






文章目录
前言
应用场景,比如一个学校把自己所有题库放到一个大模型里面,经过训练,当模型学完所有题后,只要输入问题,可以查看每个题的答案,和解析。利用大模型,做自己下游应用,基本也就涵盖下面几个步骤。
一、数据(需求)
1. 收集数据
数据包含2个部分,问题和答案。整理自己数据集,这里以网上下载试题为例

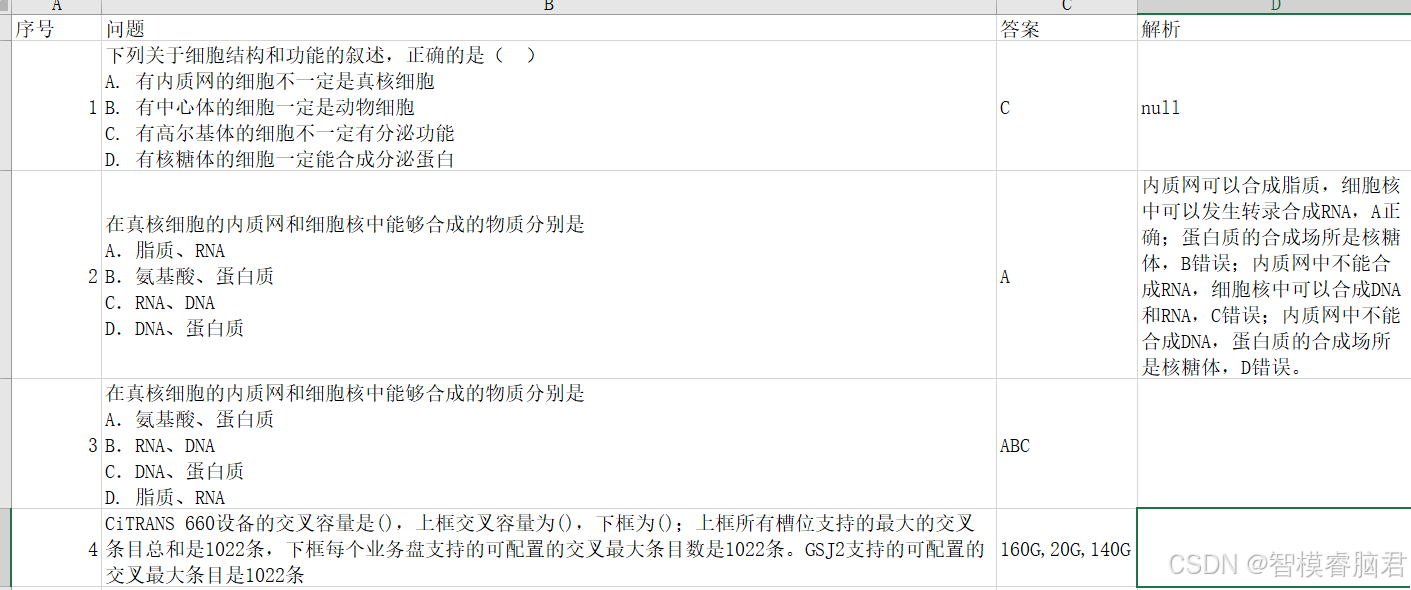
原始数据展示,里面主要是一些选择题, 包括答案和解析,里面随便找一篇。

2. 数据清洗和统一格式
需要对数据整理,去掉无效数据,然后手动讲所有试题统一格式excel,只包含序号,问题,答案,解析。比如如下整理完的文档,有的下载数据,里面有解析,就可以写上去,没有解析也可以不写。
二、方案
1. RAG
方案是可以用微调,也已RAG,这里选择微调。工具使用llamafactory.
然后将整理好的数据转成工具所要求的格式。转换脚本可以网上搜也可以让通用大模型去生成。就是给一个待转换的,就是我们整理好的execl,给他几条数据,输出就是llamafactory里面给定的json的例子,截取前面几条数据即可。然后大模型会自动生成脚本,再把我们exel传入进行这个表的转换。
2. 微调
选择微调原因,1,RAG对于题目数量多,就会每道题都有一个单独节点,效率就会降低。2,由于题库问题比较专业,base模型不一定能够正确理解问题需求。3,针对微调,有两两种状态,拟合和过拟合,由于我们更偏向对于题库准确性,所以希望是过拟合,这样更贴切题目。为了达到过拟合目的,我们测试集包含所有数据,测试集直接从训练集中拿取,训练过程中高度依赖精度指标,来判断模型是否达到训练的预期的目标(客观评价)
三、模型(硬件需求)
1. 模型选择
规模,1.5B~8B,如果选择8B,从效率上讲2张及以上24G显存
数据越小,模型越大,越容易过拟合,反之越不容易过拟合,得是预训练。
模型越小,越容易训练,模型越大,训练时间越长。
所以,选择base模型,不要选过大,够用就行。模型越大,智商越高,要改变它难度就越高,当前项目中,训练的是Lora部分,应该选一个较小base模型,和一个较大LoAR模型,使其跟个容易达到我们想要效果。理想的模型应该是模型参数小,但本身效果很好。
基座模型就选用这个1.5B的
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B')
Downloading [model.safetensors]: 100%|███████████▉| 3.29
Downloading [model.safetensors]: 100%|███████████▉| 3.30
Downloading [model.safetensors]: 100%|███████████▉| 3.30
Downloading [model.safetensors]: 100%|████████████| 3.31G/3.31G [04:27<00:00, 13.3MB/s]: 100%|███████████▉| 3.30
Processing 9 items: 100%|███████████████████████████| 9.Processing 9 items: 100%|███████████████████████████| 9.00/9.00 [04:27<00:00, 29.7s/it]: 100%|███████████▉| 3.31
2025-03-01 20:14:07,341 - modelscope - INFO - Download model 'deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B' successfully.
2025-03-01 20:14:07,342 - modelscope - INFO - Creating symbolic link [/root/autodl-tmp/llm/deepseek-ai/DeepSeek-R1-Distill-Qwen
root@autodl-container-5fd249bc19-6ec28c15:~/autodl-tmp#
2. 格式转换
脚本可以让大模型直接生成
import csv
import json
import os
# 指定包含CSV文件的目录
csv_directory = 'mydata'
# 输出的JSON文件路径
json_filepath = 'train.json'
