







在机器学习中,损失函数是代价函数的一部分,而代价函数则是目标函数的一种类型。
-
Loss function,即损失函数:用于定义单个训练样本与真实值之间的误差;
-
Cost function,即代价函数:用于定义单个批次/整个训练集样本与真实值之间的误差;
-
Objective function,即目标函数:泛指任意可以被优化的函数。
损失函数是用于衡量模型所作出的预测离真实值(Ground Truth)之间的偏离程度。 通常,我们都会最小化目标函数,最常用的算法便是“梯度下降法”(Gradient Descent)。俗话说,任何事情必然有它的两面性,因此,并没有一种万能的损失函数能够适用于所有的机器学习任务,所以在这里我们需要知道每一种损失函数的优点和局限性,才能更好的利用它们去解决实际的问题。损失函数大致可分为两种:回归损失(针对连续型变量)和分类损失(针对离散型变量)。
一、回归损失
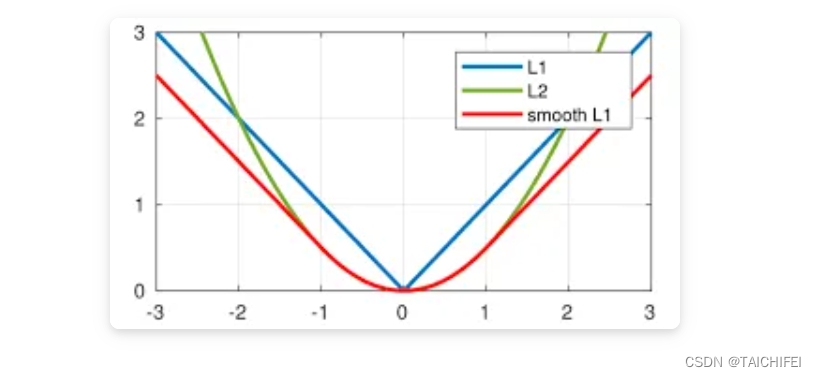
1. L1Loss(MAE)
L1 Loss,又称为绝对损失(Absolute Loss)或曼哈顿损失(Manhattan Loss),在机器学习和深度学习中主要用于回归问题。其数学表达式为:
L
1
=
1
N
∑
N
i
=
1
∣
y
i
−
y
^
i
∣
L_1 = \frac{1}{N}\sum^{i=1}_{N}|y_i-\hat{y}_i|
L1=N1N∑i=1∣yi−y^i∣
其中,
y
i
y_i
yi是真实值,
y
^
i
\hat{y}_i
y^i是模型预测值,
N
N
N是样本数量。
L1 Loss的特点包括:
非连续性与稀疏性:由于L1 Loss使用绝对值函数,其梯度在预测值与真实值相等时为0(不考虑0点的不连续性),在其他情况下为常数(+1或-1),这导致了其梯度的稀疏性。这种特性有时可以帮助模型学习到稀疏的解决方案,即鼓励某些权重变得非常小或为0,有利于特征选择。
对异常值的鲁棒性:相比L2 Loss,L1 Loss对异常值(outliers)更为稳健。在数据集中如果存在极端的错误预测,L1 Loss不会像L2 Loss那样被这些极端值强烈影响,这在处理含有噪声的数据时是一个优势。
优化路径:L1 Loss导致的优化路径不如L2 Loss平滑,特别是在误差接近0时,L1 Loss的梯度恒定,可能导致在寻找最优解时不够精确,尤其是在高维空间中,这可能使得训练过程在局部最优解附近停滞。
计算效率:在某些情况下,特别是对于稀疏数据,L1 Loss的计算和优化可以比L2 Loss更高效,因为其梯度计算简单且在很多点上为0。
- 优点: 对离群点(Outliers)或者异常值更具有鲁棒性。
