基准
| Benchmark | Qwen2.5-VL-3B | SAIL-VL-2B | InternVL2.5-2B-MPO | Ovis1.6-3B | InternVL2.5-1B-MPO | Ovis2-1B | Ovis2-2B |
|---|---|---|---|---|---|---|---|
| MMBench-V1.1test | 77.1 | 73.6 | 70.7 | 74.1 | 65.8 | 68.4 | 76.9 |
| MMStar | 56.5 | 56.5 | 54.9 | 52.0 | 49.5 | 52.1 | 56.7 |
| MMMUval | 51.4 | 44.1 | 44.6 | 46.7 | 40.3 | 36.1 | 45.6 |
| MathVistatestmini | 60.1 | 62.8 | 53.4 | 58.9 | 47.7 | 59.4 | 64.1 |
| HallusionBench | 48.7 | 45.9 | 40.7 | 43.8 | 34.8 | 45.2 | 50.2 |
| AI2D | 81.4 | 77.4 | 75.1 | 77.8 | 68.5 | 76.4 | 82.7 |
| OCRBench | 83.1 | 83.1 | 83.8 | 80.1 | 84.3 | 89.0 | 87.3 |
| MMVet | 63.2 | 44.2 | 64.2 | 57.6 | 47.2 | 50.0 | 58.3 |
| MMBenchtest | 78.6 | 77 | 72.8 | 76.6 | 67.9 | 70.2 | 78.9 |
| MMT-Benchval | 60.8 | 57.1 | 54.4 | 59.2 | 50.8 | 55.5 | 61.7 |
| RealWorldQA | 66.5 | 62 | 61.3 | 66.7 | 57 | 63.9 | 66.0 |
| BLINK | 48.4 | 46.4 | 43.8 | 43.8 | 41 | 44.0 | 47.9 |
| QBench | 74.4 | 72.8 | 69.8 | 75.8 | 63.3 | 71.3 | 76.2 |
| ABench | 75.5 | 74.5 | 71.1 | 75.2 | 67.5 | 71.3 | 76.6 |
| MTVQA | 24.9 | 20.2 | 22.6 | 21.1 | 21.7 | 23.7 | 25.6 |
| Benchmark | Qwen2.5-VL-7B | InternVL2.5-8B-MPO | MiniCPM-o-2.6 | Ovis1.6-9B | InternVL2.5-4B-MPO | Ovis2-4B | Ovis2-8B |
|---|---|---|---|---|---|---|---|
| MMBench-V1.1test | 82.6 | 82.0 | 80.6 | 80.5 | 77.8 | 81.4 | 83.6 |
| MMStar | 64.1 | 65.2 | 63.3 | 62.9 | 61 | 61.9 | 64.6 |
| MMMUval | 56.2 | 54.8 | 50.9 | 55 | 51.8 | 49.0 | 57.4 |
| MathVistatestmini | 65.8 | 67.9 | 73.3 | 67.3 | 64.1 | 69.6 | 71.8 |
| HallusionBench | 56.3 | 51.7 | 51.1 | 52.2 | 47.5 | 53.8 | 56.3 |
| AI2D | 84.1 | 84.5 | 86.1 | 84.4 | 81.5 | 85.7 | 86.6 |
| OCRBench | 87.7 | 88.2 | 88.9 | 83 | 87.9 | 91.1 | 89.1 |
| MMVet | 66.6 | 68.1 | 67.2 | 65 | 66 | 65.5 | 65.1 |
| MMBenchtest | 83.4 | 83.2 | 83.2 | 82.7 | 79.6 | 83.2 | 84.9 |
| MMT-Benchval | 62.7 | 62.5 | 62.3 | 64.9 | 61.6 | 65.2 | 66.6 |
| RealWorldQA | 68.8 | 71.1 | 68.0 | 70.7 | 64.4 | 71.1 | 72.5 |
| BLINK | 56.1 | 56.6 | 53.9 | 48.5 | 50.6 | 53.0 | 54.3 |
| QBench | 77.9 | 73.8 | 78.7 | 76.7 | 71.5 | 78.1 | 78.9 |
| ABench | 75.6 | 77.0 | 77.5 | 74.4 | 75.9 | 77.5 | 76.4 |
| MTVQA | 28.5 | 27.2 | 23.1 | 19.2 | 28 | 29.4 | 29.7 |
| Benchmark | Qwen2.5-VL-72B | InternVL2.5-38B-MPO | InternVL2.5-26B-MPO | Ovis1.6-27B | LLaVA-OV-72B | Ovis2-16B | Ovis2-34B |
|---|---|---|---|---|---|---|---|
| MMBench-V1.1test | 87.8 | 85.4 | 84.2 | 82.2 | 84.4 | 85.6 | 86.6 |
| MMStar | 71.1 | 70.1 | 67.7 | 63.5 | 65.8 | 67.2 | 69.2 |