# 读取CSV文件并转换为JSON格式
def csv_to_json(csv_directory, json_filepath):
data = [] # 初始化一个空列表来存储转换后的数据
# 遍历目录中的所有文件
for filename in os.listdir(csv_directory):
if filename.endswith('.csv'):
csv_filepath = os.path.join(csv_directory, filename)
try:
# 尝试使用UTF-8编码打开CSV文件
with open(csv_filepath, mode='r', encoding='utf-8') as csvfile:
csvreader = csv.DictReader(csvfile)
# 遍历CSV文件中的每一行
for row in csvreader:
# 将CSV行转换为字典,并添加到数据列表中
data.append({
"instruction": row['题目(含完整选项)'],
"input": "",
"output": row['答案']
})
except UnicodeDecodeError:
# 如果UTF-8编码失败,尝试使用GBK编码
with open(csv_filepath, mode='r', encoding='gbk') as csvfile:
csvreader = csv.DictReader(csvfile)
# 遍历CSV文件中的每一行
for row in csvreader:
# 将CSV行转换为字典,并添加到数据列表中
data.append({
"instruction": row['题目(含完整选项)'],
"input": "",
"output": row['答案']
})
# 将数据列表转换为JSON格式,并写入文件
with open(json_filepath, mode='w', encoding='utf-8') as jsonfile:
jsonfile.write(json.dumps(data, ensure_ascii=False, indent=4))
# 调用函数
csv_to_json(csv_directory, json_filepath)
3. 生成测试集脚本
import json
import random
# 指定输入的JSON文件路径
input_json_filepath = 'train.json'
# 指定输出的JSON文件路径
output_json_filepath = 'test.json'
# 指定选择数据的比例因子(例如,0.1表示选择10%的数据)
selection_ratio = 0.3
# 从JSON文件中读取数据
def read_json_file(filepath):
with open(filepath, 'r', encoding='utf-8') as file:
return json.load(file)
# 将随机选择的数据写入新的JSON文件
def write_random_data_to_json(random_data, filepath):
with open(filepath, 'w', encoding='utf-8') as file:
json.dump(random_data, file, ensure_ascii=False, indent=4)
# 主函数
def main():
# 读取JSON文件中的所有数据
all_data = read_json_file(input_json_filepath)
# 计算要选择的数据数量
number_of_items_to_select = int(len(all_data) * selection_ratio)
# 随机选择指定数量的数据
random_data = random.sample(all_data, number_of_items_to_select)
# 将随机选择的数据写入新的JSON文件
write_random_data_to_json(random_data, output_json_filepath)
# 调用主函数
main()
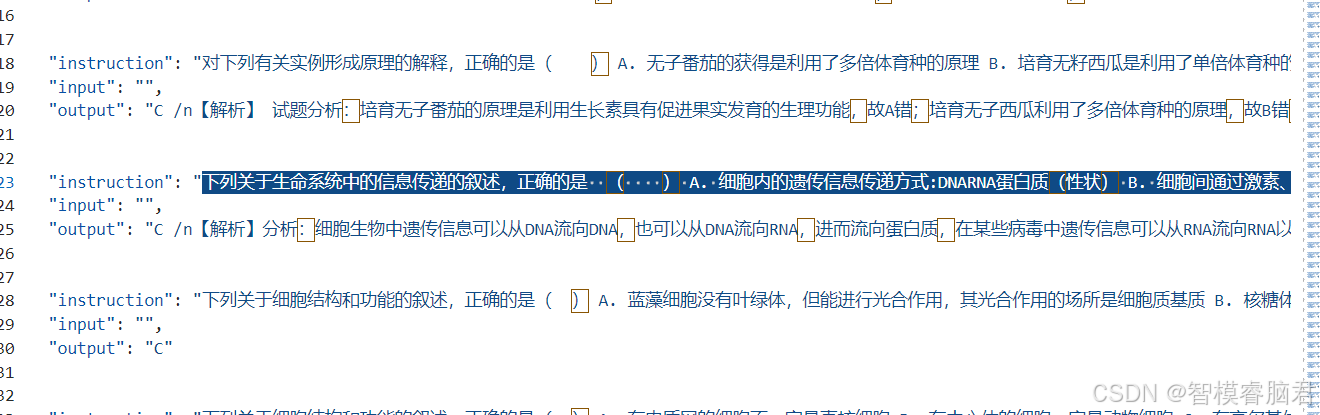
4. 转换前后对比
标注后数据

转换成llamafactory训练格式

四、训练
1. 训练工具
安装llamafactory