- 缺点: 由图可知其在0点处的导数不连续,使得求解效率低下,导致收敛速度慢;而对于较小的损失值,其梯度也同其他区间损失值的梯度一样大,所以不利于网络的学习。
L1 Loss的优势主要体现在以下几个方面:
- 鲁棒性:L1 Loss对异常值(outliers)更为鲁棒,这意味着在数据中存在极端错误预测时,它不会像L2 Loss那样受到这些点的强烈影- 响,有助于模型在有噪声或异常值的数据集中稳定学习。
- 稀疏性:在正则化中,L1惩罚可以促使权重稀疏,即促进某些特征的权重变为零,这对于特征选择特别有用。
- 平移不变性:在某些特定任务如目标检测中的边框回归,L1 Loss的特性使得它对框的位置平移不敏感。
2. L2 Loss (MSE)
也称为Mean Squred Error,即均方差(MSE),它衡量的是预测值与真实值之间距离的平方和,作用范围同为0到正无穷。
数学表达式为:
L
2
=
1
2
N
∑
i
=
1
N
(
y
i
−
y
^
i
)
2
L_2=\frac{1}{2N}\sum_{i=1}^{N}(y_i-\hat{y}_i)^2
L2=2N1i=1∑N(yi−y^i)2
其中,
y
i
y_i
yi是真实值,
y
^
i
\hat{y}_i
y^i是模型预测值,
N
N
N是样本数量。
- 优点: 收敛速度快,能够对梯度给予合适的惩罚权重,而不是“一视同仁”,使梯度更新的方向可以更加精确。
- 缺点: 对异常值十分敏感,梯度更新的方向很容易受离群点所主导,不具备鲁棒性。
平滑性:由于误差是以平方的形式计算,L2 Loss对误差的惩罚随着误差的增加而迅速增大,这意味着它对大误差给予了更多的惩罚。这种性质使得L2 Loss在优化过程中对噪声较为敏感,倾向于拟合数据的趋势而非精确匹配每一个点,特别是在数据量较大时。
梯度特性:L2 Loss的梯度为误差的一阶导数,即$$,这使得其在误差较大时梯度也较大,引导学习过程快速下降;而当模型接近最优解,误差减小时,梯度也随之减小,有助于模型在接近最y_i-\hat{y}_i小值时进行更精细的调整,避免过冲(overshooting)。这种特性有助于提高收敛的稳定性,并可能加快早期的学习速度。
凸性质:L2 Loss对应的损失函数是一个凸函数,意味着它只有一个全局最小值,没有局部极小值的困扰,这简化了优化问题,保证了找到的解是全局最优解(在理想无噪声情况下)。
正则化:在权重正则化中,L2正则化(Ridge Regression)通过添加权重向量的平方和到损失函数中,可以防止模型过拟合。它促使权重值趋向于较小的值,但不强制它们为零,从而保持了模型的复杂度并减少了特征之间的依赖性。
