






引言
气候变化是当今世界面临的最严峻挑战之一。二氧化碳(CO2)等温室气体的排放与全球气温的上升密切相关。为了更好地理解CO2排放对气候的影响,我们可以使用数据可视化工具来探索历史趋势,并通过机器学习方法进行预测,为未来气候政策的制定提供参考。
在本文中,我们将展示如何通过Python及其可视化工具来分析全球CO2排放,并引入一些机器学习技术用于回归预测未来排放趋势。
代码地址 :源码地址![]() https://www.yuque.com/yuqueyonghuik8ysz/gxfuvi/ygdw23mdbcueqa3t?singleDoc#
https://www.yuque.com/yuqueyonghuik8ysz/gxfuvi/ygdw23mdbcueqa3t?singleDoc#
数据可视化:全球CO2排放趋势
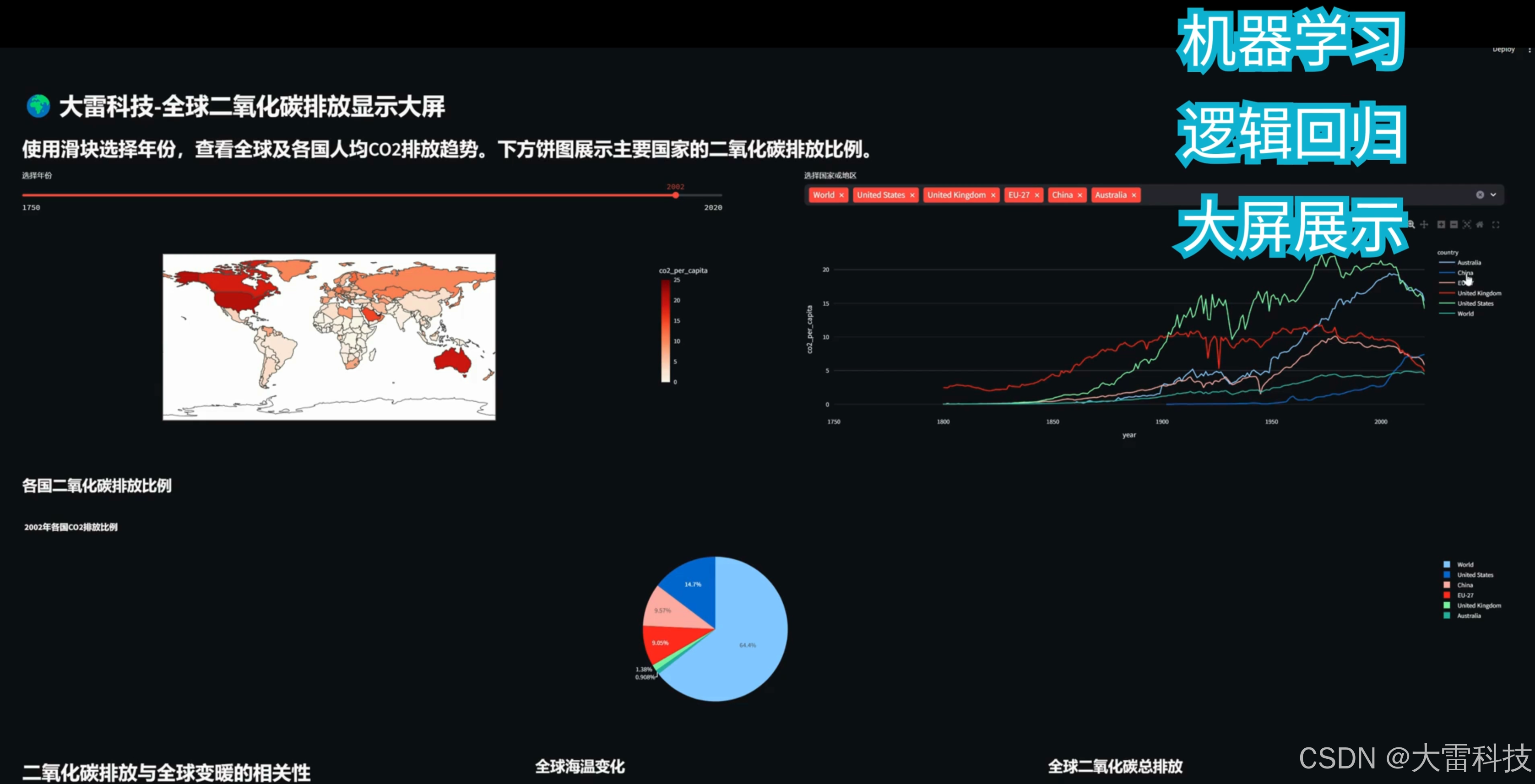
首先,我们通过一个交互式的可视化仪表盘展示了全球二氧化碳排放的历史数据。通过选择不同的年份和国家,用户可以查看人均二氧化碳排放以及全球CO2排放的变化情况。
可视化组件:
-
世界CO2排放地图:这张地图展示了每个国家在不同年份的人均二氧化碳排放量。用户可以通过滑动条选择特定年份,查看全球各国的CO2排放情况。这有助于识别出哪些国家是最大的排放源,以及如何随时间推移发生变化。
-
CO2排放折线图:通过多选框,用户可以选择多个国家,查看这些国家在不同年份的人均CO2排放趋势。这使我们能够轻松比较多个国家在历史上的排放数据。
-
饼状图:我们还展示了全球主要国家CO2排放的比例,通过可视化不同国家的相对贡献,可以直观展示哪些国家是全球排放的主要来源。
-
全球CO2总排放图:这张折线图展示了从1850年至今全球二氧化碳总排放量的变化,突显了工业革命以来排放量的快速增长。
-
海温变化图:为了展示CO2排放与全球变暖的相关性,我们还加入了全球海洋温度变化的散点图,可以看到自20世纪以来温度的显著上升与CO2排放的增长趋势高度相关。
机器学习:预测未来的CO2排放趋势
虽然可视化可以帮助我们了解历史数据,但预测未来排放趋势同样至关重要。这里我们引入机器学习中的回归模型,利用历史数据来预测未来的全球二氧化碳排放。
机器学习模型选择
-
线性回归模型:线性回归是最常见的回归模型之一。它假设因变量(CO2排放)与自变量(时间)之间存在线性关系。我们可以使用全球CO2排放的历史数据来拟合线性回归模型,并预测未来几十年的排放趋势。
-
多项式回归模型:由于CO2排放随时间并不完全线性,我们还可以考虑多项式回归。通过增加自变量的阶数(例如,平方项),我们可以更好地捕捉排放增长的非线性趋势。
-
随机森林回归:为了捕捉更复杂的趋势和噪声,我们还可以使用随机森林回归。这是一种基于决策树的集成学习算法,适用于高维、复杂数据的建模。
数据处理与模型训练
我们将数据按年份划分为训练集和测试集。然后,使用不同的回归模型对数据进行拟合,并评估它们的预测精度。评估指标可以选择均方误差(MSE)或决定系数(R²)等。
预测结果
在训练完成后,我们可以使用模型对未来几年乃至几十年的CO2排放进行预测。通过将预测结果与历史数据进行对比,我们可以评估不同政策或技术进步对排放的潜在影响。
示例代码:CO2排放预测