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
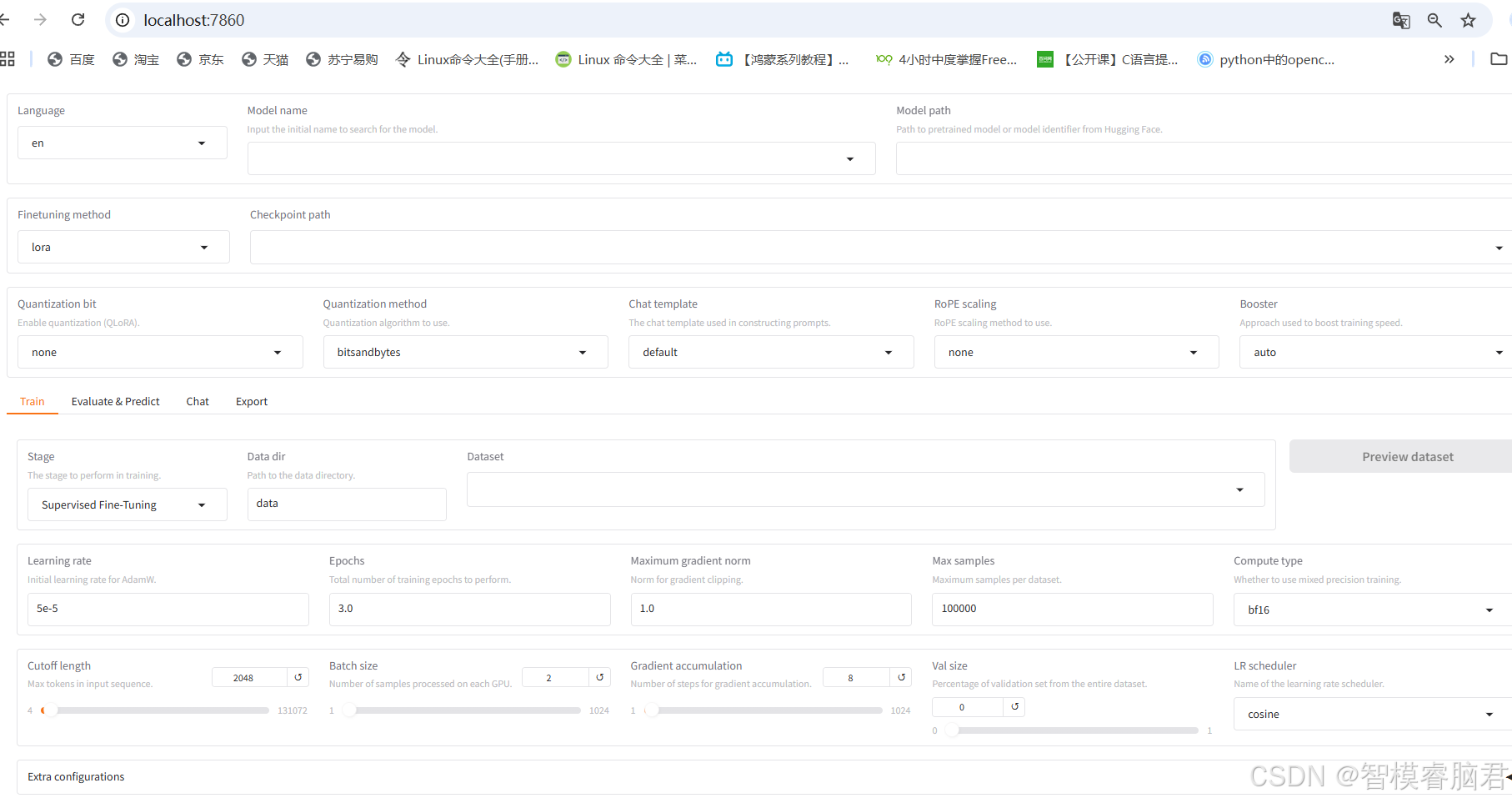
安装完成后启动webui,界面就是方便各种参数的配置,也可以直接在配置文件里改,yaml后缀的一个文件,为了更方便直观,启动页面改,终端输入下面命令即可。
llamafactory-cli webui
15.10 ffmpy-0.5.0 fire-0.7.0 frozenlist-1.5.0 fsspec-2024.9.0 gradio-5.18.0 gradio-client-1.7.2 huggingface-hub-0.29.1 jieba-0.42.1 joblib-1.4.2 lazy-loader-0.4 librosa- transformers-4.49.0 trl-0.9.6 typer-0.15.2 tyro-0.8.14 tzdata-2025.1 uvicorn-0.34.0 websockets-15.0 xxhash-3.5.0 yarl-1.18.3
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
root@autodl-container-5fd249bc19-6ec28c15:~/autodl-tmp/LLaMA-Factory# llamafactory-cli webui
关于llamafactory更多使用,可以参考下面一篇。
https://blog.csdn.net/weixin_41688410/article/details/145658326
2. 参数配置
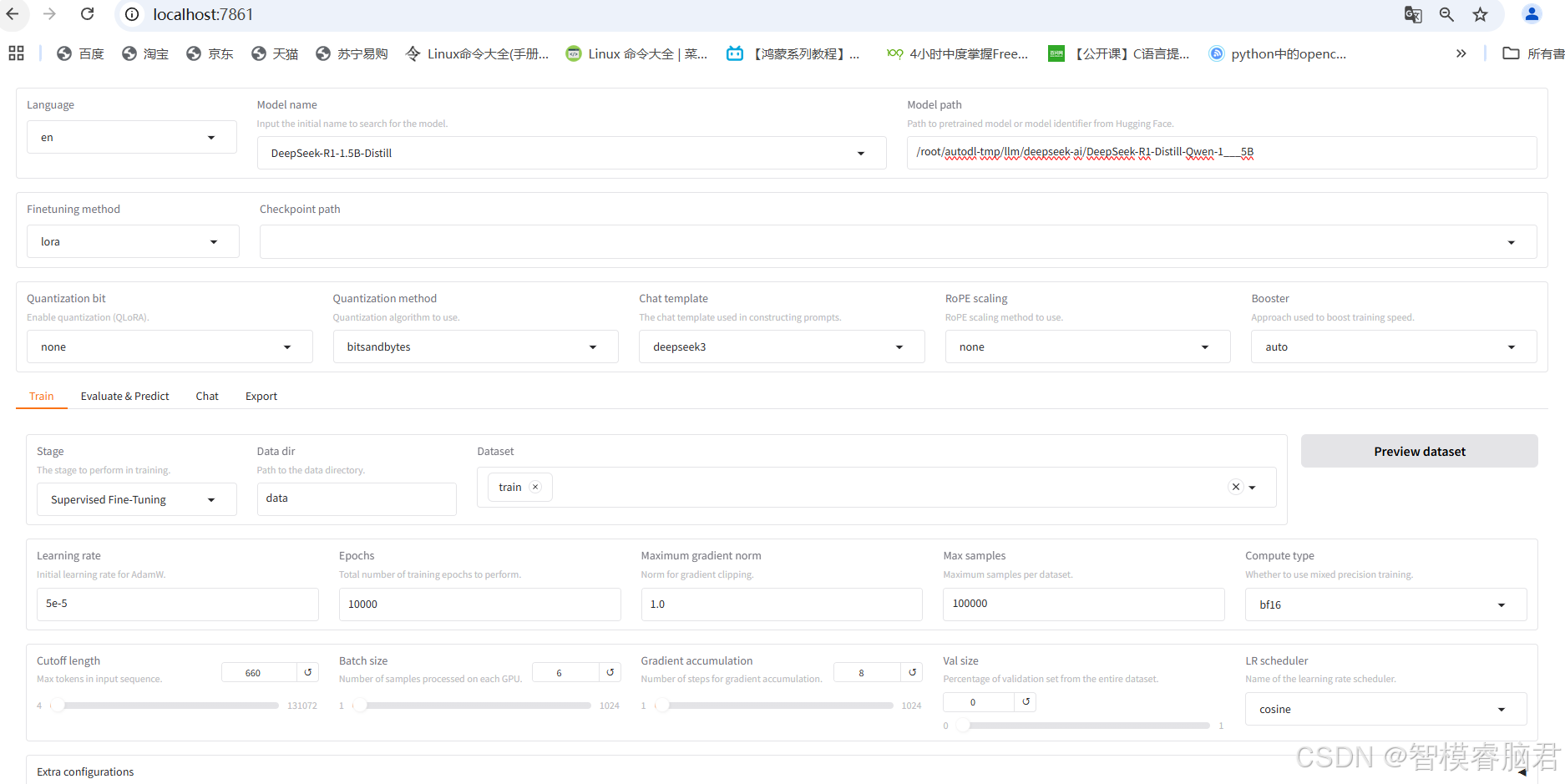
对于上面打开的空页面,把关键参数写入,比如用的模型,训练轮数,训练集路径等。
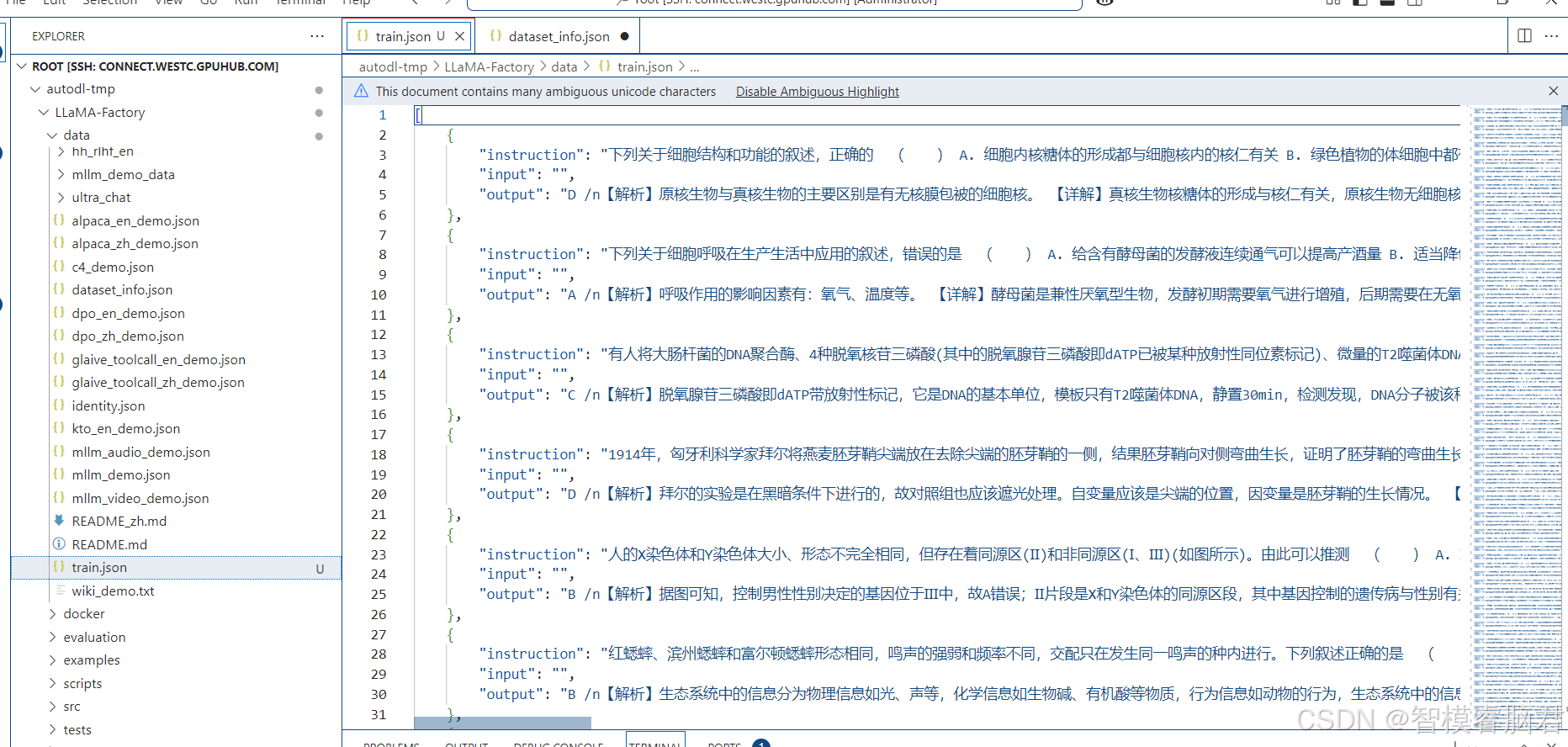
需要注意一点是新加的训练数据集,在页面选项里没有,这里需要在配置文件里添加一下。
这个train是数据集
然后在dataset_info里面加进去。
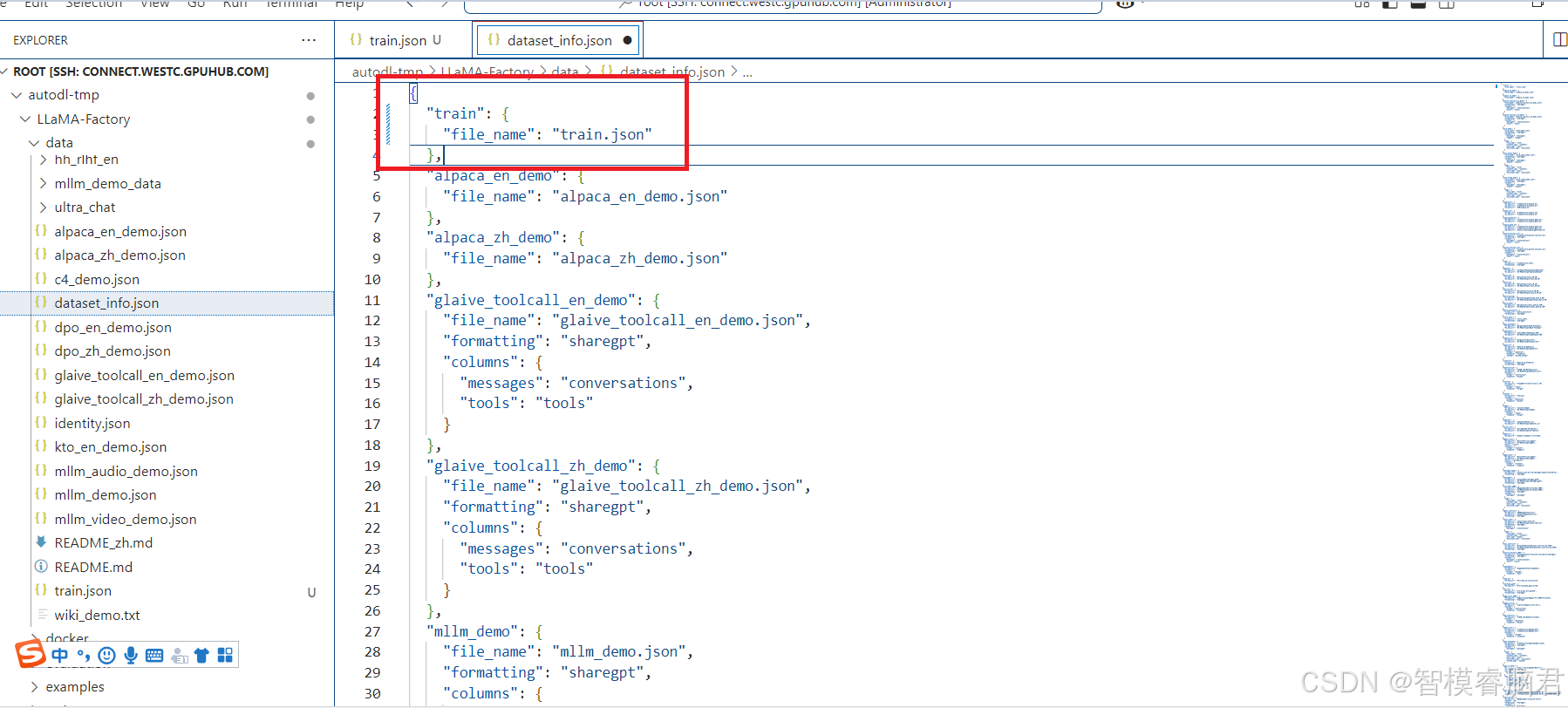
添加完以后,刷新页面,我们看到数据集已经加进去了
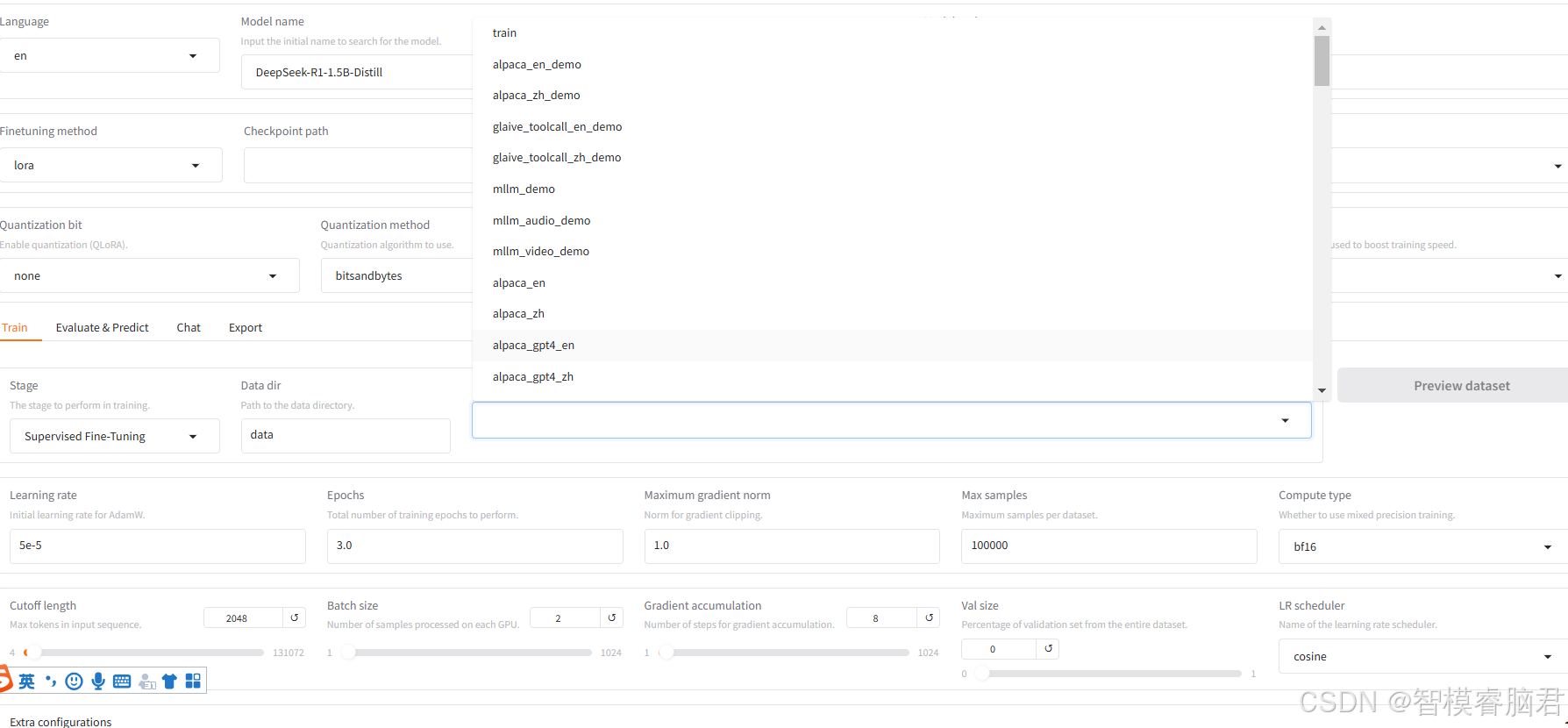
模型路径就给我们放模型的地址

微调选择lora,量化选择none,这里不做量化
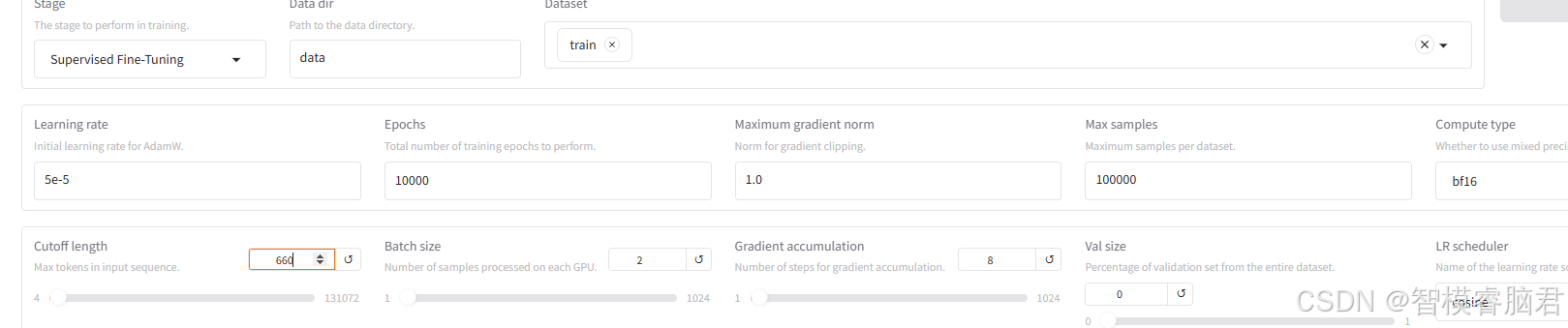
截断长度根据自己训练集,预估个最大长度,也就是问题输入的最大值,我这里给660,然后轮数可以大点,因为我们随时可以暂停,或者中断训练,因为训练时候,右边会有一个损失函数下降的图,如果损失函数已经收敛,后面趋势图中已经驱动稳定,一个躺平的线条,这时候说明再训练也没什么用了,就可以停掉。batchsize,主要根据自己显存大小调整,选了时候最好利用率在80以上,充分发挥作用,提高效率。
最重要的一个参数,就是LoRA秩的设置,过大的话对显存要求太高,所以这里设置32,LoRA缩放系统一般是秩的二倍关系,给64,是网上的经验值。
设置完以后效果
点击start开始训练
训练开始以后,可以看到页面损失函数变化
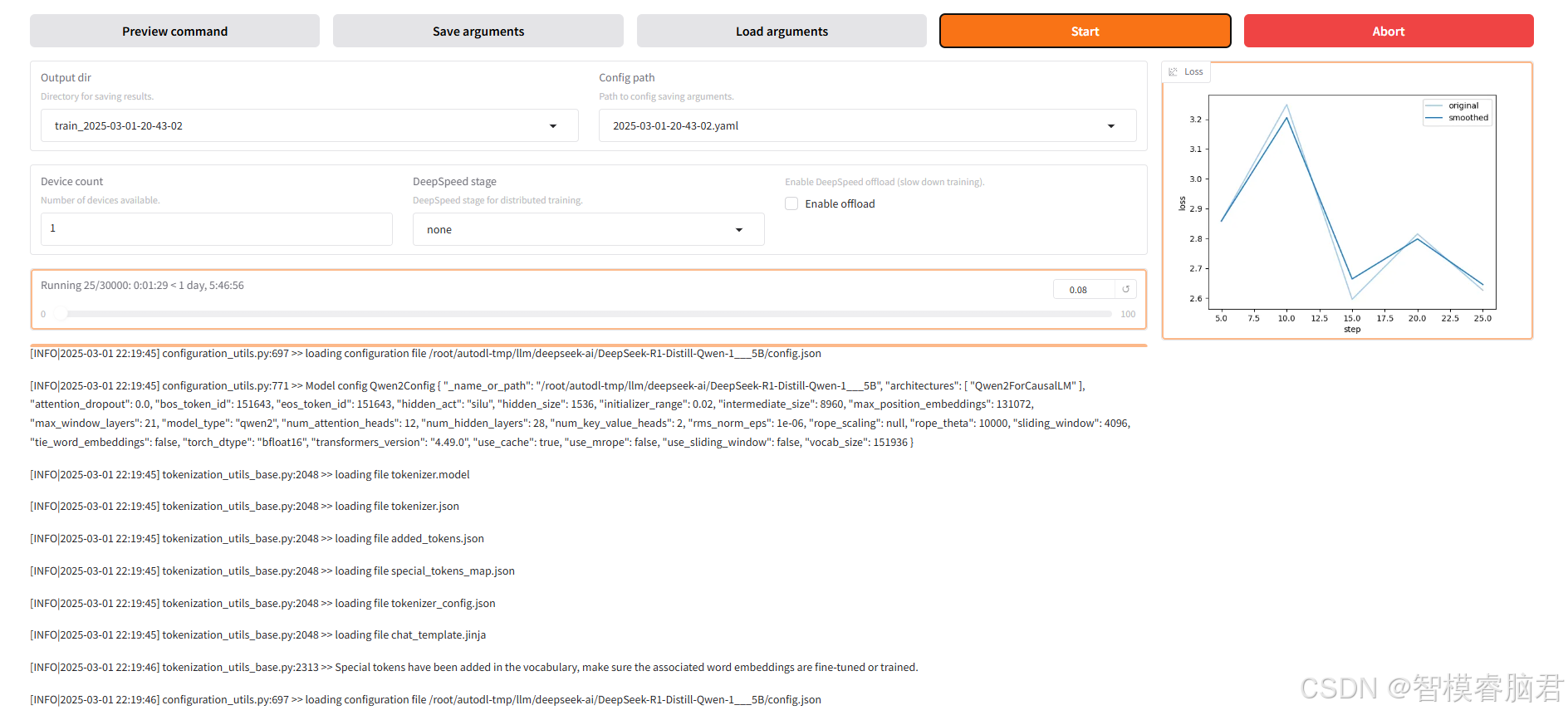
在终端也可以查看打印信息
[INFO|trainer.py:2413] 2025-03-01 22:19:52,332 >> Total optimization steps = 30,000
[INFO|trainer.py:2414] 2025-03-01 22:19:52,336 >> Number of trainable parameters = 9,232,384
0%| | 15/30000 [00:52<29:01:06, 3.48s/it][INFO|2025-03-01 22:20:44] llamafactory.train.callbacks:157 >> {'loss': 2.5956, 'learning_rate': 5.0000e-05, 'epoch': 4.77, 'throughput': 6686.73}
{'loss': 2.5956, 'grad_norm': 0.5885675549507141, 'learning_rate': 4.999996915749259e-05, 'epoch': 4.77, 'num_input_tokens_seen': 351360}
0%|