对于L1范数和L2范数,如果异常值对于实际业务非常重要,我们可以使用MSE作为我们的损失函数;另一方面,如果异常值仅仅表示损坏的数据,那我们应该选择MAE作为损失函数。此外,考虑到收敛速度,在大多数的卷积神经网络中(CNN)中,我们通常会选择L2损失。但是,还存在这样一种情形,当你的业务数据中,存在95%的数据其真实值为1000,而剩下5%的数据其真实值为10时,如果你使用MAE去训练模型,则训练出来的模型会偏向于将所有输入数据预测成1000,因为MAE对离群点不敏感,趋向于取中值。而采用MSE去训练模型时,训练出来的模型会偏向于将大多数的输入数据预测成10,因为它对离群点异常敏感。因此,大多数情况这两种回归损失函数并不适用,能否有什么办法可以同时利用这两者的优点呢?
3. Smooth L1 Loss
即平滑的L1损失(SLL),出自Fast RCNN。SLL通过综合L1和L2损失的优点,在0点处附近采用了L2损失中的平方函数,解决了L1损失在0点处梯度不可导的问题,使其更加平滑易于收敛。此外,在|x|>1的区间上,它又采用了L1损失中的线性函数,使得梯度能够快速下降。
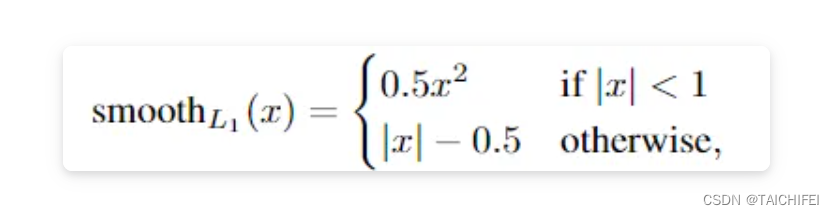
通过对这三个损失函数进行求导可以发现,L1损失的导数为常数,如果不及时调整学习率,那么当值过小时,会导致模型很难收敛到一个较高的精度,而是趋向于一个固定值附近波动。反过来,对于L2损失来说,由于在训练初期值较大时,其导数值也会相应较大,导致训练不稳定。最后,可以发现Smooth L1在训练初期输入数值较大时能够较为稳定在某一个数值,而在后期趋向于收敛时也能够加速梯度的回传,很好的解决了前面两者所存在的问题。
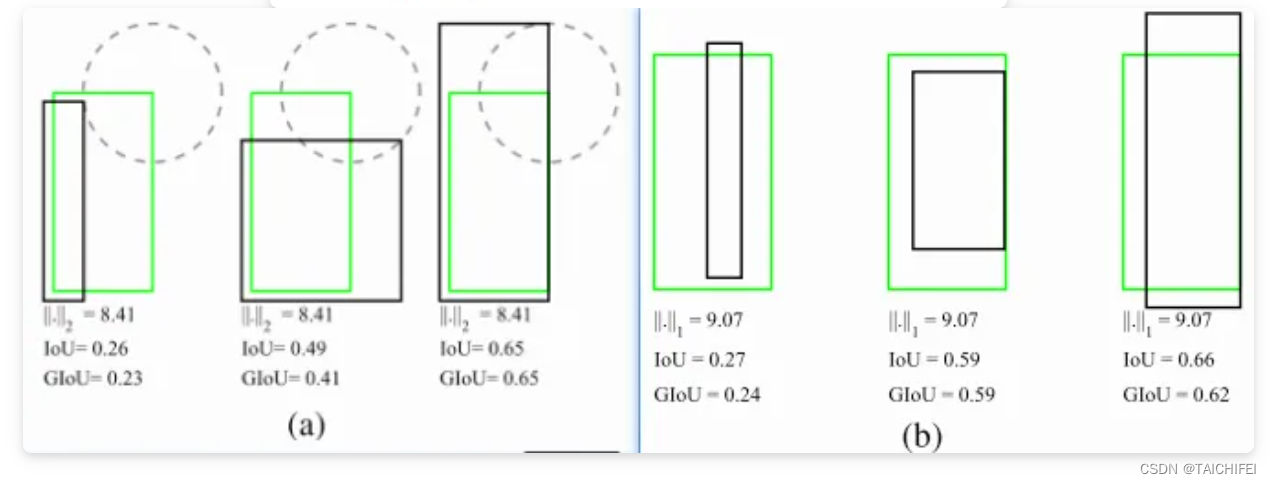
4. IoU Loss
即交并比损失,出自UnitBox,由旷视科技于ACM2016首次提出。常规的Lx损失中,都是基于目标边界中的4个坐标点信息之间分别进行回归损失计算的。因此,这些边框信息之间是相互独立的。然而,直观上来看,这些边框信息之间必然是存在某种相关性的。如下图(a)-(b)分别所示,绿色框代表Ground Truth,黑色框代表Prediction,可以看出,同一个Lx分数,预测框与真实框之间的拟合/重叠程度并不相同,显然重叠度越高的预测框是越合理的。IoU损失将候选框的四个边界信息作为一个整体进行回归,从而实现准确、高效的定位,具有很好的尺度不变性。为了解决IoU度量不可导的现象,引入了负Ln范数来间接计算IoU损失。

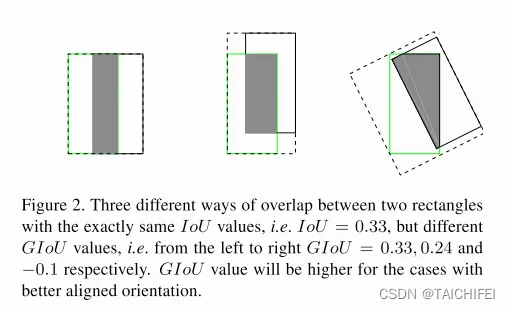
5. GIoU Loss
