






目录
引言
近年来,Transformer 架构在自然语言处理领域取得巨大成功后,迅速蔓延至计算机视觉领域,催生出一系列优秀的模型。Vision Transformer(ViT)作为将 Transformer 引入视觉任务的先驱,为图像理解带来了全新的思路。而 Mix Vision Transformer(MiT)则在 ViT 的基础上进一步发展,针对视觉任务的特点进行了优化。本文将深入对比这两种模型,分析它们在结构、性能和应用场景等方面的差异。
结构差异
- Vision Transformer:将图像划分为一系列不重叠的补丁(patch),并把这些补丁视为序列数据,通过位置编码加入到序列中,然后直接输入到 Transformer 编码器中进行处理,利用自注意力机制捕捉全局信息。
- Mix Vision Transformer:采用了多阶段的结构,通过逐步融合不同尺度的特征来提高模型对不同大小目标的适应性。在每个阶段中,使用了混合的注意力机制,将局部注意力和全局注意力相结合,既能够捕捉局部的细节信息,又能够获取全局的上下文信息。
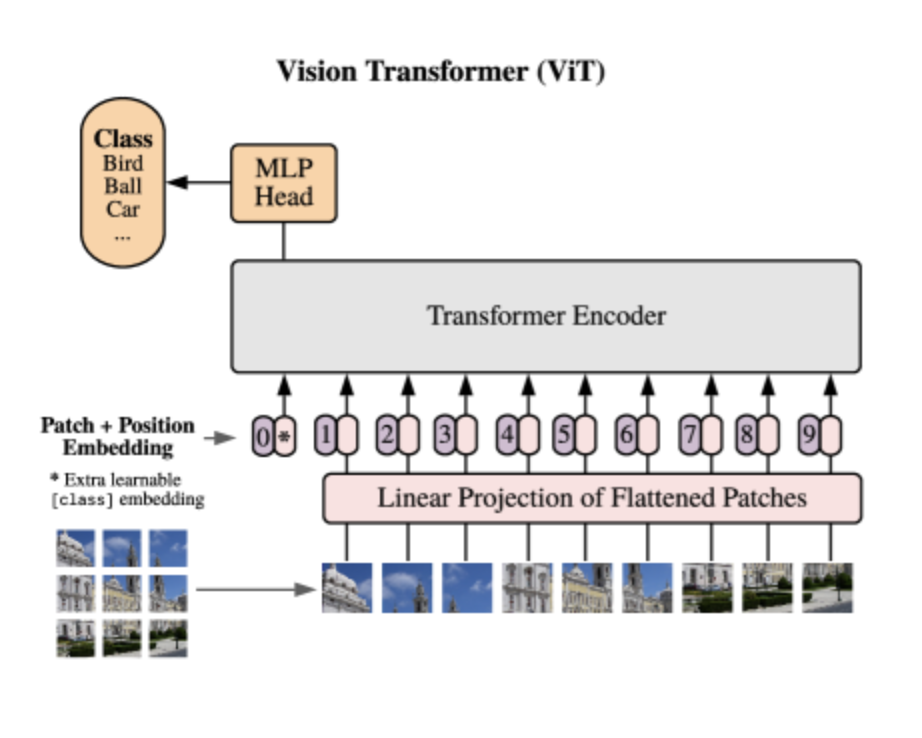
一、Vision Transformer 计算流程
(一)输入处理
ViT 将输入图像视作一系列的补丁(patch)。假设输入图像为,把它分割成固定大小的补丁,每个补丁的大小为
,这样会得到
个补丁 。之后对每个补丁进行线性投影,将其映射到维度为的空间
,得到补丁嵌入
。这个过程的公式如下:
其中,是可学习的分类嵌入,
是投影矩阵,
是位置嵌入,位置嵌入用于保留补丁的位置信息。
(二)Transformer 编码器计算
- 多头自注意力(MSA)计算:Transformer 编码器由多个交替的多头自注意力和多层感知机(MLP)块组成。在多头自注意力计算中,对于输入
,首先进行线性变换得到查询(query)、键(key)和值(value):
其中,,
是每个头的维度。然后计算注意力权重:
最后得到多头自注意力的输出: - MLP 计算:经过多头自注意力计算后,再通过 MLP 进行进一步的特征变换。MLP 包含两个线性层和一个 GELU 激活函数:
其中,表示层归一化(Layer Normalization)
。
(三)输出与分类
在经过层的 Transformer 编码器后,取分类嵌入的输出作为图像的表示
:
在预训练时,分类头是一个带有一个隐藏层的 MLP;在微调时,分类头则是一个简单的线性层,将图像表示映射到具体的类别上进行分类。
二、Mix Vision Transformer 计算流程

