







前言
今天给大家介绍一篇基于多视角多行为对比学习的文章,我们知道在推荐系统,经常会使用用户的行为序列来训练模型进而来预估用户诸如ctr之类的指标,那其实用户在一个产品上的行为是多种多样的,比如点击、收藏、购买甚至是负反馈,如果我们能够把这种多行为联合建模,那是不是会带来更多的增益呢?
同时在建模的时候,有多种方式,比如基于序列建模的,基于graph建模的;前者能够很好的学习用户的局部视角信息,后者则能够更好的关注全局视角信息。
总的来说,既要考虑用户不同行为之间的粗粒度共性,还有考虑不同行为之间的细粒度个性,同时还有不同视角下信息。
为了解决上诉问题,本次介绍的这篇paper是通过三个对比学习loss实现的并且开源了代码,具体来看看吧~
论文链接:https://arxiv.org/pdf/2203.10576.pdf
代码链接:https://github.com/wyqing20/MMCLR
方法
模型的总框架如下所示:
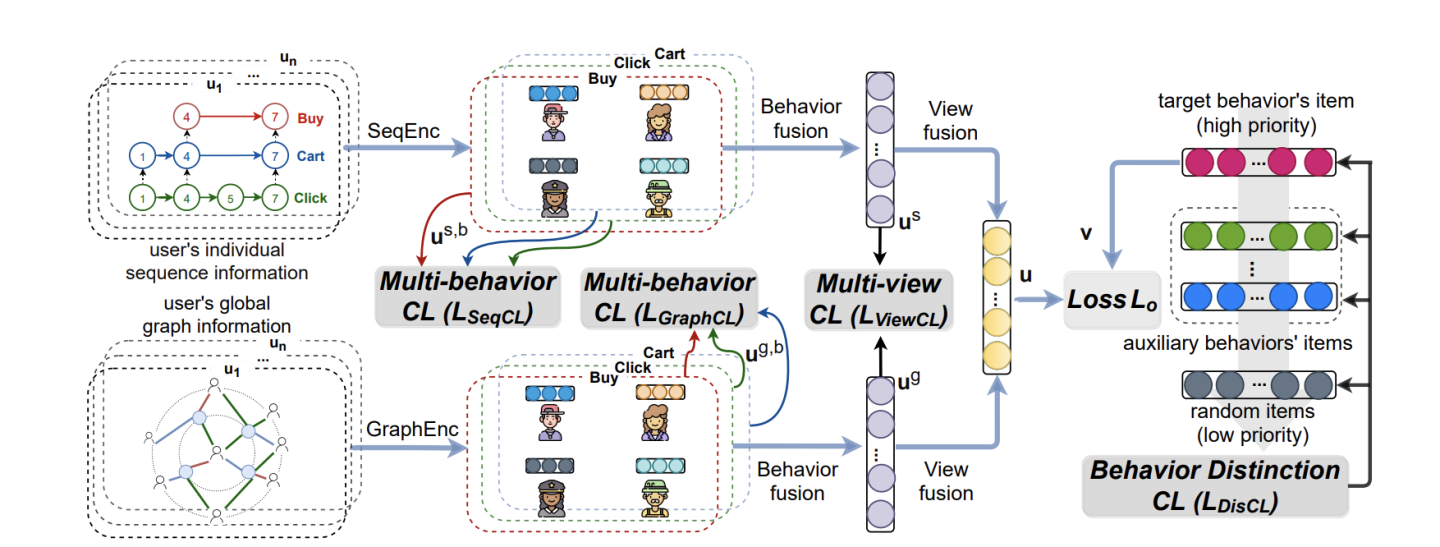
(1)特征表征
从上面图可以看到,输入的数据有两种,一种是代表用户个性视角的序列性,一种是全局视角的graph形式,序列编码SeqEnc和图编码GraphEnc可以采取任何已有的算法,其中论文中SeqEnc采用的是Bert4rec,GraphEnc采用的是lightGCN。
Multi-behavior Fusion是对用户多种行为的交互编码,具体的是讲所有行为emb过两层MLP,注意这里具体的应该是有两种Multi-behavior Fusion即一种是序列视角下的,一种是graph视角下的。Multi-view Fusion是对上述两种视角下的Multi-behavior Fusion再进行一次交互,具体的也是MLP层。
总结一下就是:Multi-view Fusion最后实际上能够得到两个Fusion的编码即user和item的。其中每个user在每个视角下都有Multi-behavior Fusion多行为编码,而item在每个视角下也都有自己的编码,只不过在graph下有聚合得到的编码而在序列视角下就是其自身。
(2)loss
loss这里从大的方面看是四个,一个是单纯的行为预测以及三个对比学习loss。重点看后面三个对比loss。
(a) 第一个loss比较容易想到,假设当前建模是预测用户的购买行为,那正样本就是具有购买行为的user-item pair,负样本就是随机抽样的pair,然后依据上述的Fusion的user和item的编码直接计算loss.
