







 本文探讨了深度学习如何推动语音识别成为主流,详细解释了从声波数字化到预处理,再到使用循环神经网络进行字符预测的过程,以及语音识别系统面临的挑战和构建高质量系统所需的大量训练数据。
本文探讨了深度学习如何推动语音识别成为主流,详细解释了从声波数字化到预处理,再到使用循环神经网络进行字符预测的过程,以及语音识别系统面临的挑战和构建高质量系统所需的大量训练数据。
语音识别正在侵入我们的生活。它内置于我们的手机、游戏机和智能手表中。它甚至使我们的房屋自动化。你只需 50 美元,你就可以获得一个 Amazon Echo Dot——一个神奇盒子,你只需大声说出你的需求就可以帮你订购披萨、获取天气预报甚至购买垃圾袋。

但是语音识别已经存在了几十年,那么为什么它现在才成为主流呢?原因是深度学习最终使语音识别足够准确,可以在精心控制的环境之外发挥作用。
Andrew Ng 早就预测,随着语音识别准确率从 95% 提高到 99%,它将成为我们与计算机交互的主要方式。这个想法是,这 4% 的准确率差距是令人讨厌的不可靠和非常有用之间的区别。感谢深度学习,我们终于达到了顶峰。
让我们学习如何使用深度学习进行语音识别!
机器学习并不总是一个黑匣子
如果您知道神经机器翻译的工作原理,您可能会猜到我们可以简单地将录音输入神经网络并训练它生成文本:
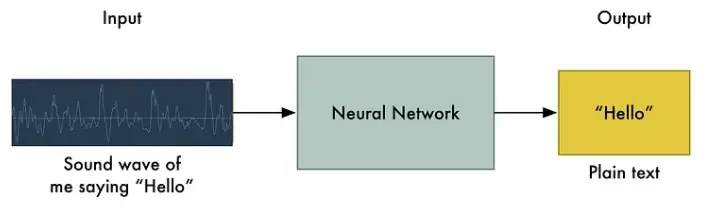
最大的问题是语音速度不同。一个人可能会说“hello!” 很快,另一个人可能会说“heeeelllllllllllllooooo!” 非常缓慢,产生一个包含更多数据的更长的声音文件。两个声音文件都应该被识别为完全相同的文本——“hello!” 事实证明,将各种长度的音频文件自动对齐到一段固定长度的文本非常困难。
为了解决这个问题,除了深度神经网络之外,我们还必须使用一些特殊的技巧和额外的进动。让我们看看它是如何工作的!
把声音变成比特流
语音识别的第一步很明显——我们需要将声波输入计算机。
在前面的学习中,我们学习了如何拍摄图像并将其视为数字数组,以便我们可以直接输入神经网络进行图像识别:

但是声音是以波的形式传播的。我们如何将声波转化为数字?让我们用这段我说“hello”的声音片段:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









