







没想到,全球最强的开源模型
一夜易主!
昨天晚上
大数据和AI公司Databricks宣布开源他们的132B大模型DBRX
它采用了细粒度MoE架构
而且每次输入仅使用360亿参数
实现了更快的每秒token吞吐量
这种独特的MoE架构
让DBRX成为开源模型的SOTA
推理速度比LLaMA 2-70B快了2倍!
更重要的是
DBRX的训练成本直接砍半
只用了1000万美元和3100块H100
Databricks就在2个月内肝出了DBRX
DBRX在语言理解、编程、数学和逻辑方面
轻松击败了开源模型LLaMA2-70B、Mixtral
以及Grok-1

甚至,DBRX的整体性能超越GPT-3.5
尤其在编程方面,完全击败了GPT-3.5
并且,DBRX还为开放社区和企业
提供了仅限于封闭模型的API功能
现在
基本模型DBRX Base和微调模型DBRX Instruct的权重
已经在GitHub和Hugging Face开放许可了
用户可以在公共、自定义或者其他专有数据上运行和调整
从今天开始
Databricks客户就可以通过API使用DBRX
今天我们就来聊聊这个新登上王座的大模型

Databricks这家公司
先说说Databricks这家公司
本身源自于加州大学、伯克利分校的AMPLab项目
致力于研发一款
基于Scala构建的开源分布式计算框架、Apache Spark
相信做大数据的人一定都知道
所谓的“湖仓一体”(data Lakehouse)就是这家公司首创的概念

2023年3月的时候
Databricks就推出了开源语言模型dolly

并在后续的2.0版本打出了
首个真正开放和商业可行的指令调优大模型的口号

所以
这是Databricks的「第二次搅局」。
这一次发布的DBRX
按照负责人乔纳森·弗兰克尔Jonathan Frankle的原话是
树立了开源大语言模型的新标准

Jonathan Frankle曾经是生成式AI创业公司MosaicML的首席科学家

在2023年6月
MosaicML被Databricks以14(13)亿美元的大手笔收购

在这之后
Frankle辞掉了哈佛大学的教授工作
专心开发 DBRX
DBRX的详细情况
介绍完背景
下面我们就来看看DBRX的详细情况
首先,万物基于Transformer
DBRX也不例外
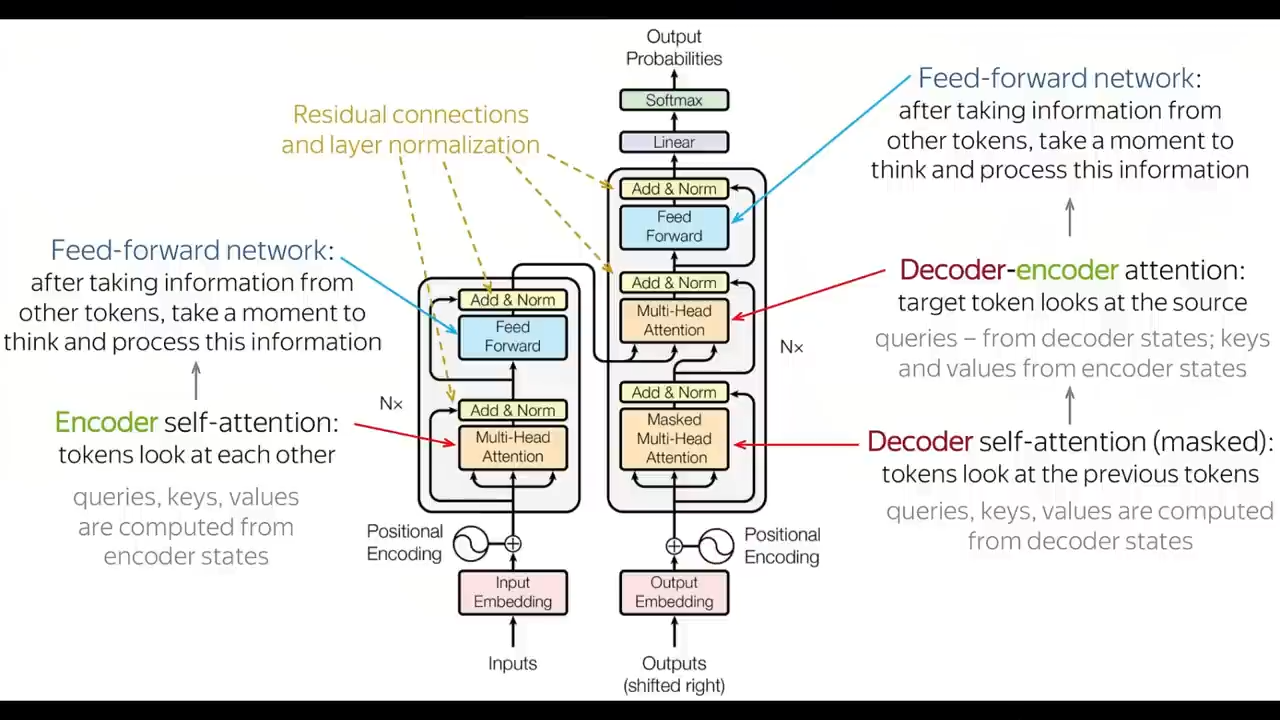
除此之外
DBRX还是一个混合专家MoE模型
总计1320亿,也就是132B参数
在12T的文本和代码数据tokens上进行了预训练
支持的最大上下文长度为32k
对应的,Llama 2有700亿个参数
Mixtral有450亿个,Grok有3140亿个
MoE架构引入了一种模块化的体系结构
从一个巨大的神经网络里分解出多个子网络
也称为专家网络进行协同工作
一起来处理输入数据