| MMMUval | 67.9 | 63.8 | 56.4 | 60.3 | 56.6 | 60.7 | 66.7 |
| MathVistatestmini | 70.8 | 73.6 | 71.5 | 70.2 | 68.4 | 73.7 | 76.1 |
| HallusionBench | 58.8 | 59.7 | 52.4 | 54.1 | 47.9 | 56.8 | 58.8 |
| AI2D | 88.2 | 87.9 | 86.2 | 86.6 | 86.2 | 86.3 | 88.3 |
| OCRBench | 88.1 | 89.4 | 90.5 | 85.6 | 74.1 | 87.9 | 89.4 |
| MMVet | 76.7 | 72.6 | 68.1 | 68 | 60.6 | 68.4 | 77.1 |
| MMBenchtest | 88.2 | 86.4 | 85.4 | 84.6 | 85.6 | 87.1 | 87.8 |
| MMT-Benchval | 69.1 | 69.1 | 65.7 | 68.2 | - | 69.2 | 71.2 |
| RealWorldQA | 75.9 | 74.4 | 73.7 | 72.7 | 73.9 | 74.1 | 75.6 |
| BLINK | 62.3 | 63.2 | 62.6 | 48 | - | 59.0 | 60.1 |
| QBench | - | 76.1 | 76.0 | 77.7 | - | 79.5 | 79.8 |
| ABench | - | 78.6 | 79.4 | 76.5 | - | 79.4 | 78.7 |
| MTVQA | - | 31.2 | 28.7 | 26.5 | - | 30.3 | 30.6 |
视频基准
| Benchmark | Qwen2.5-VL-3B | InternVL2.5-2B | InternVL2.5-1B | Ovis2-1B | Ovis2-2B |
|---|---|---|---|---|---|
| VideoMME(wo/w-subs) | 61.5/67.6 | 51.9 / 54.1 | 50.3 / 52.3 | 48.6/49.5 | 57.2/60.8 |
| MVBench | 67.0 | 68.8 | 64.3 | 60.32 | 64.9 |
| MLVU(M-Avg/G-Avg) | 68.2/- | 61.4/- | 57.3/- | 58.5/3.66 | 68.6/3.86 |
| MMBench-Video | 1.63 | 1.44 | 1.36 | 1.26 | 1.57 |
| TempCompass | 64.4 | - | - | 51.43 | 62.64 |
| Benchmark | Qwen2.5-VL-7B | InternVL2.5-8B | LLaVA-OV-7B | InternVL2.5-4B | Ovis2-4B | Ovis2-8B |
|---|---|---|---|---|---|---|
| VideoMME(wo/w-subs) | 65.1/71.6 | 64.2 / 66.9 | 58.2/61.5 | 62.3 / 63.6 | 64.0/66.3 | 68.0/71.6 |
| MVBench | 69.6 | 72.0 | 56.7 | 71.6 | 68.45 | 68.15 |
| MLVU(M-Avg/G-Avg) | 70.2/- | 68.9/- | 64.7/- | 68.3/- | 70.8/4.23 | 76.4/4.25 |
| MMBench-Video | 1.79 | 1.68 | - | 1.73 | 1.69 | 1.85 |
| TempCompass | 71.7 | - | - | - | 67.02 | 69.28 |
| Benchmark | Qwen2.5-VL-72B | InternVL2.5-38B | InternVL2.5-26B | LLaVA-OneVision-72B | Ovis2-16B | Ovis2-34B |
|---|---|---|---|---|---|---|
| VideoMME(wo/w-subs) | 73.3/79.1 | 70.7 / 73.1 | 66.9 / 69.2 | 66.2/69.5 | 70.0/74.4 | 71.2/75.6 |
| MVBench | 70.4 | 74.4 | 75.2 | 59.4 | 68.6 | 70.3 |
| MLVU(M-Avg/G-Avg) | 74.6/- | 75.3/- | 72.3/- | 68.0/- | 77.7/4.44 | 77.8/4.59 |
| MMBench-Video | 2.02 | 1.82 | 1.86 | - | 1.92 | 1.98 |
| TempCompass | 74.8 | - | - | - | 74.16 | 75.97 |
使用
pip install torch==2.4.0 transformers==4.46.2 numpy==1.25.0 pillow==10.3.0
pip install flash-attn==2.7.0.post2 --no-build-isolation
Ovis2-1B
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
## cot-style input
# cot_suffix = "Provide a step-by-step solution to the problem, and conclude with 'the answer is' followed by the final solution."