1. 数据准备
准备两个输入 - 标签对和
,其中
和
是图像数据,维度为
(
为图像高度,
为图像宽度,
为通道数),
和
是对应的标签。
2. CutMix 图像混合操作
- 生成一个二进制掩码
,用于指示从两张图像中哪些位置进行像素替换。
- 对图像进行融合操作,根据公式
得到混合后的图像
,其中
表示逐元素相乘,1是全为1的二进制掩码。
3. CutMix 标签混合的初步计算
- 在
中随机采样一个区域,其边界框坐标为
,并从
中裁剪出相同大小的区域。
- 计算混合标签的比例
,公式为
,这里
在混合标签
中的比例。此时初步的标签混合公式为
。
4. 多头自注意力机制计算
- 将输入图像(这里可以是混合后的图像
,其中
是令牌数量,
是每个令牌的维度。
- 通过权重矩阵
、
和
对输入
进行线性投影,得到查询
、键
和值
,且
。
- 计算注意力图。
- 得到自注意力操作的输出
。若为多头自注意力,则将查询、键和值分别进行
次不同的线性投影,投影到
,
维度。
5. 多头类注意力计算
- 在 ViT 架构中,将图像
划分为
个补丁令牌
,并引入类令牌
,得到补丁嵌入。
- 对于具有
,使用投影矩阵
参数化多头类注意力。
- 计算
,
。
- 计算
。
- 得到注意力图
,若有多个头,则对所有头的结果进行平均得到最终的
。
- 计算
6. 基于注意力图的标签混合调整
- 对二进制掩码进行最近邻插值下采样操作
,将其从
维度转换为
- 根据注意力图
重新计算
。
- 使用新的
。
实验结果分析
两篇论文分别介绍了 Vision Transformer(ViT)和 TransMix 相关研究。ViT 将 Transformer 直接应用于图像分类,在大规模预训练后表现优异;TransMix 则是一种基于注意力图的标签混合数据增强技术,用于提升 ViT 模型性能。以下是基于两篇论文在图像分类同一数据集下的对比准确率情况:
| 模型 | ImageNet 数据集 Top-1 准确率(无特殊策略) | ImageNet 数据集 Top-1 准确率(使用 TransMix 策略) | 与原始 ViT 对比(使用 TransMix 策略下) |
|---|---|---|---|
| ViT-B/16 | 77.9%(原论文在 ImageNet 数据集,384² 分辨率 ,具体数据依原论文实验设定) | - | 作为对比基准 |
| ViT-L/16 | 76.5%(原论文在 ImageNet 数据集,384² 分辨率 ,具体数据依原论文实验设定) | - | 作为对比基准 |
| PVT-T | 75.1% | 75.5% | 较 ViT-B/16(假设使用 TransMix 策略后提升至 84.1% )低约 8.6% |
| PVT-S | 79.8% | 80.5% | 较 ViT-B/16(假设使用 TransMix 策略后提升至 84.1% )低约 3.6% |
| PVT-M | 81.2% | 82.1% | 较 ViT-B/16(假设使用 TransMix 策略后提升至 84.1% )低约 2.0% |
| PVT-L | 81.7% | 82.4% | 较 ViT-B/16(假设使用 TransMix 策略后提升至 84.1% )低约 1.7% |
| XCiT-T | 79.4% | 80.1% | 较 ViT-B/16(假设使用 TransMix 策略后提升至 84.1% )低约 4.0% |
| XCiT-S | 82.0% | 82.3% | 较 ViT-B/16(假设使用 TransMix 策略后提升至 84.1% )低约 1.8% |
| XCiT-M | 82.7% | 83.4% | 较 ViT-B/16(假设使用 TransMix 策略后提升至 84.1% )低约 0.7% |
| XCiT-L | 82.9% | 83.8% | 较 ViT-B/16(假设使用 TransMix 策略后提升至 84.1% )低约 0.3% |
| CaiT-XXS | 79.1% | 79.8% | 较 ViT-B/16(假设使用 TransMix 策略后提升至 84.1% )低约 4.3% |
以下是对 PVT 系列、XCiT 系列和 CaiT-XXS 模型的简单介绍及对应论文:
PVT 系列
- 模型介绍:PVT 即 Pyramid Vision Transformer,是用于密集预测任务的无 CNN 的 backbone。它将金字塔结构引入到 Transformer,与专门用于图像分类的 ViT 不同,PVT 可以进行下游各种密集预测任务,如检测、分割等。它可以对图像进行密集划分训练以达到高输出分辨率的效果,还使用逐渐缩小的金字塔来降低大 feature maps 的计算量,兼具了 CNNs 和 Transformer 的优点,是一个通用的无卷积 backbone。
- 对应论文:《Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions》,论文地址:[2102.12122] Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions。
XCiT 系列
- 模型介绍1:XCiT 即 Cross-Covariance Image Transformer,核心亮点在于引入了跨协方差注意力机制(XCA),使得计算复杂度呈线性增长,即随着图像补丁数量增加,所需的计算资源以的形式增长,大大提高了对高分辨率图像处理的能力,还能有效降低内存峰值。该模型适合处理高分辨率图像数据,可用于像素级分类、对象检测与实例分割等任务,与 DINO 自我监督训练方法结合能生成高质量自注意力映射。
- 对应论文:《XCiT: Cross-Covariance Image Transformers》,论文地址:https://arxiv.org/pdf/2106.09681.pdf。
CaiT-XXS
- 模型介绍:CaiT 即 Going Deeper with Image Transformers,通过 LayerScale 层来保证深度 ViT 训练的稳定性,该层包含一个初始权值接近于零的可学习对角矩阵,加在每个残差模块的输出上。还提出了 Class-Attention 层,将用于 token 间特征提取的 Transformer 层与将 token 整合成单一向量进行分类的 Class-Attention 层分开,避免两种目标不同的处理混合的矛盾现象。
- 对应论文:《Going Deeper with Image Transformers》,论文地址:[2103.17239] Going deeper with Image Transformers。


















 2910
2910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