相比Mixtral``和Grok-1等其他开源MoE模型
DBRX有个“独门绝学”,
就是它配置了16个专家网络
在每层为每个token选择4个专家参与运算
并且仅使用了360亿的参数
相应的
Mixtral和Grok-1则各有8个专家网络
在每层为每个token选择2个专家
这样不仅提高了底层硬件的利用率
还将训练效率提高了30%到50%,
在响应速度变快的同时
还能减少所需的能源
而且这种改进提供了65倍的专家组合可能性
能够显著提升模型的质量
此外
DBRX还使用了旋转位置编码RoPE、门控线性单元GLU、分组查询注意力GQA
以及课程学习curriculum learning
并且使用了tiktoken项目中提供的GPT-4分词器
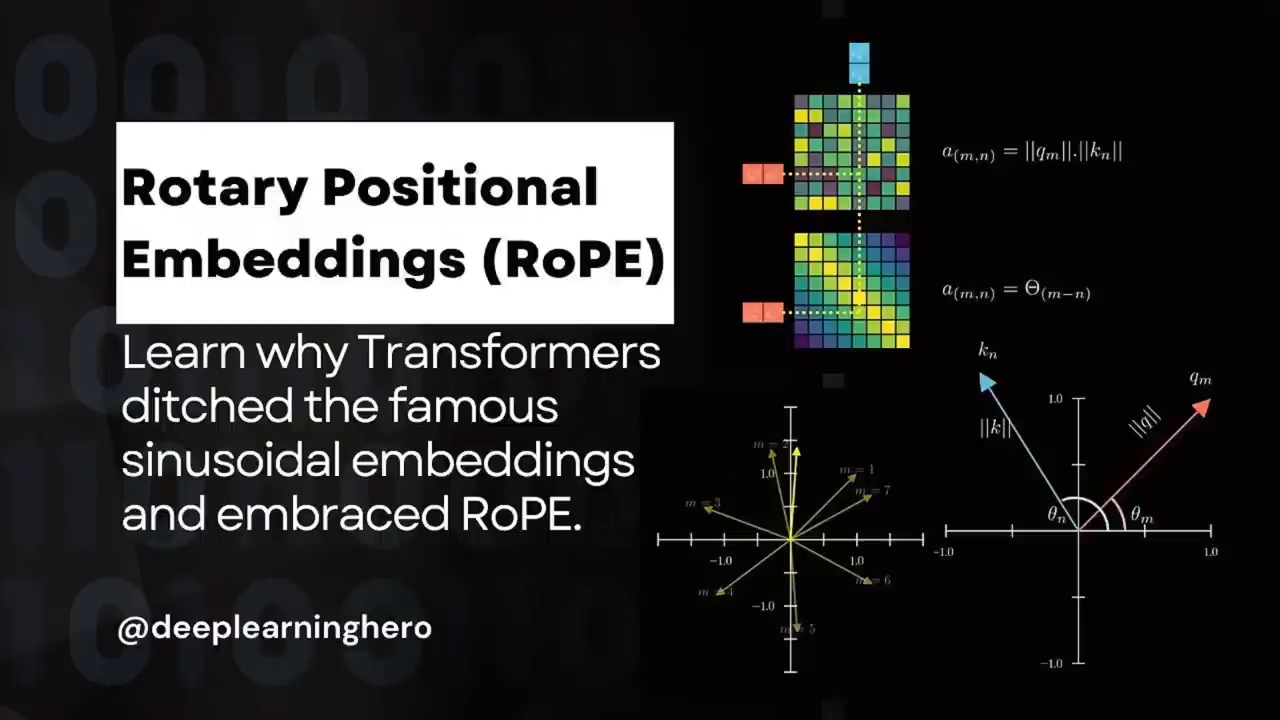
旋转位置编码RoPE
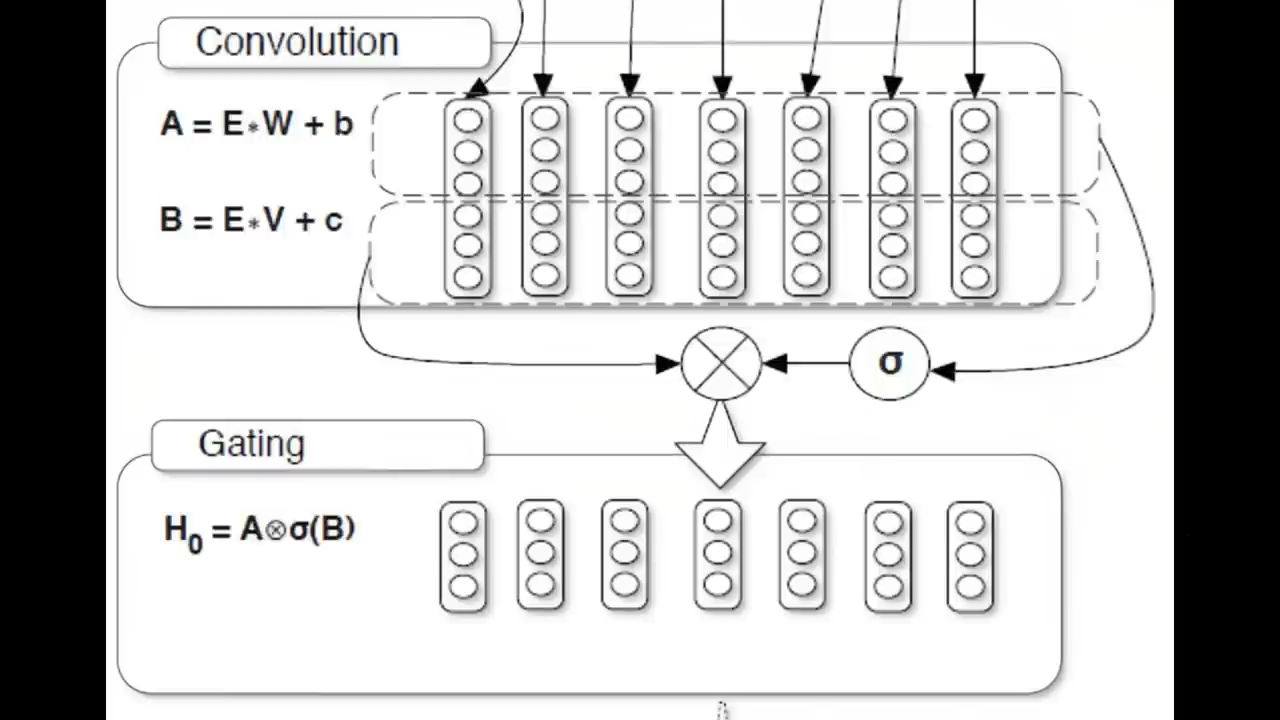
门控线性单元GLU
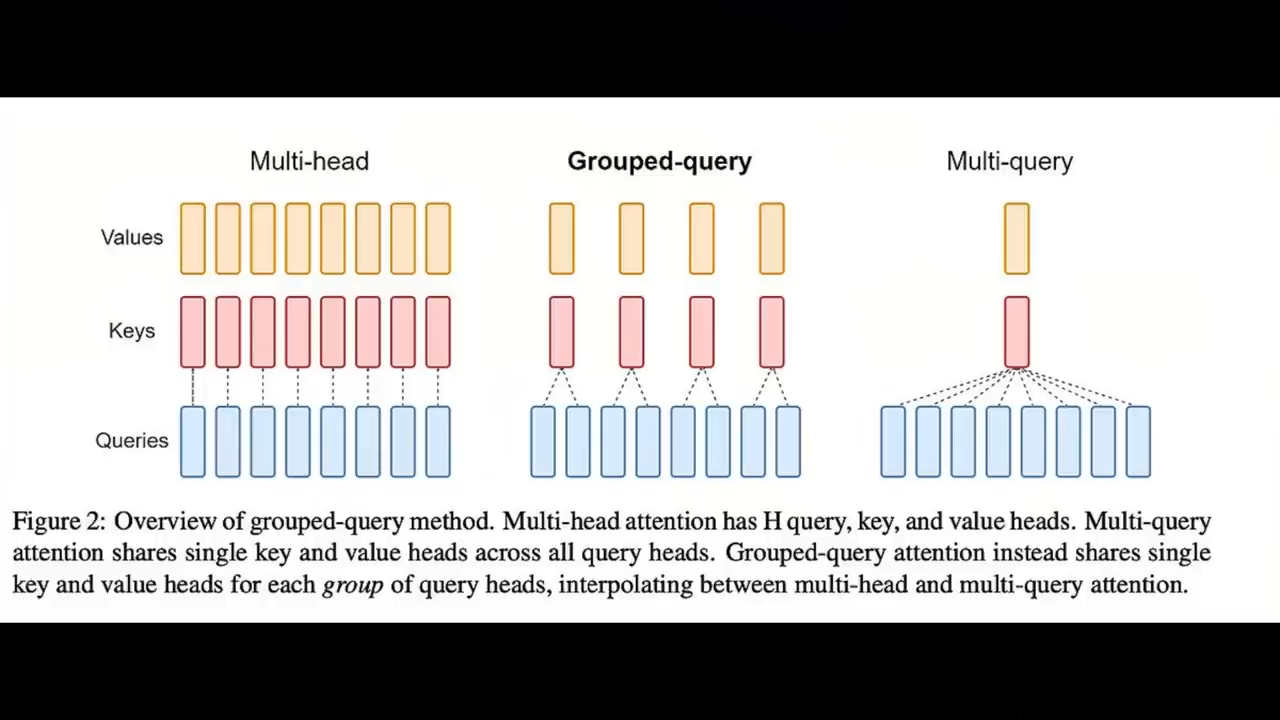
分组查询注意力GQA
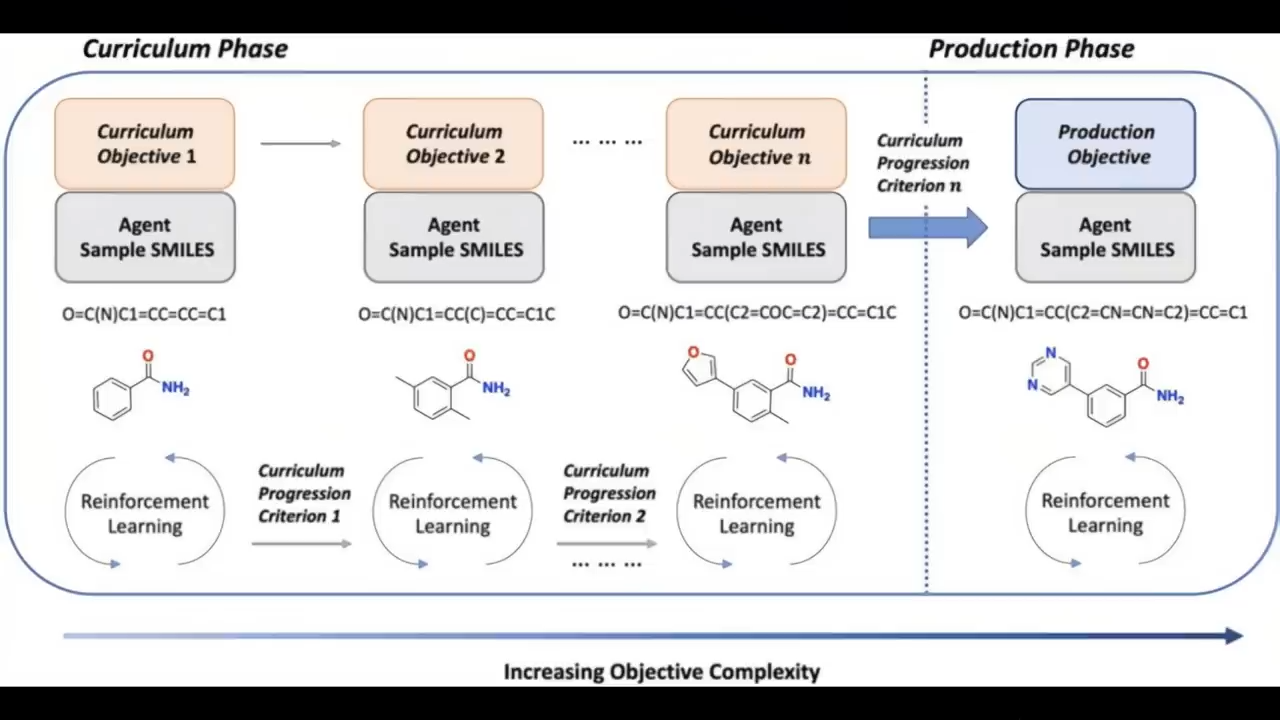
课程学习curriculum learning