以下是如何利用Python和机器学习库(如 scikit-learn)对CO2排放进行回归预测的示例代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# 加载数据
df_co2 = pd.read_csv('owid-co2-data.csv')
# 过滤全球数据
df_world = df_co2[df_co2['country'] == 'World']
X = df_world[['year']]
y = df_world['co2']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 线性回归模型
linear_model = LinearRegression()
linear_model.fit(X_train, y_train)
# 多项式回归模型(2阶)
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X_train)
poly_model = LinearRegression()
poly_model.fit(X_poly, y_train)
# 预测
y_pred_linear = linear_model.predict(X_test)
y_pred_poly = poly_model.predict(poly.transform(X_test))
# 评估
mse_linear = mean_squared_error(y_test, y_pred_linear)
mse_poly = mean_squared_error(y_test, y_pred_poly)
print(f"线性回归MSE: {mse_linear}")
print(f"多项式回归MSE: {mse_poly}")
# 可视化
plt.scatter(X_test, y_test, color='black', label='实际值')
plt.plot(X_test, y_pred_linear, color='blue', label='线性回归预测')
plt.plot(X_test, y_pred_poly, color='red', label='多项式回归预测')
plt.xlabel('年份')
plt.ylabel('全球CO2排放')
plt.title('CO2排放预测')
plt.legend()
plt.show()
在上面的代码中,我们使用了线性回归和多项式回归来预测全球CO2排放。根据不同模型的表现,我们可以选择最合适的模型来进行未来趋势预测。
结论
通过数据可视化和机器学习模型的结合,我们不仅可以分析过去全球二氧化碳排放的历史趋势,还能对未来的排放进行预测。可视化为我们提供了直观的历史数据展示,而机器学习则帮助我们探索未来的可能性。这些分析对于应对气候变化和制定有效的减排政策至关重要。
如果您对数据可视化、机器学习或气候变化分析感兴趣,欢迎尝试使用这些技术探索更多的气候数据。通过数据的力量,我们可以为保护地球做出更好的决策。
参考资料:
- 数据来源:Our World in Data (OWID)
- 代码库:Python, Streamlit, Plotly, scikit-learn


















 9905
9905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