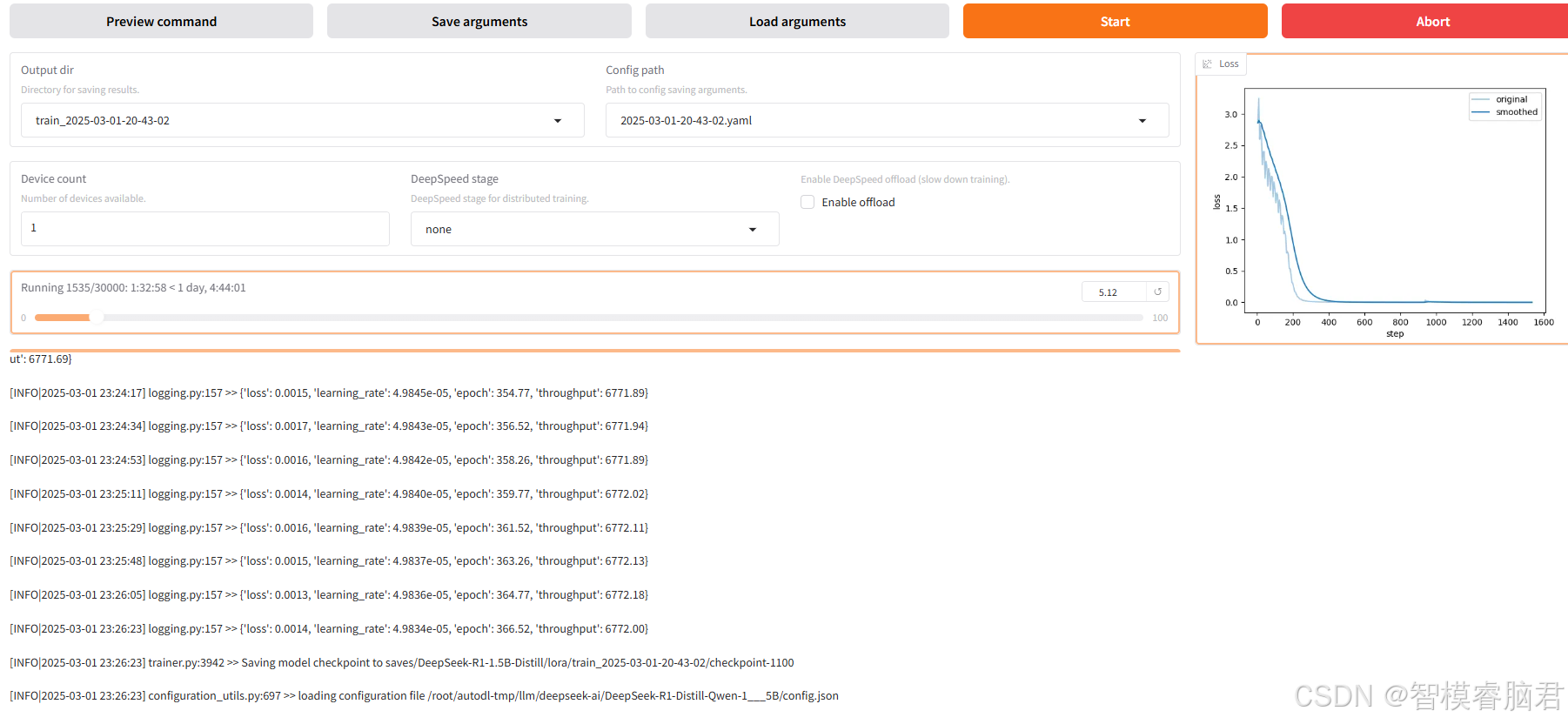
经过几个小时等待,发现函数曲线以及收敛了,这是可以停了。
看一下代码那边,就拿最后一次做测试
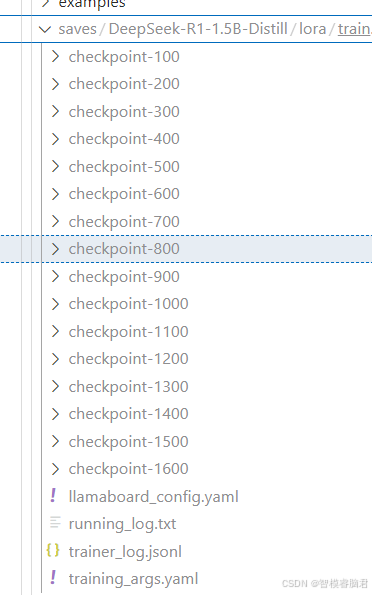
五、评估
选择Evaluate&Predict
检查点路径,把最后一次的checkpoint路径写入,这里放入checkpoint-1600
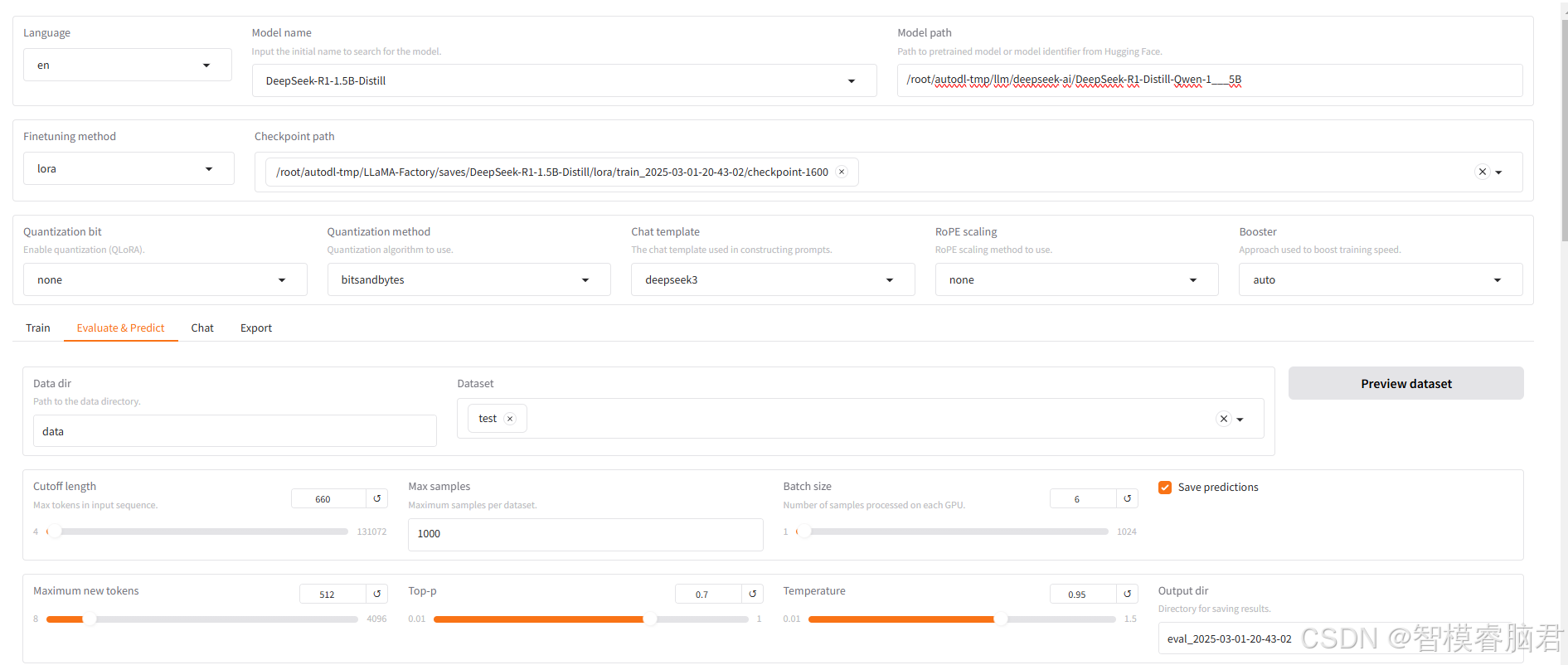
数据集选择test
因为我们是要一个过拟合模型,所以测试集就在训练集中随机取出一些数据
我们就取30%,下面是随机取值脚本。
mport json
import random
# 指定输入的JSON文件路径
input_json_filepath = 'train.json'
# 指定输出的JSON文件路径
output_json_filepath = 'test.json'
# 指定选择数据的比例因子(例如,0.1表示选择10%的数据)
selection_ratio = 0.3
# 从JSON文件中读取数据
def read_json_file(filepath):
with open(filepath, 'r', encoding='utf-8') as file:
return json.load(file)
# 将随机选择的数据写入新的JSON文件
def write_random_data_to_json(random_data, filepath):
with open(filepath, 'w', encoding='utf-8') as file:
json.dump(random_data, file, ensure_ascii=False, indent=4)
# 主函数
def main():
# 读取JSON文件中的所有数据
all_data = read_json_file(input_json_filepath)
# 计算要选择的数据数量
number_of_items_to_select = int(len(all_data) * selection_ratio)
# 随机选择指定数量的数据
random_data = random.sample(all_data, number_of_items_to_select)
# 将随机选择的数据写入新的JSON文件
write_random_data_to_json(random_data, output_json_filepath)
# 调用主函数
main()
所有设置参数,在saves下面,有个training_args.yaml文件,里面都有保存。
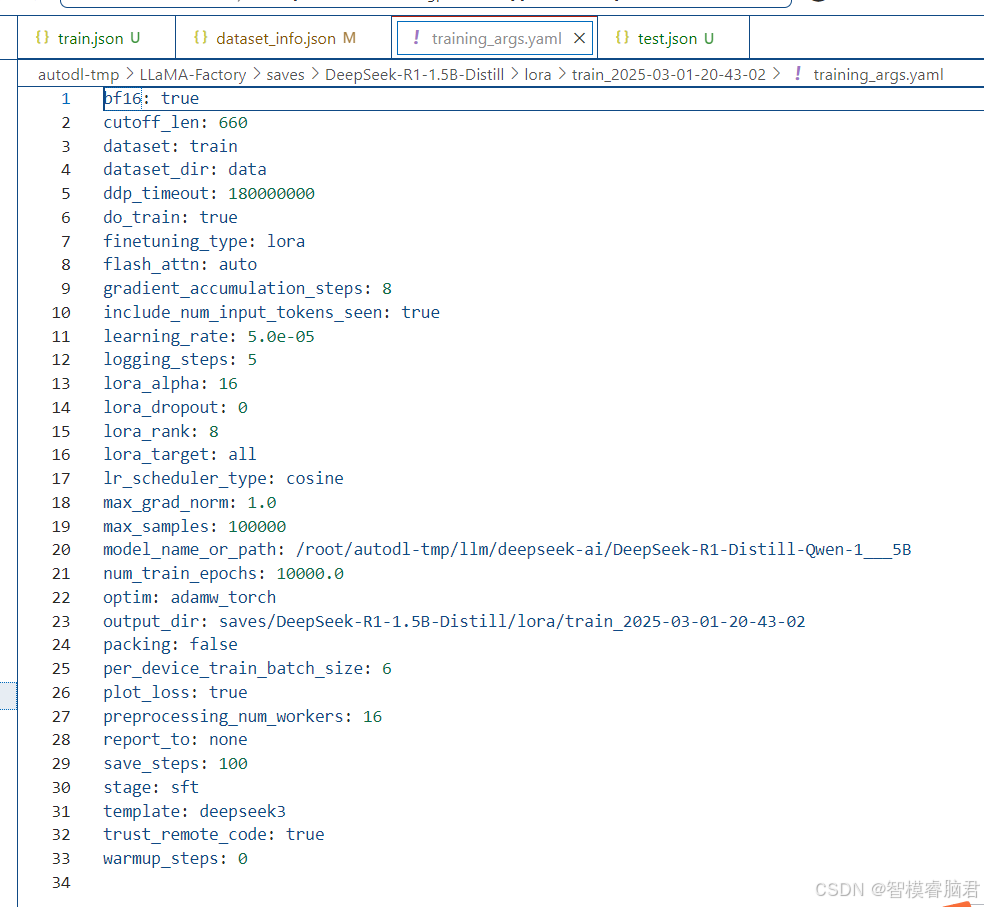
截断长度,660,最大样本数1000,批处理大小6。别的都默认。
在评估前,再看一下显存,刚才训练时候是否有释放出来。
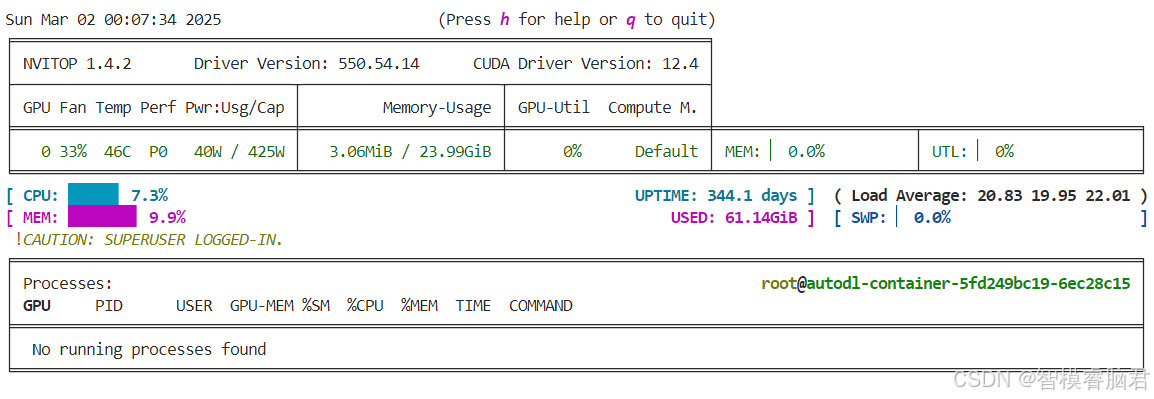
点击start,就开始评估了。
[INFO|tokenization_utils_base.py:2048] 2025-03-02 00:10:17,571 >> loading file chat_template.jinja
[INFO|tokenization_utils_base.py:2313] 2025-03-02 00:10:17,953 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|2025-03-02 00:10:17] llamafactory.data.loader:157 >> Loading dataset test.json...
Setting num_proc from 16 back to 1 for the train split to disable multiprocessing as it only contains one shard.
Generating train split: 54 examples [00:00, 7961.35 examples/s]
Converting format of dataset (num_proc=16): 100%|██████████████████████████████████████| 54/54 [00:00<00:00, 227.77 examples/s]