tiktoken项目中提供的GPT-4分词器
在推理速度上
DBRX比LLaMA2-70B大约快2倍;
从参数总数和激活参数来看
DBRX大约只有Grok-1的40%大小
Databricks也提供了API的服务
在8位量化的情况下
DBRX预计可以每秒处理高达150个tokens的吞吐量
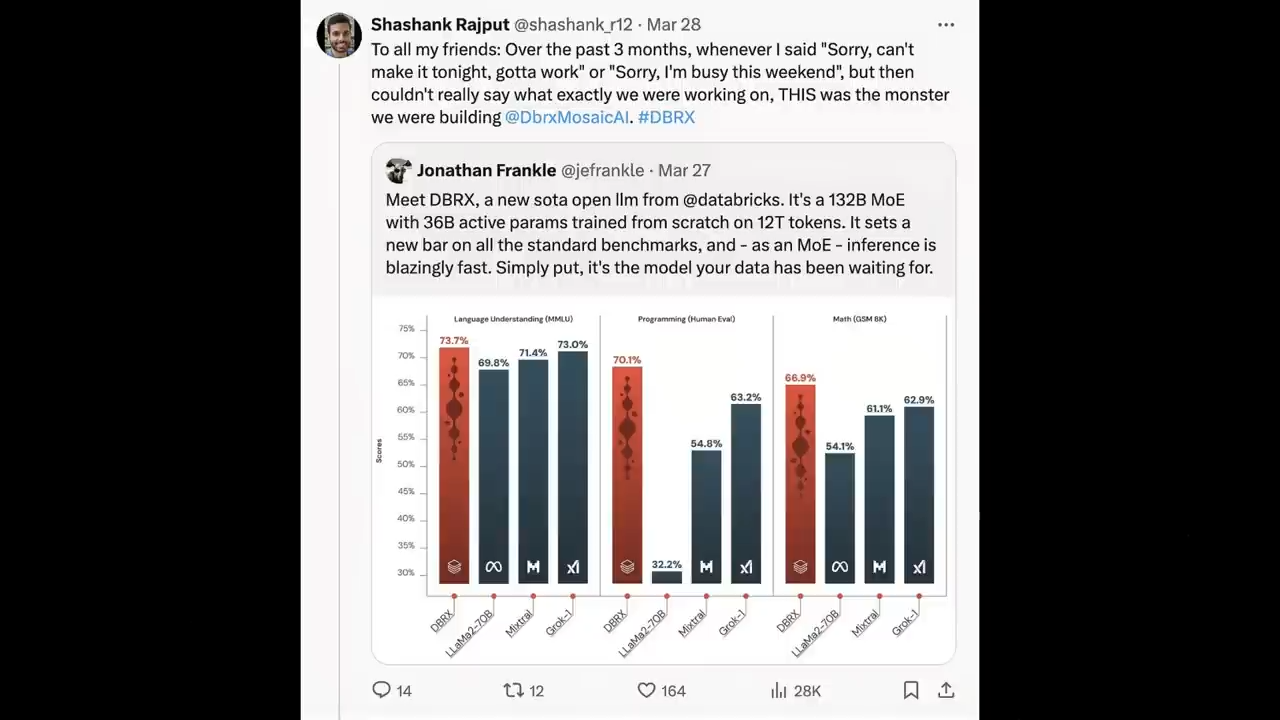
在与LLaMa 2-70B、Mixtral和Grok-1的对比中
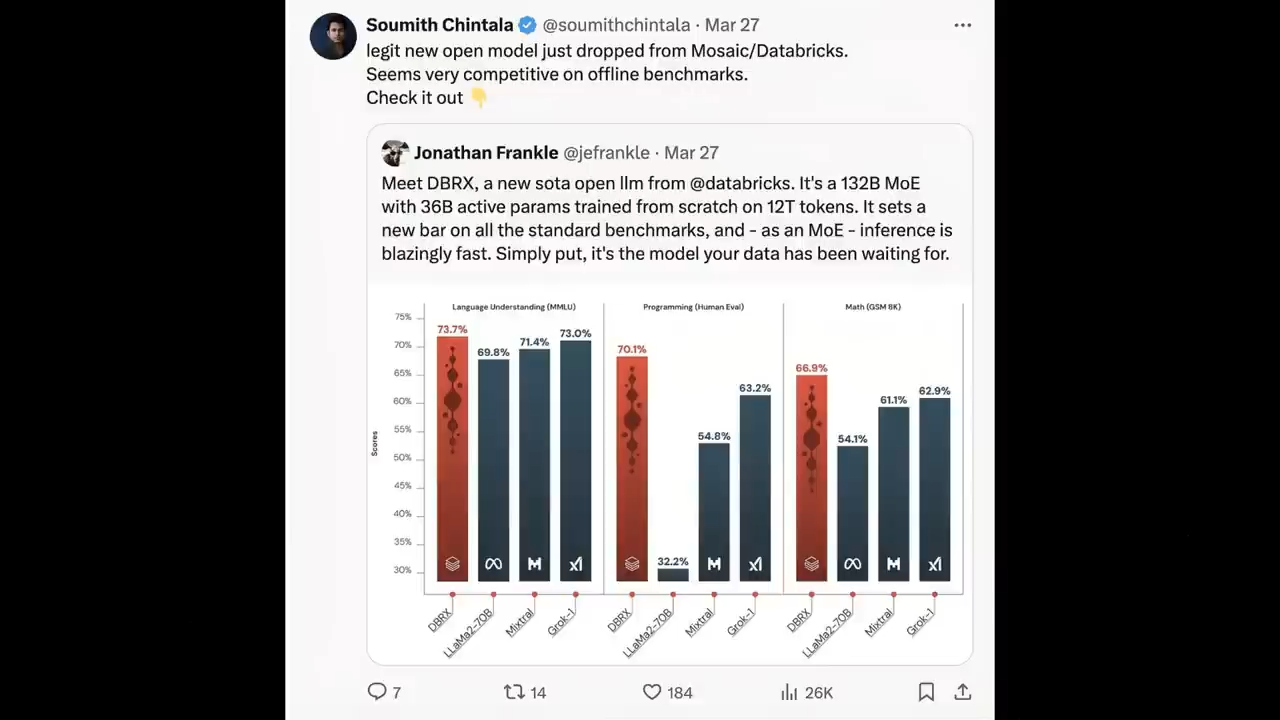
可以看到DBRX在语言理解 (MMLU)、编程 (HumanEval) 和数学 (GSM8K) 等方面
都有较大优势