(b) 多行为对比学习loss:假设在序列视角下,同一个用户具有不同的行为,可以先验的知道同一用户的不同行为表示之间应当要比另一个用户的行为表示更加接近,看到没?对比学习loss是不是已经出来了?
(c) 多视角对比学习loss:这里的核心是同一用户不同视角下的行为表示应当比另一个用户的更为接近
(d) 这里的对比学习就更细粒度了,假设在电子商务场景有购买和点击行为,我们的最后目标其实是想要预测购买行为,那也就是说行为之间是有优先级的,假设在一个batch内,对于同一个用户来说,其user和购买的item距离是要小于其user和点击的item的距离的,其次再小于其user和随机抽取的item距离的。
看到这里,大家可以再仔细看看(d)和(a) 的不同,(a)是对具体某一个行为的预测建模,而(d)是对不同行为的预测loss进行排序建模。
最终的loss就是将上面所有的loss求和
实验
讲完了idea,下面我们来看看实际实验效果~
(1)数据集
作者这里使用了两个数据集Tmall和CIKM2019 EComm AI。每个数据集的都是user和item之间的交互,具体有三种行为:点击、加购物车和购买。
具体的,经过处理,Tmall包含22014个users和27155个items,83778 个购买行为, 44717加购物车行为和485483 个点击行为。CIKM2019 EComm AI包含23032个users和25054个items,100529 个购买行为, 38347 个加购物车行为和276750点击行为。
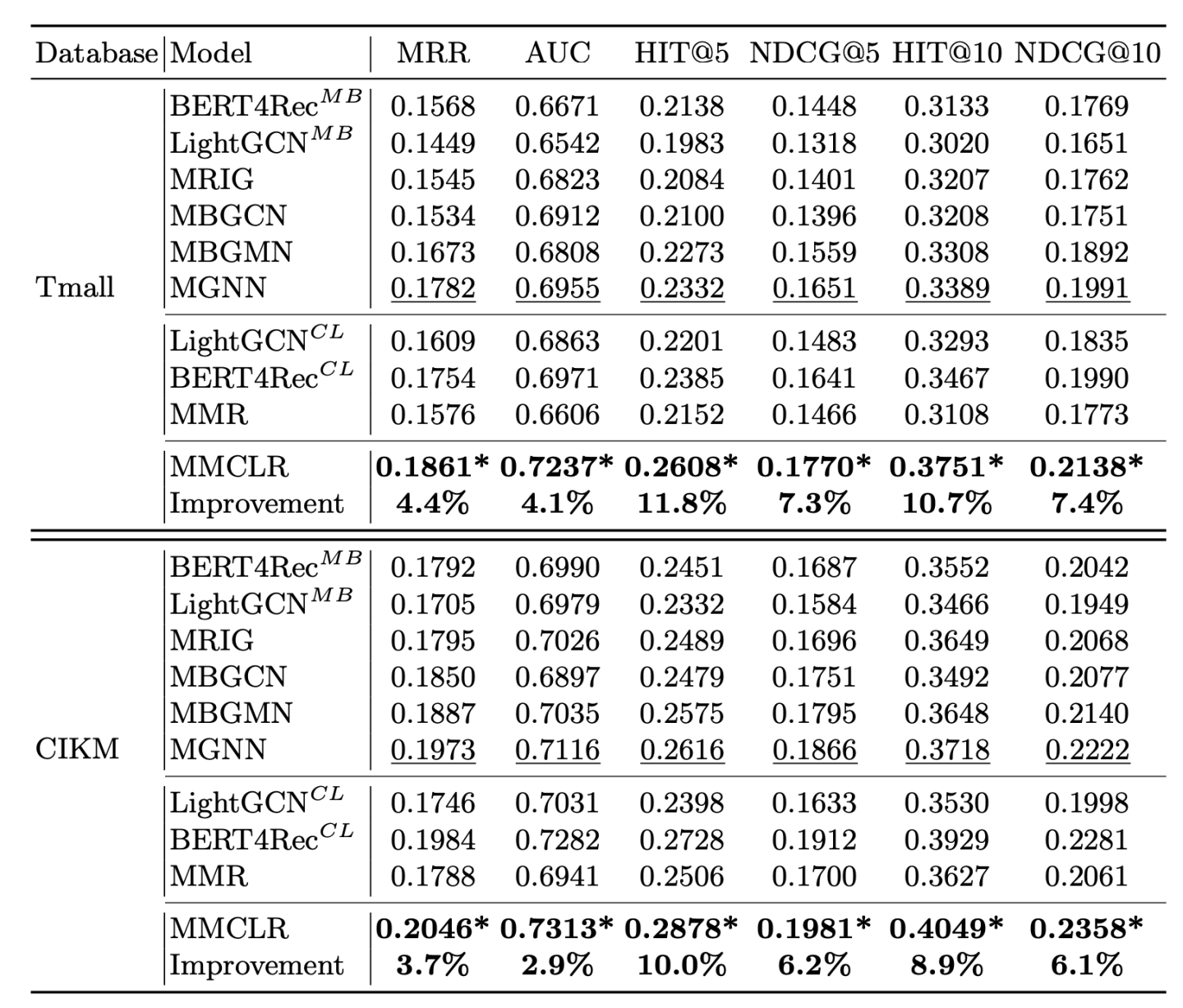