Running tokenizer on dataset (num_proc=16): 100%|███████████████████████████████████████| 54/54 [00:02<00:00, 22.47 examples/s]
eval example:
input_ids:
[151646, 151644, 107976, 20412, 57218, 107151, 5373, 111068, 78556, 104901, 53481, 3837, 90919, 88991, 100146, 220, 42344, 262, 220, 7552, 362, 13, 51461, 116, 99918, 108359, 107426, 108122, 27369, 3837, 77288, 101043, 55320, 20412, 100206, 9370, 108122, 101252, 425, 13, 51461, 116, 99918, 101047, 45, 114672, 106939, 74046, 15946, 3837, 107151, 101047, 45, 99558, 114672, 116312, 15946, 356, 13, 6567, 108, 101, 74046, 99918, 102388, 99524, 104876, 101990, 57218, 76, 30720, 15946, 106939, 74046, 108467, 107684, 107173, 422, 13, 10236, 96, 115, 99918, 33108, 75108, 100912, 100443, 9370, 64064, 75768, 18493, 23990, 63314, 30720, 33108, 99493, 63314, 55320, 99774, 38989, 63314, 15946, 20412, 101970, 151645]
inputs:
<|begin▁of▁sentence|><|User|>下列是与蛋白质、核酸相关的一些描述,其中正确的是 ( ) A. 核酸均可携带遗传信息,但只有DNA是生物的遗传物质 B. 核酸中的N存在于碱基中,蛋白质中的N主要存在于氨基中 C. 氨基酸分子互相结合的方式与mRNA中碱基排列顺序无关 D. 磷酸和五碳糖的连接方式在单链RNA和双链DNA的一条链中是不同的<|Assistant|>
label_ids:
[34, 608, 77, 10904, 106637, 10958, 102150, 21515, 100206, 71268, 102704, 55320, 33108, 30720, 101441, 111068, 3837, 41146, 108122, 101252, 20412, 55320, 1773, 111068, 105166, 101286, 75317, 20412, 71137, 119814, 99918, 3837, 16, 102388, 71137, 119814, 99918, 67071, 16, 102388, 118095, 5373, 16, 102388, 75108, 100912, 100443, 33108, 16, 102388, 95312, 109958, 106939, 74046, 101286, 1773, 107151, 105166, 101286, 75317, 20412, 116313, 3837, 116313, 67338, 99694, 52510, 99872, 39762, 104175, 101894, 118901
eek-R1-Distill-Qwen-1___5B/generation_config.json
[INFO|configuration_utils.py:1140] 2025-03-02 00:10:23,816 >> Generate config GenerationConfig {
"bos_token_id": 151646,
"do_sample": true,
"eos_token_id": 151643,
"temperature": 0.6,
"top_p": 0.95
}
[WARNING|2025-03-02 00:10:23] llamafactory.train.sft.workflow:168 >> Batch generation can be very slow. Consider using `scripts/vllm_infer.py` instead.