同样被DBRX击败的还有ChatGPT3.5
Databricks认为这可以加速
企业内部开源模型取代专有模型的趋势
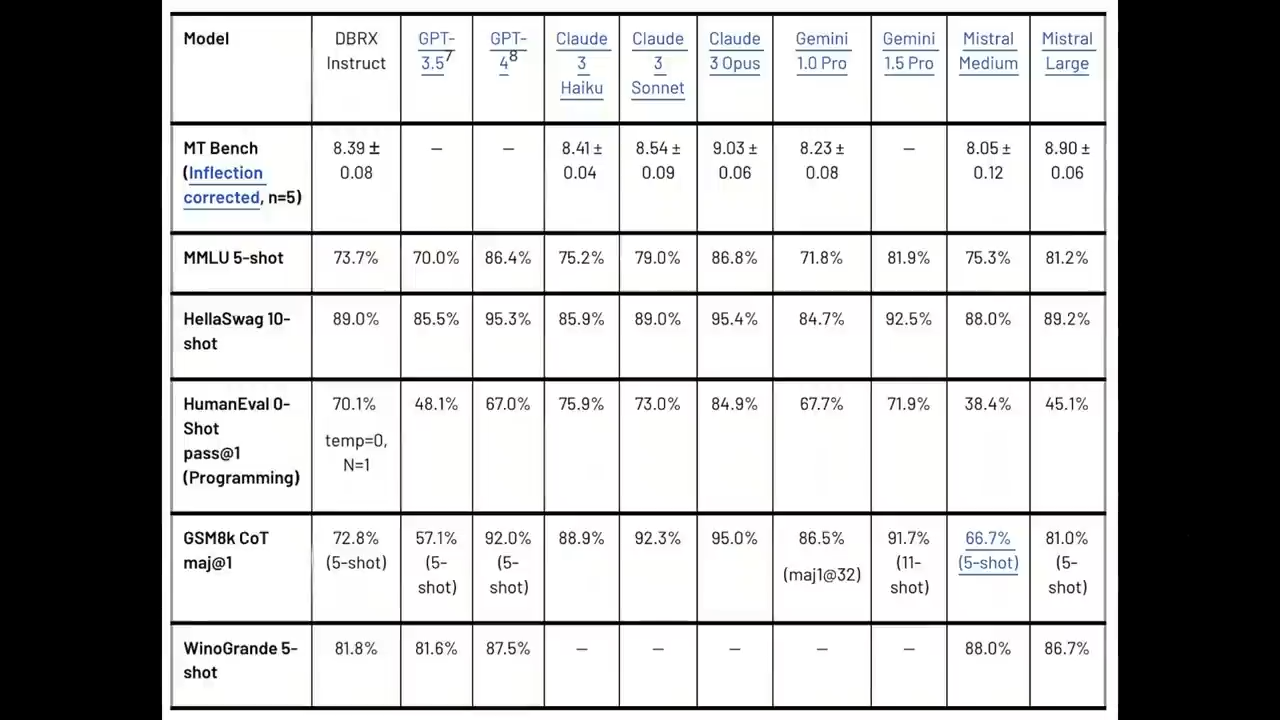
详细的评测对比结果
下面我们来看一些详细的评测对比结果
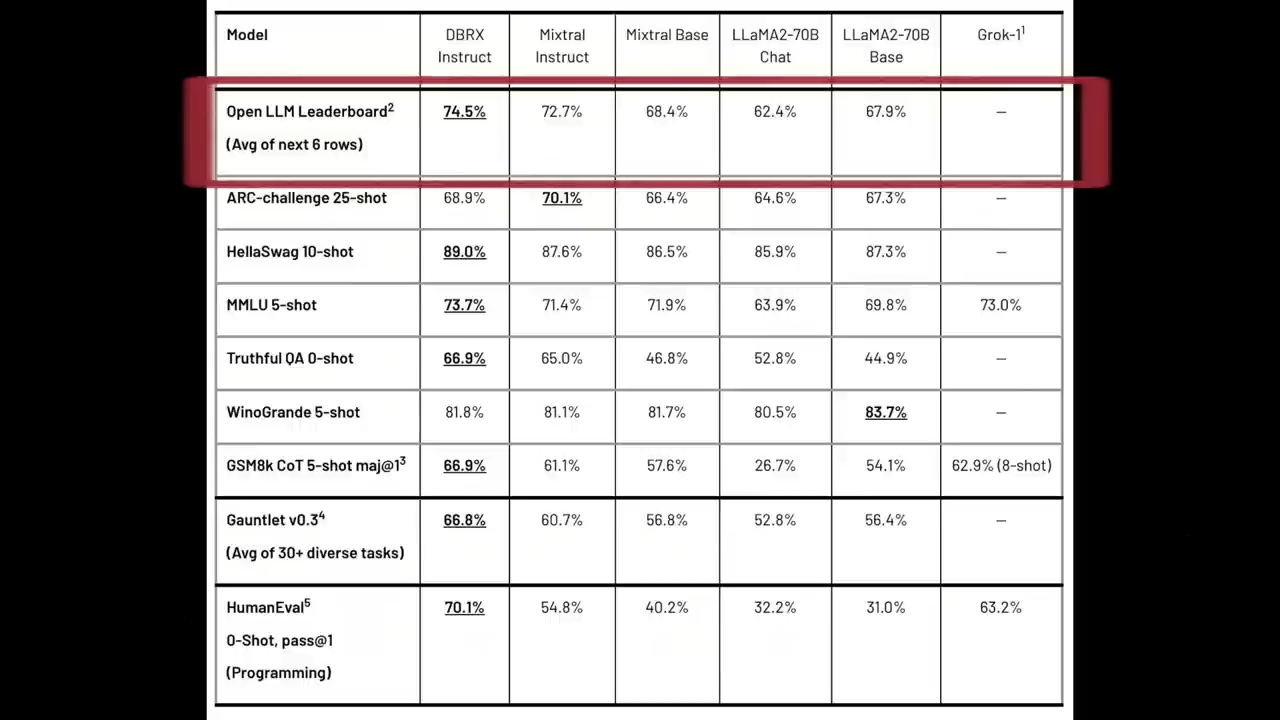
在综合基准测试上
DBRX的“微调版”Instruct
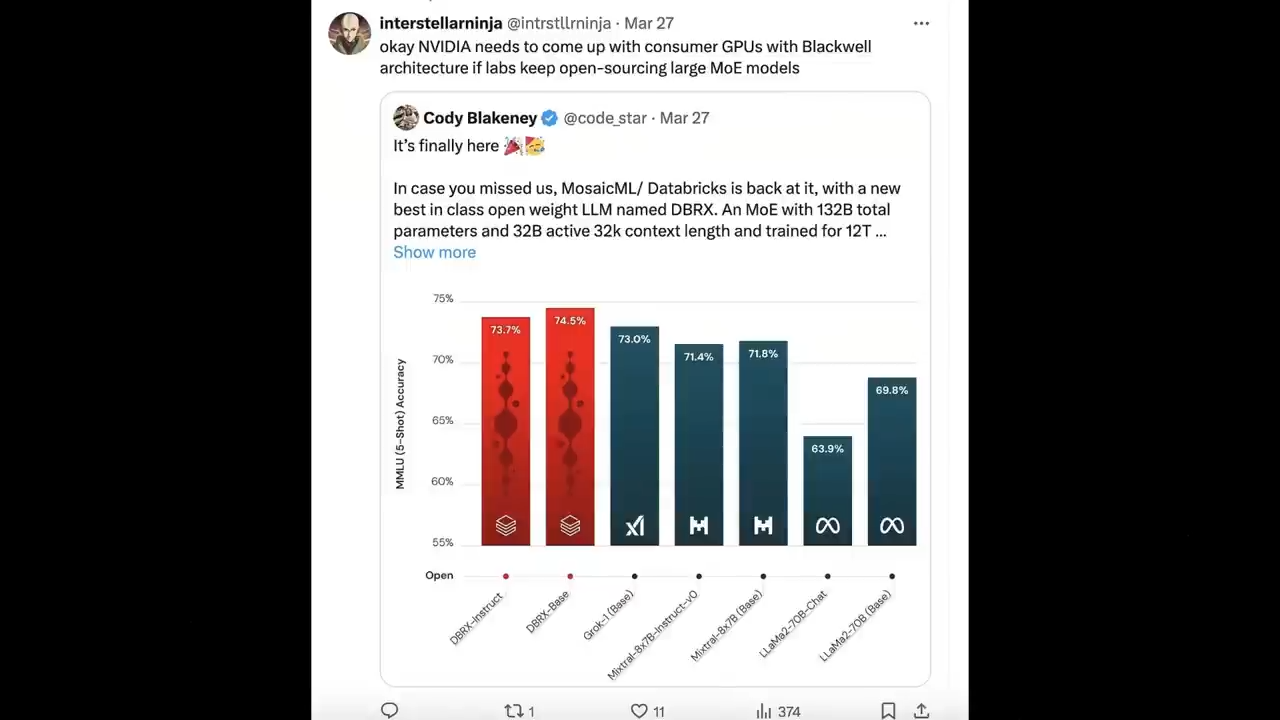
在Hugging Face Open LLM Leaderboard这个复合基准测试中
取得了最高分,得分达到了 74.5%,
远高于第二名Mixtral Instruct的72.7%。