GIoU(Generalized Intersection over Union)是IoU的一种扩展形式,由Rezatofighi et al.在2019年提出,旨在改进边界框回归的性能,尤其是在边界框不重叠的情况下。GIoU不仅考虑了两个边界框的交集与并集的关系,还引入了最小外包矩形的概念,以此来惩罚不相交的边界框,使得即使在边界框没有交集时,损失函数也能给出有意义的梯度,促进学习过程。
设两个边界框分别为A和B,它们的交集区域为A∩B,并集区域为A∪B,最小外包矩形(最小面积的矩形能够完全包含A和B)为C,则GIoU定义为:
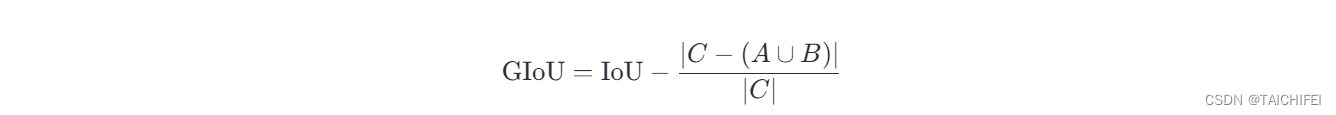
当两个边界框完全重叠时,GIoU = IoU = 1。
当两个边界框不相交时,IoU为0,而GIoU会小于0,并且随着两框距离的增加,GIoU的值会更加负,理论上可以趋近于-1(但实际应用中达到-1的情况只在理论极限下发生)。
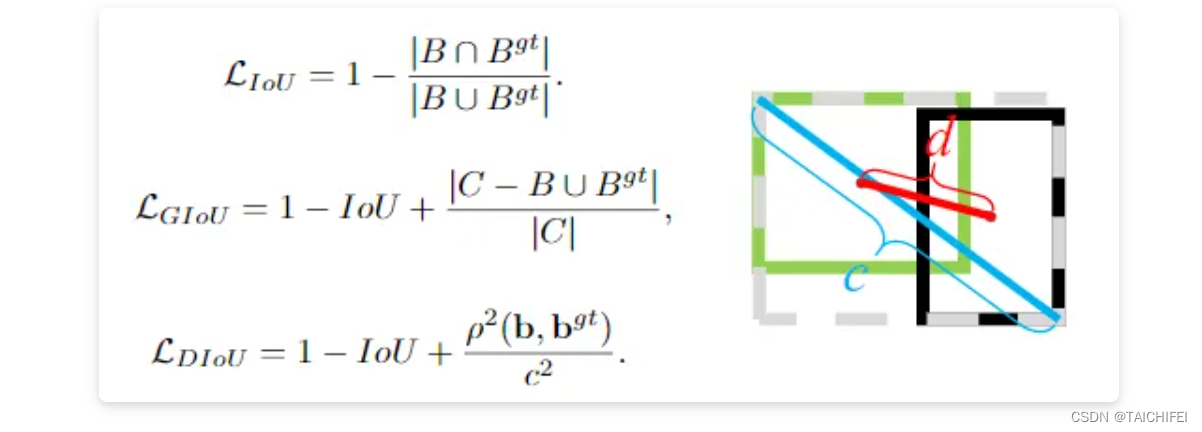
6. DIoU Loss
DIoU(Distance-IoU Loss)是对GIoU(Generalized Intersection over Union)的进一步扩展,由Zhou et al.在2020年提出,用于目标检测中更高效和准确地优化边界框回归。DIoU在GIoU的基础上,进一步考虑了两个边界框中心点之间的欧几里得距离,以减少边界框中心位置的偏差,从而加速收敛并提高定位精度。
DIoU的计算公式如下:
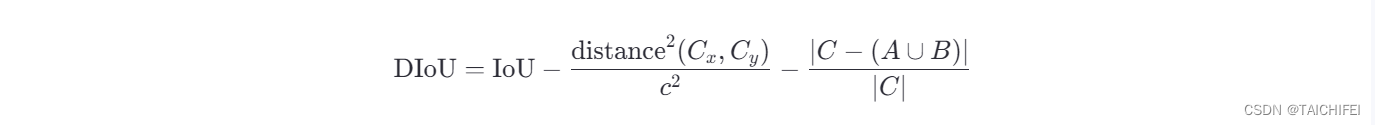
这里,除了GIoU中的项之外,新增了一项关于边界框中心点距离的惩罚:
- C x , C y C_x,C_y Cx,Cy 分别代表两个边界框中心点的坐标。
- c c c 代表最小外包矩形C的对角线长度,用来标准化距离,确保距离项的尺度不变性。
- distance 2 ( C x , C y ) \text{distance}^2(C_x,C_y) distance2(Cx,Cy)表示两个边界框中心点之间的欧氏距离的平方。
特性说明:
中心点距离惩罚:DIoU通过加入中心点距离的惩罚项,直接优化边界框中心位置的准确性,这对于那些尺寸相近但位置偏离的目标尤为重要,有助于模型更快收敛并提升定位质量。
综合优化:DIoU综合考虑了交并比、外包矩形剩余面积以及中心点距离,使得边界框回归的优化更加全面,既关注边界框的大小和形状匹配,也注重位置的精确性。
收敛性和精度:相比IoU和GIoU,DIoU在实践中往往能更快地收敛,并达到更高的定位精度,尤其是在面对密集目标或者小目标检测任务时效果更为显著。
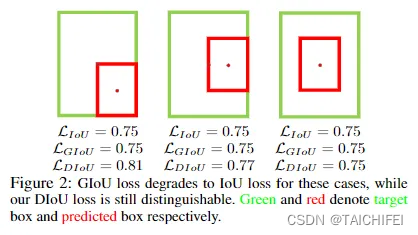