[INFO|trainer.py:4258] 2025-03-02 00:10:23,894 >>
***** Running Prediction *****
[INFO|trainer.py:4260] 2025-03-02 00:10:23,894 >> Num examples = 54
[INFO|trainer.py:4263] 2025-03-02 00:10:23,894 >> Batch size = 6
78%|███████████████████████████████████████████████████████████████████████▌ | 7/9 [01:02<00:19, 9.89s/it]
可以看到,测试集里,总共是54道题,等评估结束。
[[INFO|2025-03-02 00:25:56] llamafactory.model.loader:157 >> all params: 1,777,088,000
[WARNING|2025-03-02 00:25:56] llamafactory.train.sft.workflow:168 >> Batch generation can be very slow. Consider using `scripts/vllm_infer.py` instead.
[INFO|trainer.py:4258] 2025-03-02 00:25:56,322 >>
***** Running Prediction *****
[INFO|trainer.py:4260] 2025-03-02 00:25:56,322 >> Num examples = 54
[INFO|trainer.py:4263] 2025-03-02 00:25:56,322 >> Batch size = 6
100%|████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:44<00:00, 5.57s/it]Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.850 seconds.
Prefix dict has been built successfully.
100%|████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:46<00:00, 5.12s/it]
***** predict metrics *****
predict_bleu-4 = 67.6259
predict_model_preparation_time = 0.0046
predict_rouge-1 = 99.9376
predict_rouge-2 = 49.9606
predict_rouge-l = 99.9744
predict_runtime = 0:00:55.16
predict_samples_per_second = 0.979
predict_steps_per_second = 0.163
[INFO|2025-03-02 00:26:51] llamafactory.train.sft.trainer:157 >> Saving prediction results to saves/DeepSeek-R1-1.5B-Distill/lora/eval_2025-03-01-20-43-02/generated_predictions.jsonl
predict_rouge-1 就是我们选择题的答案,可以看到几乎接近100%。
上面就是评估结果,客观评估不够直观,直接进行主管评估,去实际测测效果。