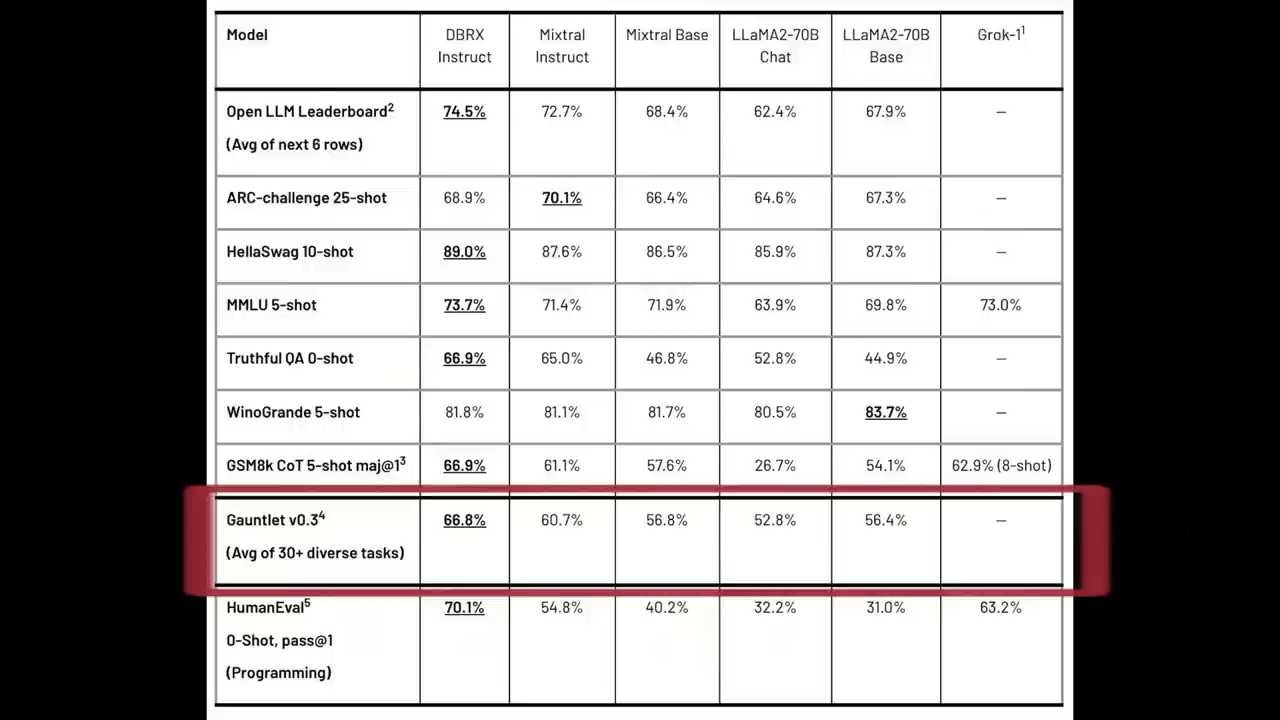
在Databricks Model Gauntlet这套包含了超过30项任务、横跨世界知识、常识推理、语言理解、阅读理解、符号问题解决和编程等六个领域的评估套件中
DBRX Instruct再次领先
得分为66.8%,
相比第二名Mixtral Instruct的60.7%有着显著优势
在编程和数学相关的任务上
DBRX Instruct展现了尤为强大的能力
例如
在HumanEval这个评估代码质量的任务上
正确率达到70.1%,
比Grok-1的63.2%高出约7个百分点
比Mixtral Instruct的54.8%高出约15个百分点
并超过了所有被评估的LLaMA2-70B变体