(2)VS baseline
作者这里对比了多个基线模型(MMCLR是本文提出的模型),可以看到具有提高
(3)idea的消融实验
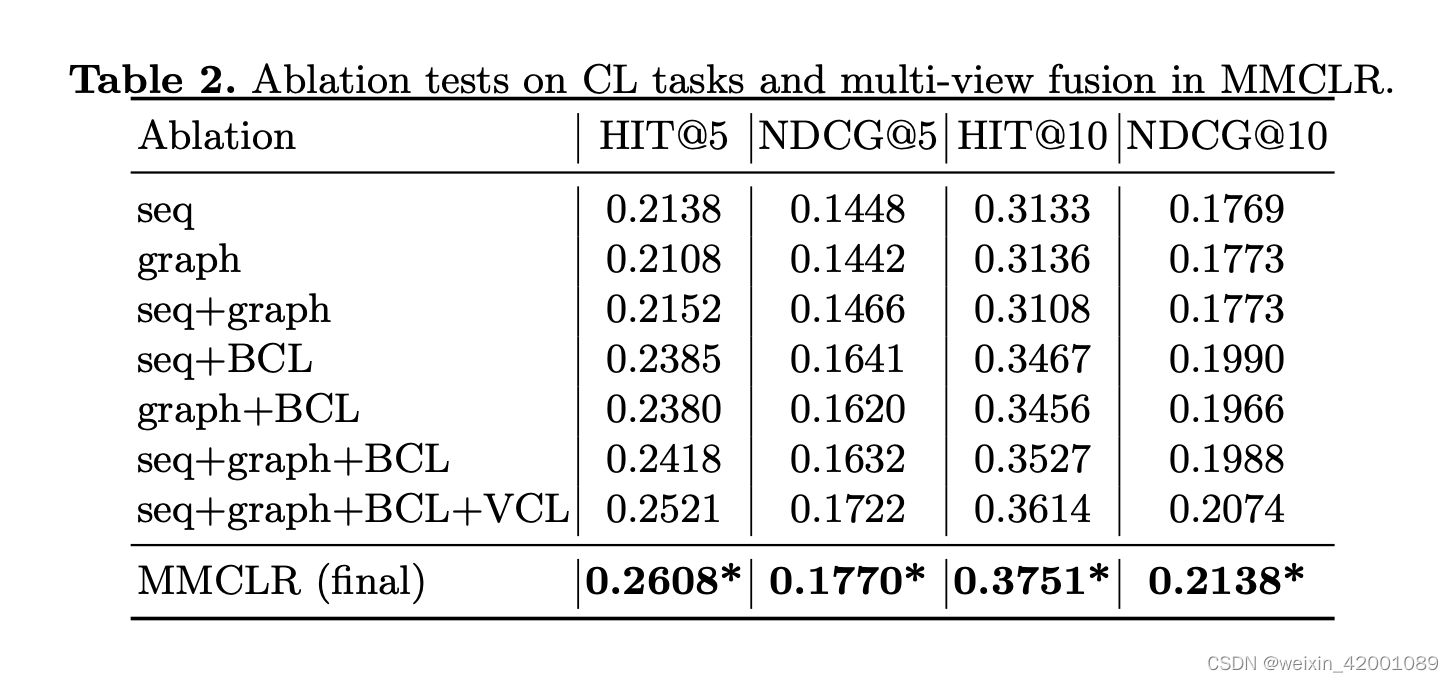
将多行为对比学习、多视角对比学习和多行为细粒度对比学习分别命名为BCL、VCL、DCL
从上面可以看到都有效果,最后的MMCLR就是seq+graph+BCL+VCL+DCL
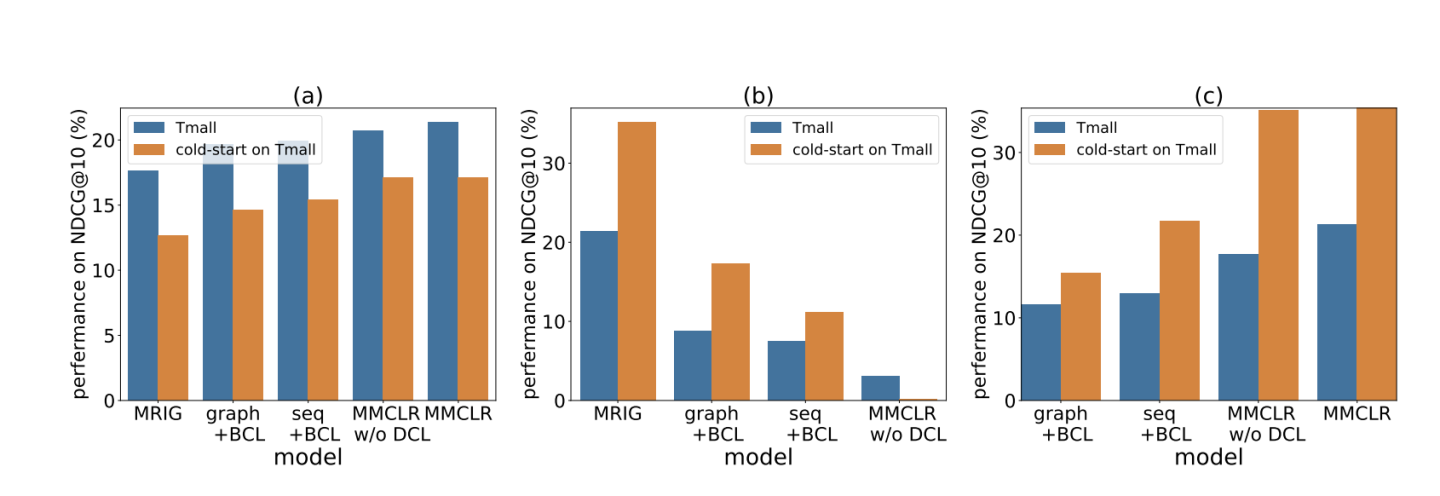
(4) 冷启动
同时作者实验了MMCLR在冷启动用户上的表现,可以看到都是有效果的
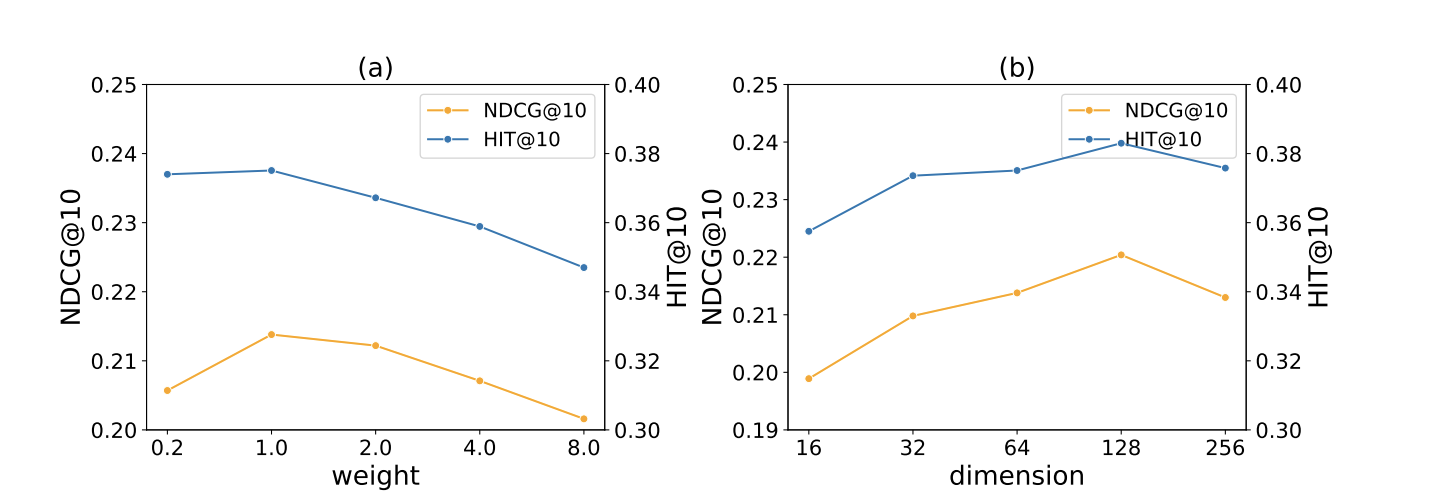
(5)不同的超参
作者这里进一步实验了不同的超参对结果的印象,weight这里是指对那四个不同loss融合的权重,可以看到当(a)loss的权重为1、其他几个对比学习权重分别是0.2, 0.2, 0.2, 0.05时取得最好的结果。
同时作者也对不同维度进行了探究,可以看到越到越好,不过当大到256时,有所下降,可能是过拟合造成的,所以太大的维度也不必要
总结
(1)同端的不同行为甚至是多端行为的利用是有可能带来收益的
(2)不同视角这个想法也不错~
关注
欢迎关注,下期再见啦~
欢迎关注笔者微信公众号:

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
知乎:

















 3048
3048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