# image_path = '/data/images/example_1.jpg'
# images = [Image.open(image_path)]
# max_partition = 9
# text = "What's the area of the shape?"
# query = f'<image>\n{text}\n{cot_suffix}'
## multiple-images input
# image_paths = [
# '/data/images/example_1.jpg',
# '/data/images/example_2.jpg',
# '/data/images/example_3.jpg'
# ]
# images = [Image.open(image_path) for image_path in image_paths]
# max_partition = 4
# text = 'Describe each image.'
# query = '\n'.join([f'Image {i+1}: <image>' for i in range(len(images))]) + '\n' + text
## video input (require `pip install moviepy==1.0.3`)
# from moviepy.editor import VideoFileClip
# video_path = '/data/videos/example_1.mp4'
# num_frames = 12
# max_partition = 1
# text = 'Describe the video.'
# with VideoFileClip(video_path) as clip:
# total_frames = int(clip.fps * clip.duration)
# if total_frames <= num_frames:
# sampled_indices = range(total_frames)
# else:
# stride = total_frames / num_frames
# sampled_indices = [min(total_frames - 1, int((stride * i + stride * (i + 1)) / 2)) for i in range(num_frames)]
# frames = [clip.get_frame(index / clip.fps) for index in sampled_indices]
# frames = [Image.fromarray(frame, mode='RGB') for frame in frames]
# images = frames
# query = '\n'.join(['<image>'] * len(images)) + '\n' + text
## text-only input
# images = []
# max_partition = None
# text = 'Hello'
# query = text
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')
批推理
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# preprocess inputs
batch_inputs = [
('/data/images/example_1.jpg', 'What colors dominate the image?'),
('/data/images/example_2.jpg', 'What objects are depicted in this image?'),
('/data/images/example_3.jpg', 'Is there any text in the image?')
]
batch_input_ids = []
batch_attention_mask = []
batch_pixel_values = []
for image_path, text in batch_inputs:
image = Image.open(image_path)
query = f'<image>\n{text}'
prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image], max_partition=9)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
batch_input_ids.append(input_ids.to(device=model.device))
batch_attention_mask.append(attention_mask.to(device=model.device))
batch_pixel_values.append(pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device))
batch_input_ids = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_input_ids], batch_first=True,
padding_value=0.0).flip(dims=[1])
batch_input_ids = batch_input_ids[:, -model.config.multimodal_max_length:]
batch_attention_mask = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_attention_mask],
batch_first=True, padding_value=False).flip(dims=[1])
batch_attention_mask = batch_attention_mask[:, -model.config.multimodal_max_length:]
# generate outputs
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(batch_input_ids, pixel_values=batch_pixel_values, attention_mask=batch_attention_mask,
**gen_kwargs)
for i in range(len(batch_inputs)):
output = text_tokenizer.decode(output_ids[i], skip_special_tokens=True)
print(f'Output {i + 1}:\n{output}\n')
参考
代码:https://github.com/AIDC-AI/Ovis
模型(Huggingface):https://huggingface.co/AIDC-AI/Ovis2-34B
模型(Modelscope):https://modelscope.cn/collections/Ovis2-1e2840cb4f7d45
Demo:https://huggingface.co/spaces/AIDC-AI/Ovis2-16B
arXiv: https://arxiv.org/abs/2405.20797


















 1202
1202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