在GSM8k数学问题解决测试中
DBRX Instruct也取得了最优成绩66.9%,
胜过Grok-1的62.9%和Mixtral Instruct的61.1%,
以及其他LLaMA2-70B变体
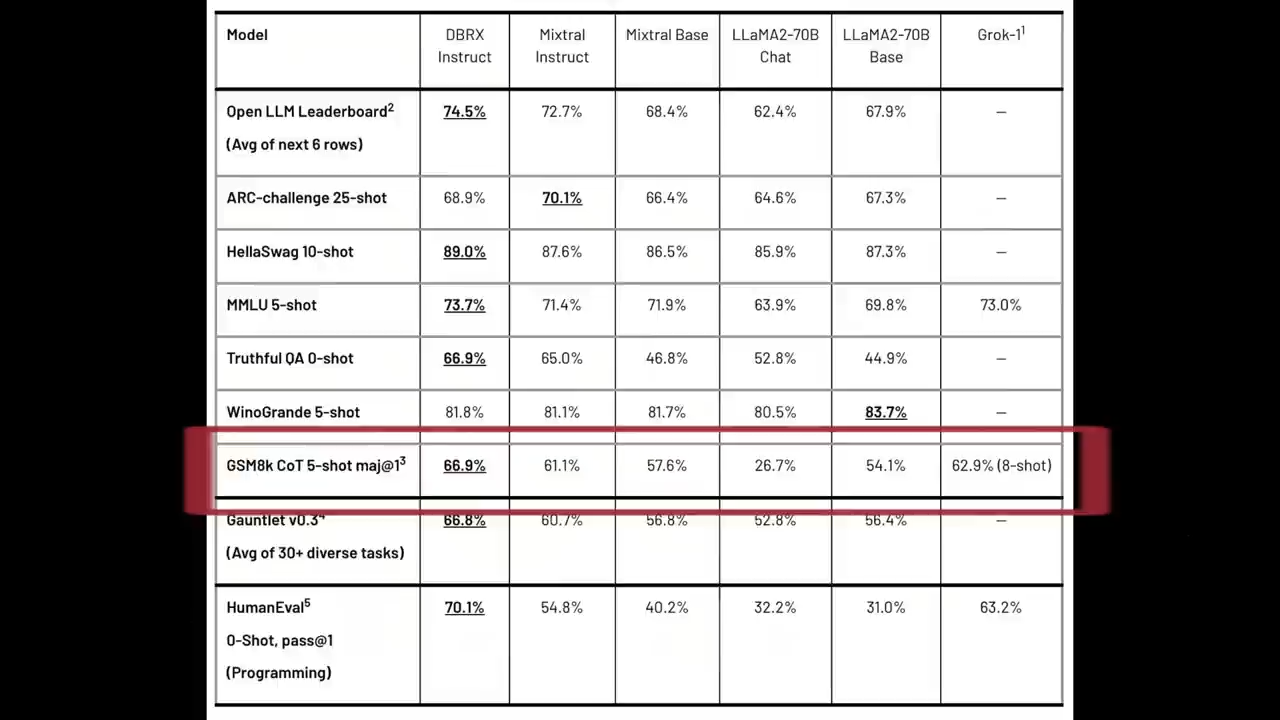
值得注意的是
尽管Grok-1的参数数量是DBRX Instruct的2.4倍
但是在编程和数学任务上
DBRX Instruct仍能保持领先地位
甚至在针对编程任务专门设计的CodeLLaMA-70B Instruct模型之上
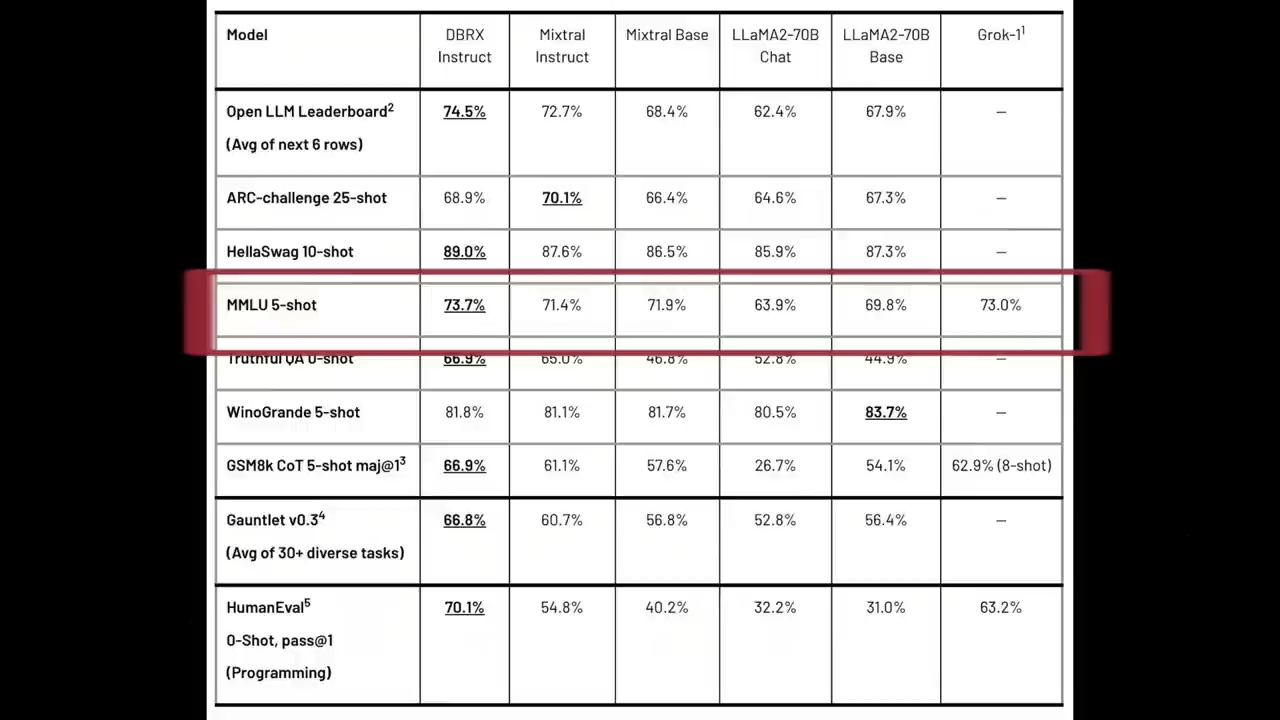
在大规模多任务语言理解数据集MMLU上
DBRX Instruct继续展示出顶级的性能
得分高达73.7%,
超过了进行对比的所有其他模型
不过在实测之前
还无法完全证明它的中文水平究竟如何
DBRX对阵开源模型确实占据上风
如果让它去打当前的“绝代双骄”,
GPT-4和Claude-3呢?
Databricks针对几大闭源模型不仅做了相关测评
而且还很详尽
在几乎所有的基准测试中
DBRX都优于或者与GPT-3.5持平