六、部署
切换到chat界面,点击加载模型
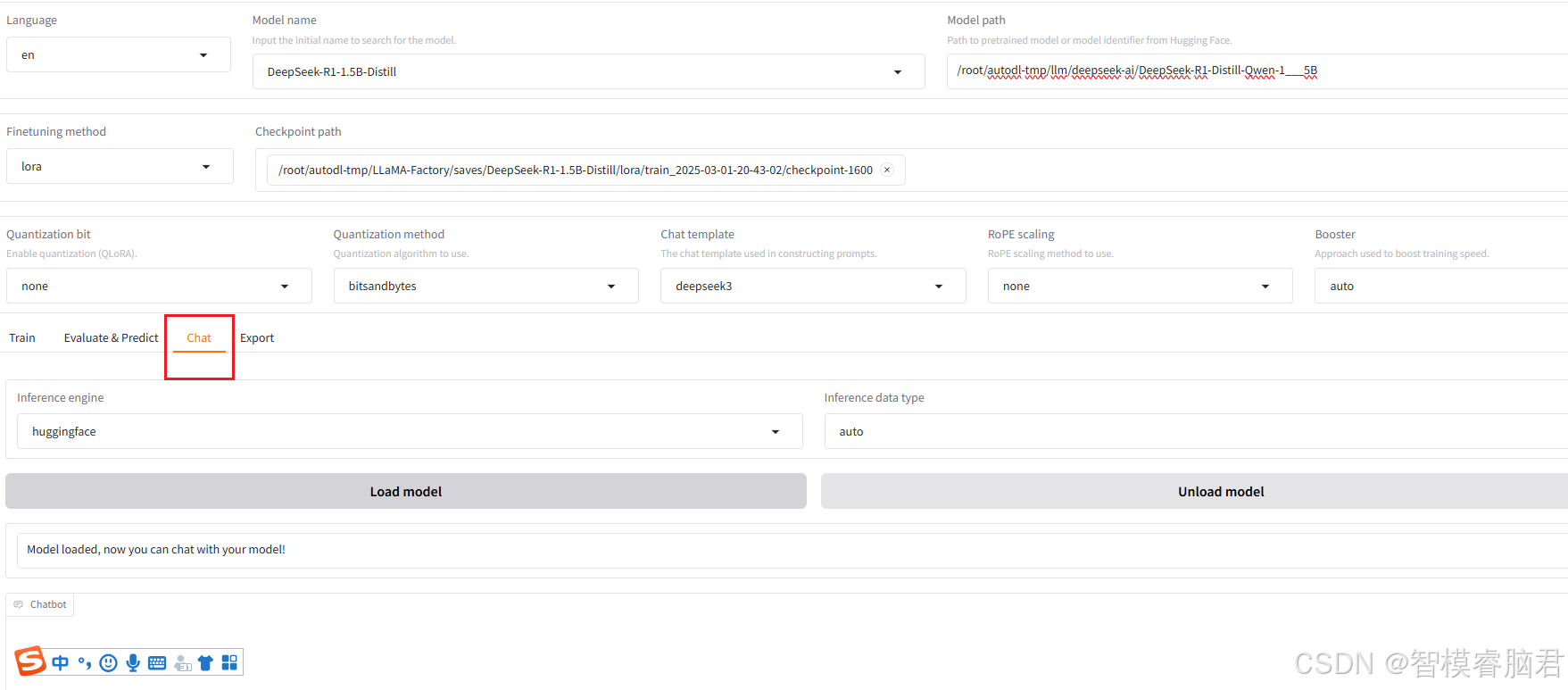
去测试集中随机抽取几条
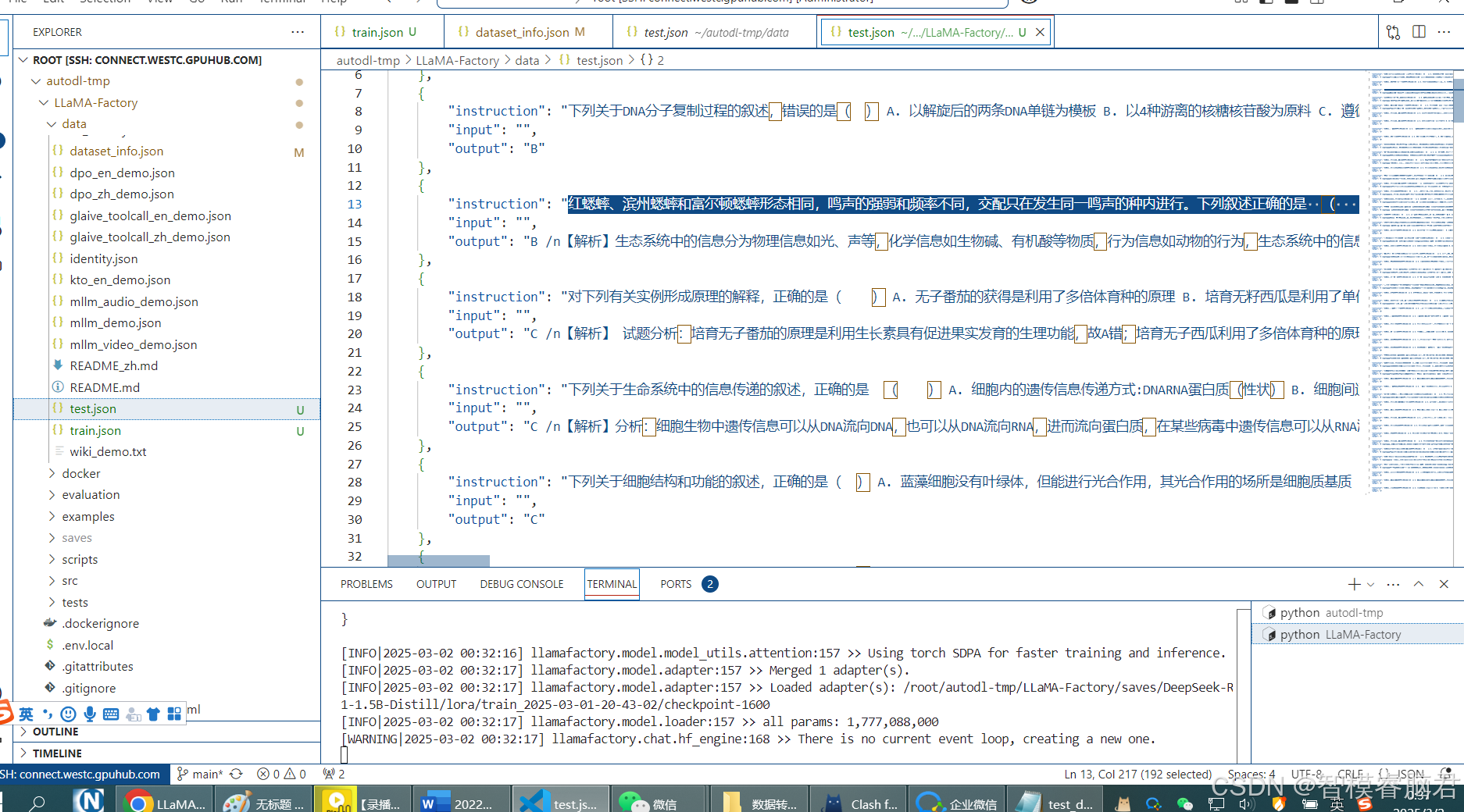

对于那种没有解释的可以看看
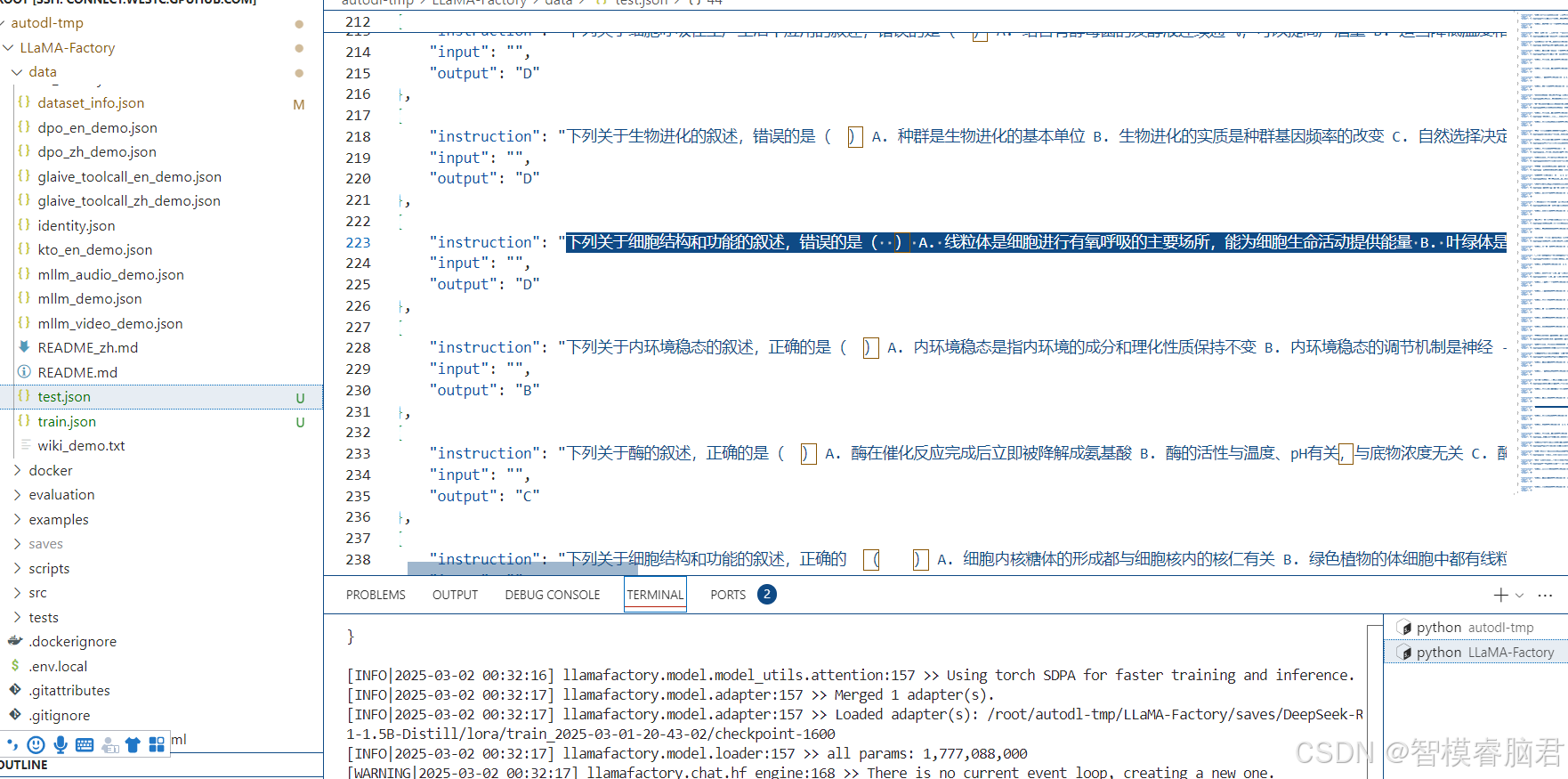
模型也给出了正确答案。
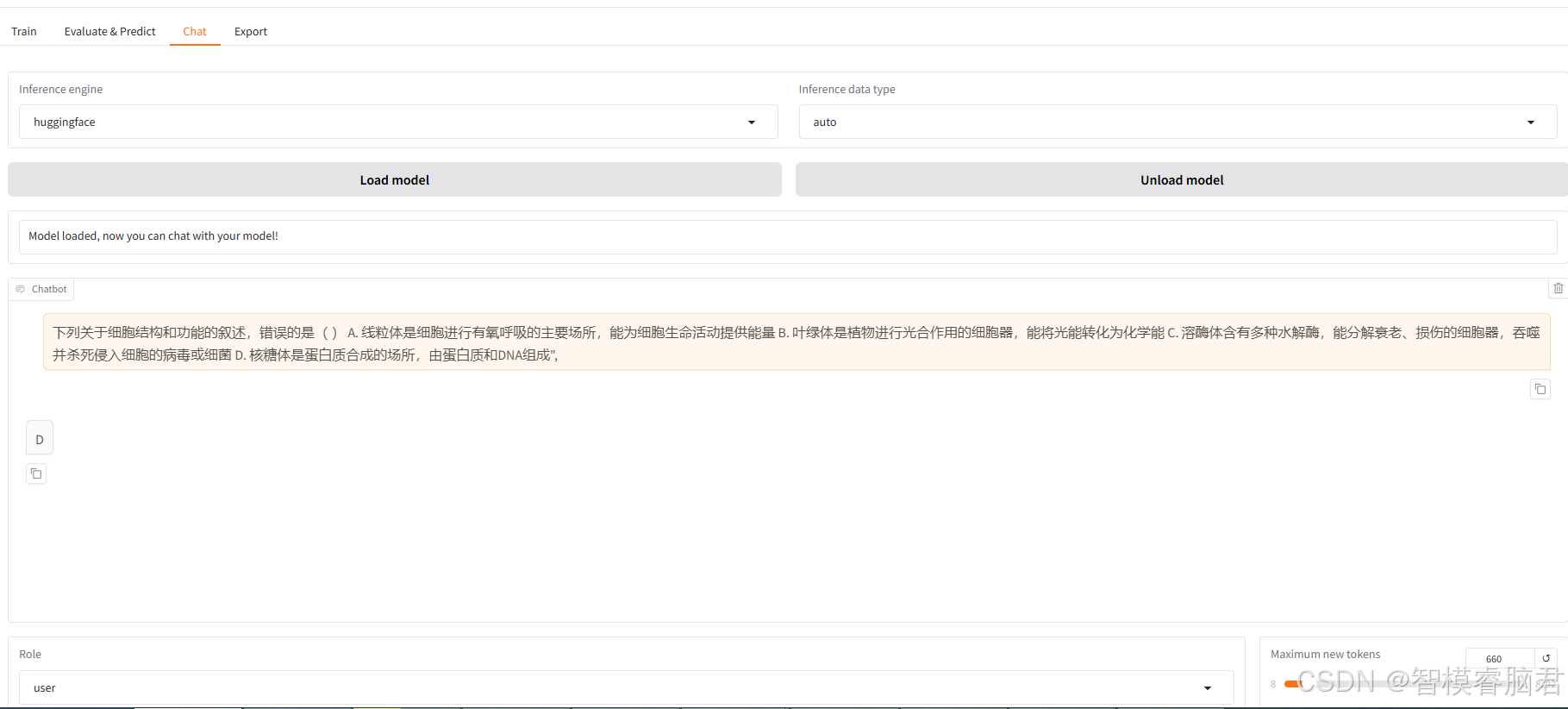
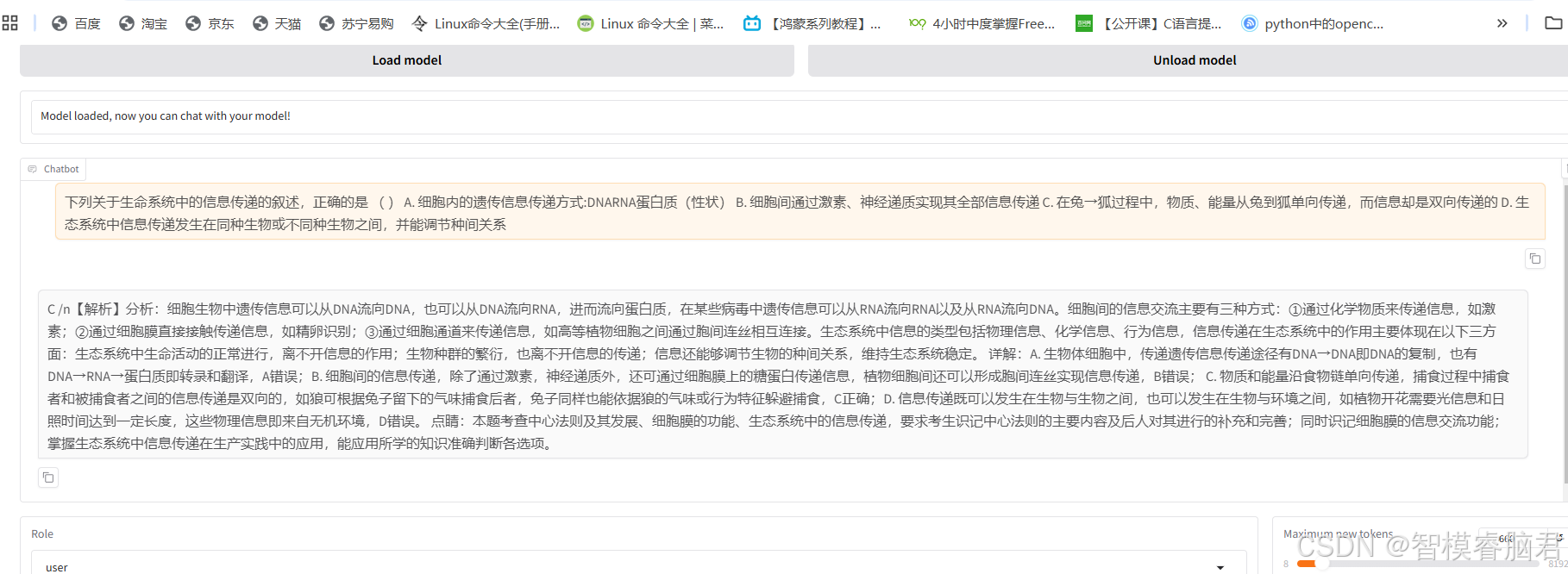
测了几条,对比了一下测试集答案,都是一样的,说明训练效果明显。
但是也发了现了一个问题,就是每次对话,当clear history后,第一次对话,测试数据集中挑了好多个,基本和答案都一模一样,包括解释。不过在多轮对话过后,准确性会变差。
这个不知道什么原因,有知道的小伙伴欢迎留言。
如果是只支持单轮,多轮就有错,那在哪设置多轮参数呢,还是说llamafactory这个chat就是个固定的只支持单轮。
七、导出
先合并,把基座模型和LoAR微调模型,合并成一个模型
选择Export,只需要填写导出路径,别的都默认
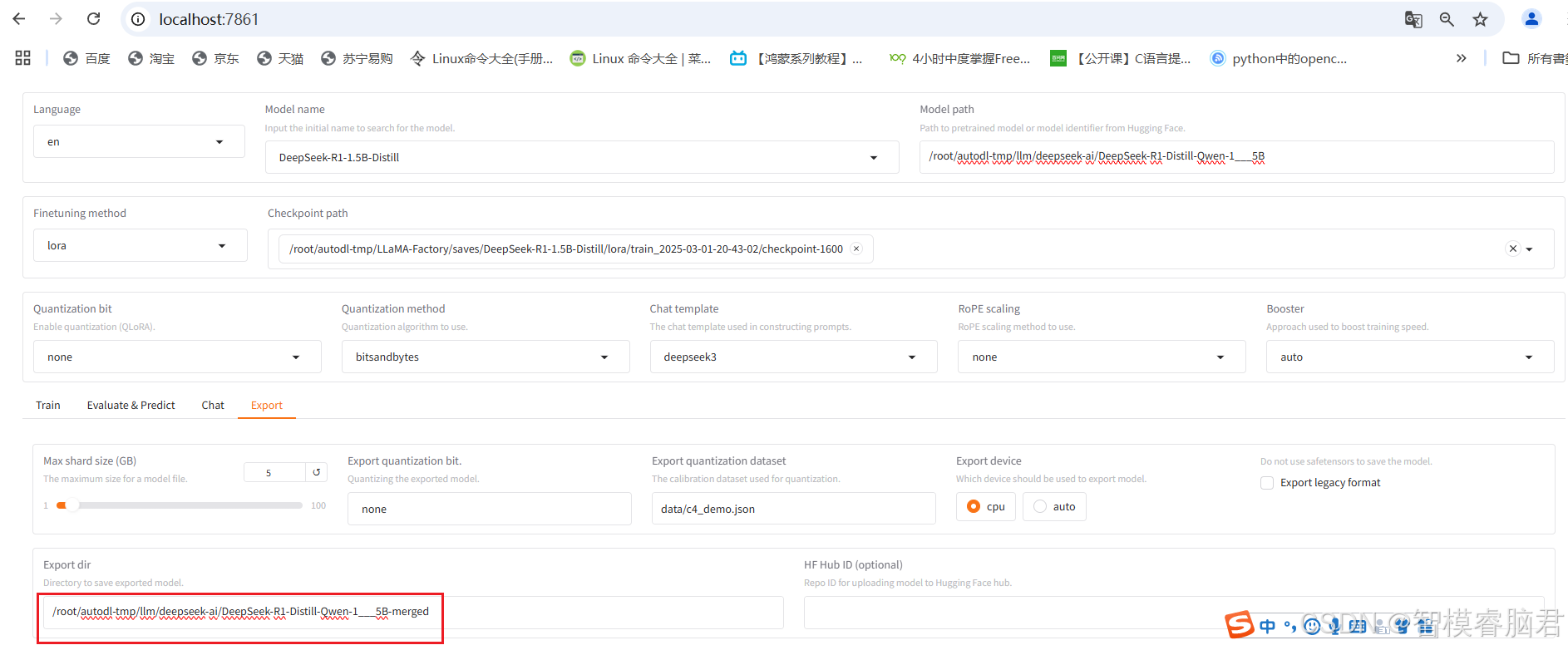
合并成功
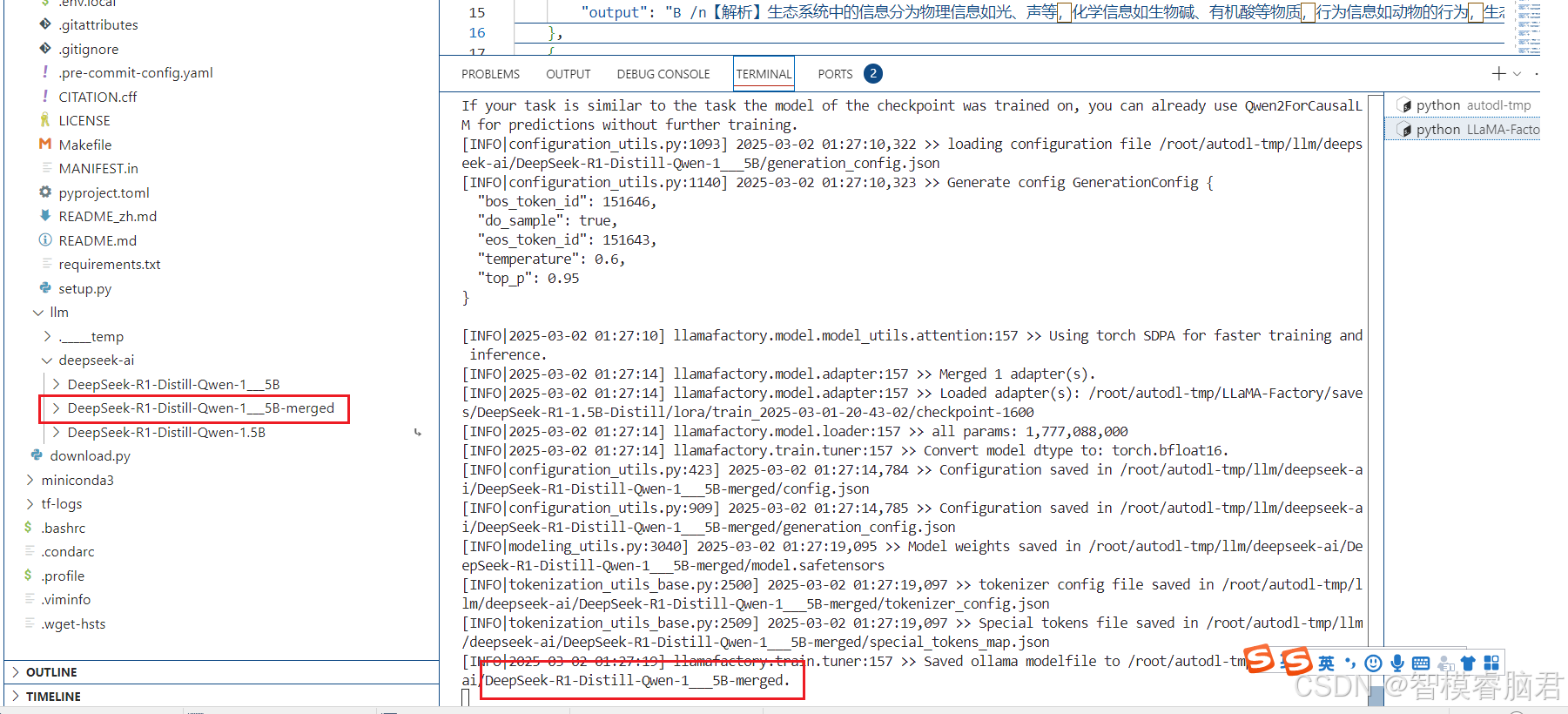
测试
模型使用merged,删掉checkpoint,使用huggingface推理引擎,最后点击加载模型
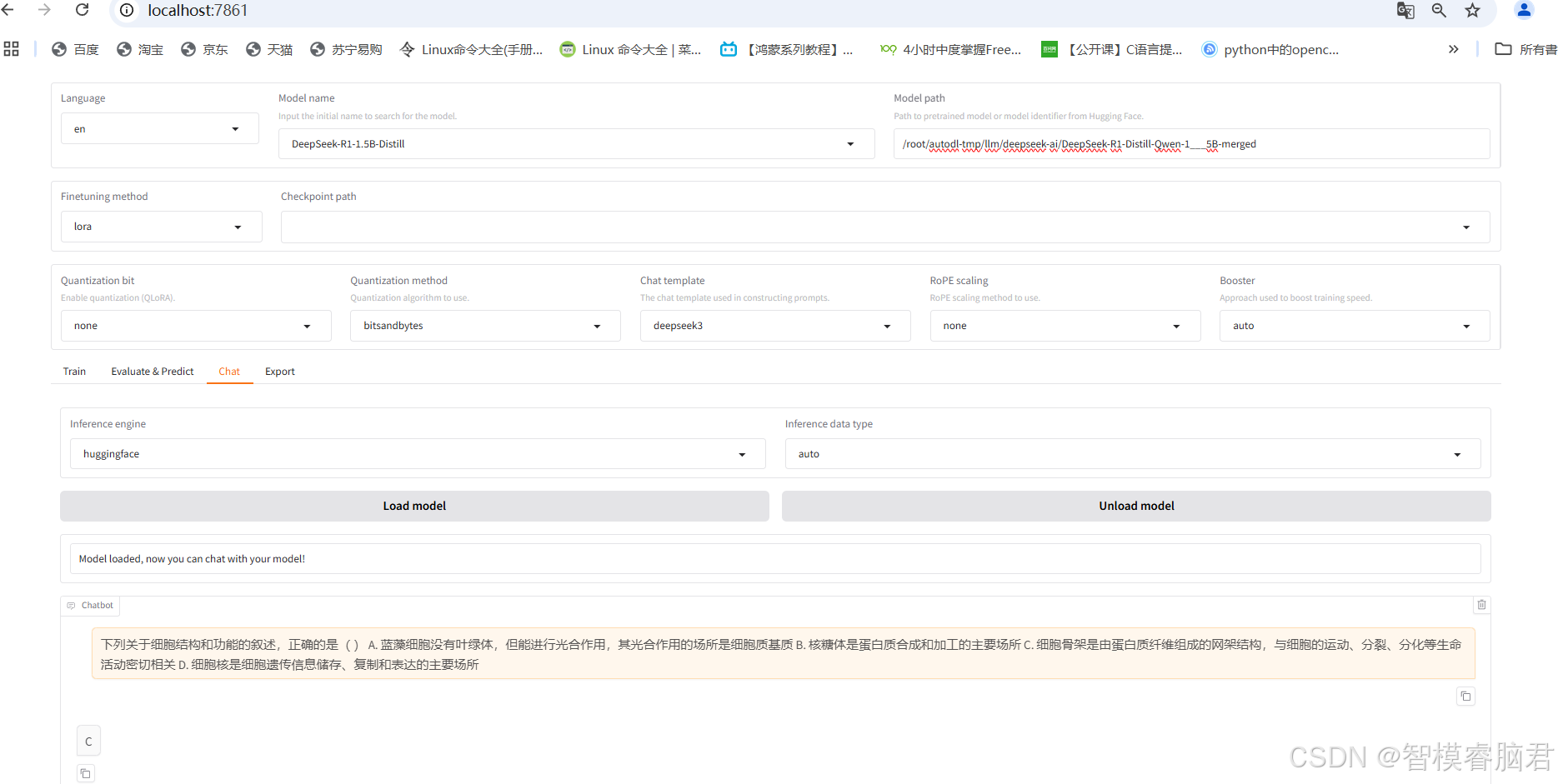
运行正常,说明模型合并成功。

















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









