







1.显存分配(1)
cudaMallocManaged(& 地址, size_t 参数)
Cpu、GPU同步cudaDeviceSynchronize()
2.线程够的时候,线程标号;
int i = blockIdx.x * blockDim.x + threadIdx.x;
线程固定、任务溢出时,跨步循环
跨步循环:
int i = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gridDim.x * blockDim.x;
for (int j = i; j < N; j = j + stride) //跨步循环
a[j] *= 2;
上取整
(总数+周期-1)/周期
Note: /为整除操作(c语言)
3.CUDA内置异常处理
cudaGetLastError()
cudaGetErrorString(错误)
4.kernel函数参数可三维输入
使用dim3 a(, , ,);//每一维度都可以使用线程标号:blockDim.x * blockIdx.x + threadIdx.x
5.性能分析——nsight systems
命令行语句:nsys profile --stats=true ./***.exe
查看报告nsys-rep
6.获取GPU属性
GPU流多处理器SM会在名为warp的线程块内创建、管理、调度和执行包含32个线程的线程组。所以线程数选32的倍数最佳!!!
int id;
cudaGetDevice(&id);
cudaDeviceProp props;
cudaGetDeviceProperties(&props,id);
printf("device id: %d \n sms: %d \n capability major: %d \n capability minor: %d \n warp size: %d \n", id,props.multiProcessorCount,props.major, props.minor, props.warpSize);
7.显存分配(2)- 进行显存或内存预取,减少CPU-GPU和GPU-CPU内存分配的缺页
cudaMemPrefetchAsync(a,size,id);
手动分配内存
cudaMallocHost(&c_cpu, size);
cudaMallocHost(&c_gpu_cpu, size);
cudaMemcpy(c_gpu_cpu,c_gpu,size,cudaMemcpyDeviceToHost);
8.Cuda的流
(一)默认流:
在CUDA编程中,流是由按顺序执行的一系列命令构成。
在CUDA应用程序中,核函数的执行以及一些内存传输均在CUDA中进行。
(二)为有效利用CUDA流,流行为的规则:
给定流中的所有操作会顺序执行;
不同非默认流中之间操作无法按规定顺序执行;
默认流具有阻断能力,会等待已在运行的所有流完成当前操作后运行,但运行时阻碍其他流运行。
(三)核中使用流
cudaStream stream;//声明
cudaStreamCreate(&stream);//创建
Somekernel<<<number_of_blocks,threads_per_block,0,stream>>>();//第三个参数允许程序员提供共享内存中为每个内核启动动态分配的字节数
cudaStreamDestroy(stream);//销毁流
(四)在显存中使用
cudaMemcpyAsync可以从主机到设备或从设备到主机异步复制内存。
note:与核函数执行类似,cudaMemcpyAsync在默认情况下仅相对于主机是异步的。默认情况下,它在默认流中执行,因此对于GPU发送的其他CUDA操作而言,它是阻塞操作。
cudaMemcpyAsync函数将非默认流作为可选的第五个参数,通过其传递非默认流,可以将内存传输与其他非默认流中发生的其他cuda操作并发。
可以实现显存和核函数并行。
9.共享内存
全局内存:设备上任何线程或快都可使用该内存,其存续时间可贯穿应用程序的整个生命周期,且内存空间相对较大。
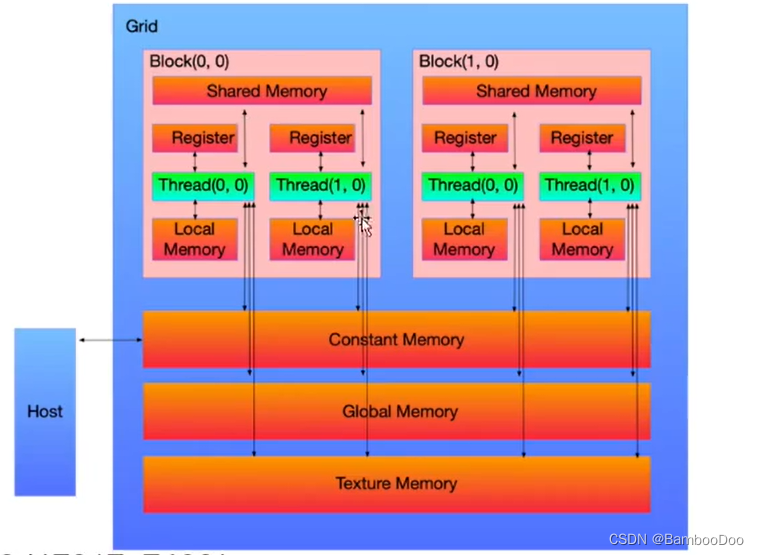
共享内存是GPU上可受用户控制的一级缓存。在一个SM中,存在着若干cuda core + DP(双精度计算单元) + SFU(特殊函数计算单元)+共享内存+常量内存+纹理内存。相对于全局内存,共享内存的方寸延迟较低,可以达到惊人的1.5TB/s。而全局内存大约只有150GB/s。(最新的NVLINK技术没有考虑在内)。因而共享内存的使用时性能提高的一个重要的因素。但是注意到,将数据拷贝到共享内存中也消耗了部分时间。因而,共享内存仅仅适合存在着数据的重复利用,全局的内存合并或者是线程之间有共享数据的时候,否则直接使用全局内存会更好一些。
cuda计算时间和带宽;可在共享内存中实现运算,再赋给CUDA最终输出,当实现类似矩阵转置的操作时可发现带宽降低














 7179
7179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