对比Gemini 1.0 Pro
DBRX赢得了Inflection Corrected MTBench、MMLU、HellaSwag和HumanEval这几个基准
但是Gemini 1.0 Pro在GSM8k测试中表现更强
这意味着在某些特定类型的数学问题解决上
Gemini 1.0 Pro可能更具优势
对比Mistral Medium
DBRX在HellaSwag上的得分相似
两者的推理能力五五开
Winogrande和MMLU这两项语言类的测试全都是Mistral Medium占据优势;
而在HumanEval、GSM8k 以及Inflection Corrected MTBench这些基准上
DBRX Instruct则获得了更高的分数
所以DBRX还是更擅长编程和数学推理一点
针对上下文窗口的评测
GPT-4 Turbo还是杀疯了
值得一提的是DBRX Instruct在所有上下文长度和序列的评测中
都比GPT-3.5 Turbo表现更好

另外
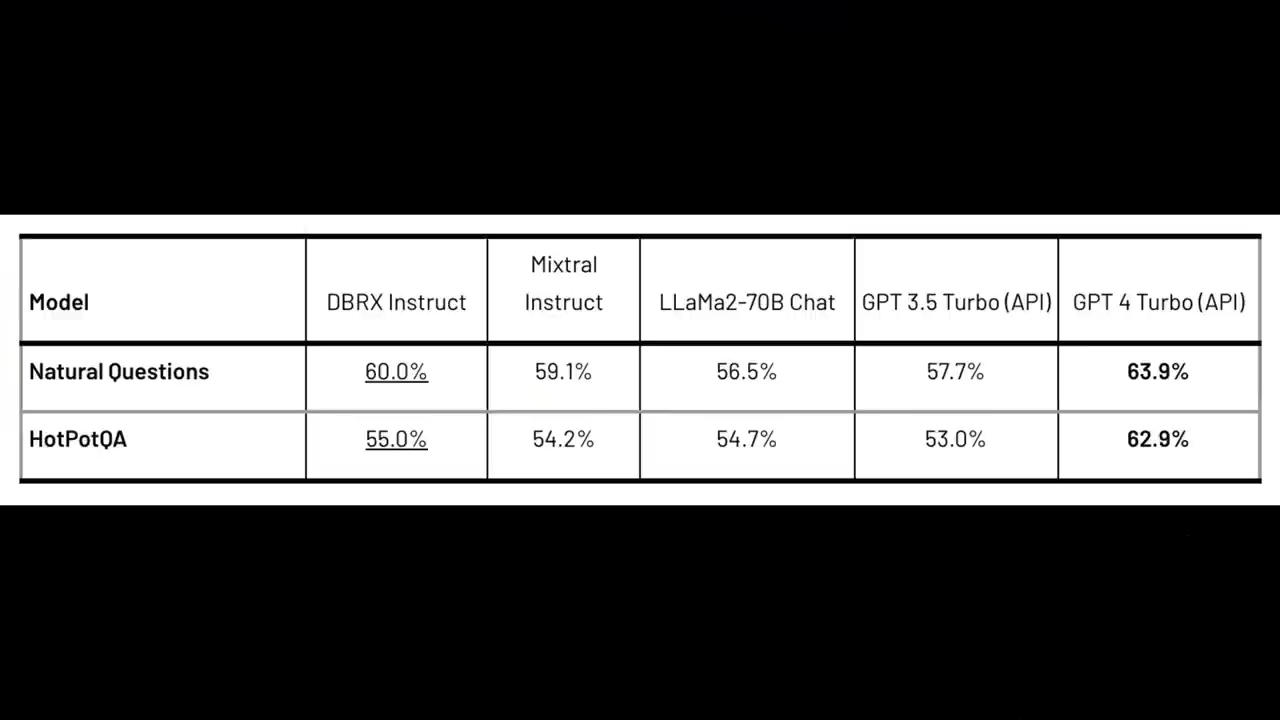
Databricks还做了检索增强生成RAG技术相关的测试
这是当前最火的大模型应用方案
在Natural Questions和HotPotQA这两项基准测试上
除了GPT-4 Turbo
DBRX Instruct都能打得过
在训练效率方面
研究人员发现MoE模型在训练的计算效率方面
有实质性的改进
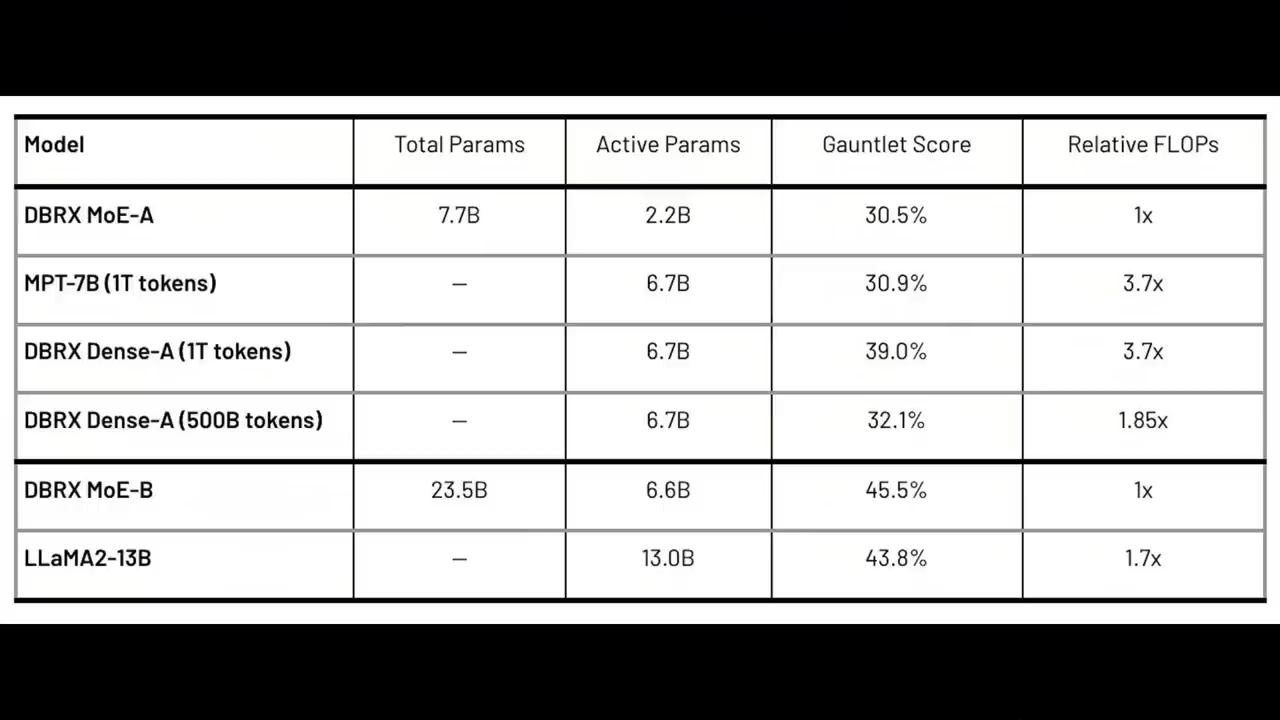
比如
训练DBRX系列中较小的成员DBRX MoE-B
总参数为23.5B,活跃参数为6.6B时
所需的Flop比LLaMA2-13B少1.7倍
就可以在Databricks Gauntlet上达到45.5%的得分
DBRX MOE-B包含的有效参数也是LLaMA2-13B的一半
从整体上看
端到端的大语言模型预训练pipeline
在过去十个月中的计算效率
提高了将近4倍
2023年5月5日
Databricks发布了MPT-7B
这是一个在1T token上训练的7B参数模型
在Databricks LLM Gauntlet上得分为30.9%。
而DBRX系列中名为DBRX MoE-A的
总参数为7.7B
活跃参数为2.2B
得分为30.5%,
而FLOPS减少了3.7倍
这种效率的提升是一系列优化的结果
包括使用MoE架构、网络的其他架构优化、更好的优化策略、更好的分词
以及更好的预训练数据
单独来看
更好的预训练数据对模型质量有很大的影响
研究人员在1T token的DBRX Dense-A数据上训练了7B模型
在Databricks Gauntlet上得分39.0%,
而MPT-7B为30.9%。

研究者估计
全新的预训练数据至少比用于训练MPT-7B的数据高出2倍
换句话说,只需一半的token数量
就可以达到相同的模型质量
研究人员随后通过在500B token上训练DBRX Dense-A确定了这一点
它在Databricks Gauntlet上的表现优于MPT-7B
达到32.1%。
当然,除了更好的数据质量外
token效率提高的另一个重要原因可能是GPT-4分词器
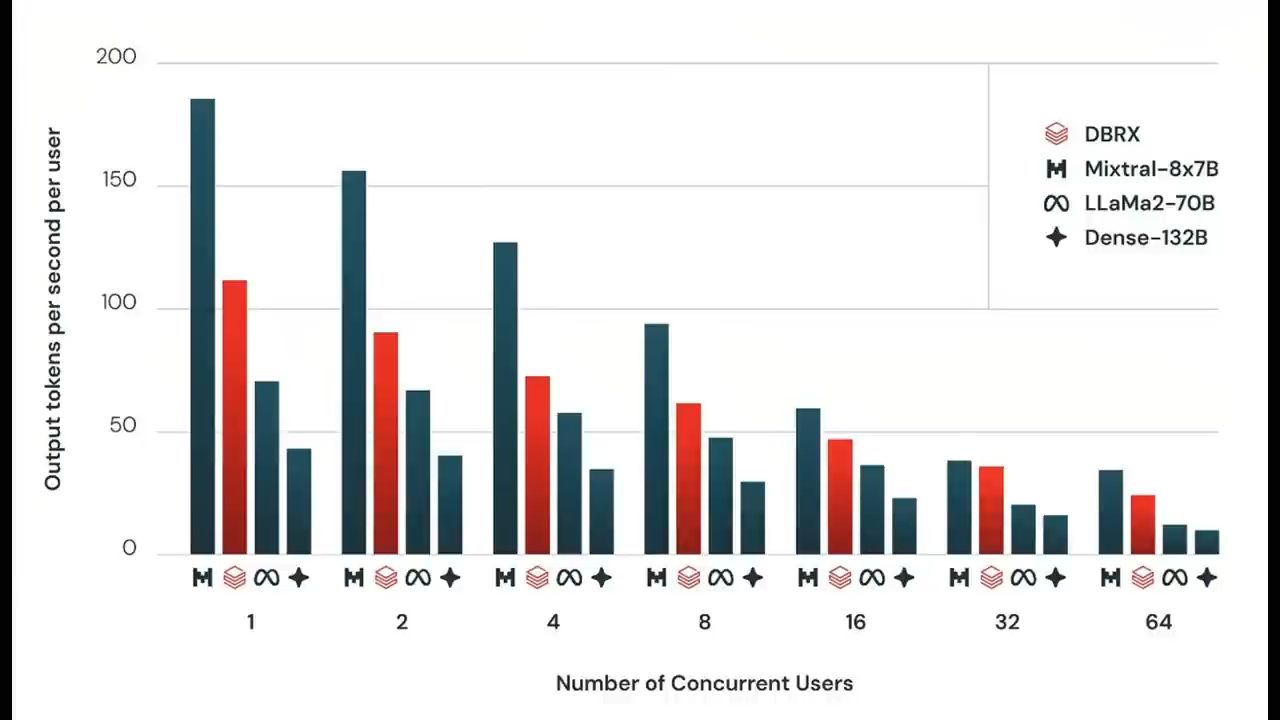
在推理效率方面,总的来说
MoE模型的推理速度比总参数显示的要快
这是因为它们对每个输入使用的参数相对较少
DBRX推理吞吐量
是132B非MoE模型的2-3倍
通常
推理效率和模型质量是相互矛盾的
也就是模型越大通常质量越高
但是模型越小推理效率越高
使用MoE架构可以在模型质量和推理效率之间
实现比密集模型更好的平衡
比如,DBRX的质量比LLaMA2-70B更高
但是由于活跃参数量大约是LLaMA2-70B的一半
DBRX推理吞吐量最多可以快2倍
而在经过优化的8位量化模型服务平台上
Databricks Foundation Model API的推理吞吐量
每秒多达150个token
而在NVIDIA TensorRT-LLM的16位精度环境下
DBRX的推理效率也非常稳定
在如此优异的成绩面前
很多行业专家也是发表了自己的观点
Pytorch之父苏米特·金塔拉Soumith Chintala对DBRX就非常看好

Yandex的首席隐私官伊万·切列夫科Ivan cherevko认为
从Mixtral、到Grok-1,再到DBRX
MoE架构的模型正在占领开源界


而Databricks的员工激动地表示
过去3个月
朋友们周末约我,我都说这周不行
我有事
但是又不能说有啥事的日子
终于结束了
DBRX就是我们加班加点搞出来的一头「怪兽」。
还有网友表示
如果实验室继续开源大型MoE模型
英伟达可能就需要推出最强Blackwell架构的消费级GPU了
不得不说
DBRX现在为开源大语言模型
设立了一个全新的技术标准
通过开源DBRX
Databricks也加入了Meta对抗OpenAI和谷歌的开源大潮
不过
Meta并没有公布Llama 2模型的一些关键细节
而Databricks会将最后阶段做出关键决策的过程全部公开
要知道
训练DBRX的过程,耗费了将近一千万美元
Databricks选择开源的理由是
尽管谷歌这些巨头在过去的一年里都部署了AI
但是行业内的许多大公司
还没有在自己的数据上广泛使用大模型
在Databricks看来
金融、医药等行业的公司
渴望类似ChatGPT的工具
但是又担心将敏感数据发到云上
而Databricks将为客户定制DBRX
或者从头为他们的业务量身定做
对于大公司来说
构建DBRX这种规模模型的成本非常合理
这就是Databricks看中的商机
为此
Databricks去年7月收购了初创公司MosaicML
引入了弗兰克尔在内的多名技术人才
而在这之前
这两家公司内部都没有人构建过如此大的模型
在DBRX的负责人弗兰克尔看来
大语言模型重要的不仅仅是规模
怎么样让成千上万台计算机
通过交换机和光缆巧妙地连接在一起
并且运转起来更具有挑战性
而MosailML的员工都是这门晦涩学问的专家
因此Databricks去年收购它的时候
对它的估值高达13亿美元
但是显然这笔生意是超值的

DBRX在编码基准测试上的表现
甚至连弗兰克尔自己都没有想到
以至于打赌输了
要去把头发染成蓝色

最后还有一个问题
就是开源模型的风险问题
DBRX开源之后
任何人都可以使用或者修改
这是否会带来不可预知的风险
比如说被网络犯罪或者生化武器滥用呢
databricks表示
已经对模型进行了全面的安全测试
Eleuther AI的执行主任Stella Biderman也说

几乎没有证据表明
开源会增加模型的安全风险
所以大家抓紧时间试用起来吧
相信国内很多大模型又要更新一波了














 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