下图表示的是GIoU损失(第一行)和DIoU损失(第二行)的一个训练过程收敛情况。其中绿色框为目标边框,黑色框为锚框,蓝色框和红色框则分别表示使用GIoU损失和DIoU损失所得到的预测框。可以发现,GIoU损失一般会增加预测框的大小使其能和目标框重叠,而DIoU损失则直接使目标框和预测框之间的中心点归一化距离最小,即让预测框的中心快速的向目标中心收敛。
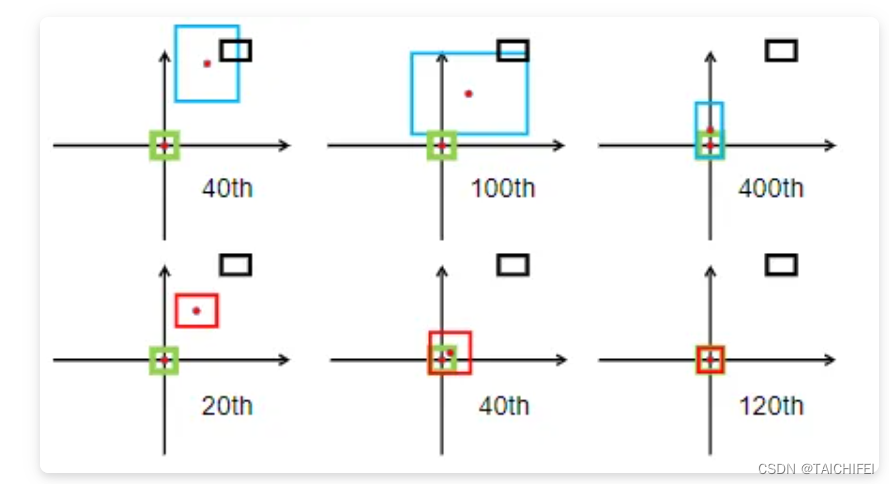
下图给出这三个IoU损失所对应的计算公式。对于DIoU来说,如图所示,其惩罚项由两部分构成:分子为目标框和预测框中心点之间的欧式距离;分母为两个框最小外接矩形框的两个对角线距离。因此, 直接优化两个点之间的距离会使得模型收敛得更快,同时又能够在两个边框不重叠的情况下给出一个优化的方向。
7. CIoU Loss
即完整IoU损失,全称为Complete IoU loss,与DIoU出自同一篇论文。上面我们提到GIoU存在两个缺陷,DIoU的提出解决了其实一个缺陷,即收敛速度的问题。而一个好的边框回归损失应该同时考虑三个重要的几何因素,即重叠面积(Overlap area)、中心点距离(Central point distance)和高宽比(Aspect ratio)。GIoU考虑到了重叠面积的问题,DIoU考虑到了重叠面积和中心点距离的问题,CIoU则在此基础上进一步的考虑到了高宽比的问题。额外引入了一个惩罚项来解决角度差异问题,特别适用于旋转框的检测任务。

CIoU的计算公式如下:
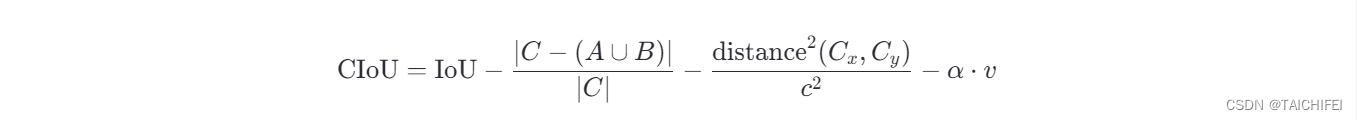
- 前三项与DIoU相同,分别对应IoU的计算、外包矩形剩余面积的惩罚以及中心点距离的惩罚。
- 新增的第四项是角度差异的惩罚项,其中:
– v 表示两个边界框旋转角度的差异(通常通过余弦相似度或直接角度差的某种形式来衡量)。
– α 是一个平衡系数,用于调节角度惩罚项的重要性。

特性说明:
- 角度惩罚:通过加入角度差异的惩罚项,CIoU Loss能够有效处理具有旋转角度变化的边界框回归问题,这对于一些特定应用场景如文本检测、复杂物体检测等非常关键。
- 综合性:CIoU Loss是目前最全面的边界框回归损失函数之一,它同时考虑了面积重叠、中心点距离以及角度偏差,使得边界框的回归更加精确和高效。
- 优化性能:研究表明,CIoU Loss相比IoU、GIoU和DIoU,能够更快地收敛,并且在最终的检测精度上表现更优,尤其是在处理边界框旋转、尺度变化和位置偏移等问题时。
8. EIoU
EIoU(Enhanced Intersection over Union)是目标检测领域中为了进一步提升边界框回归精度而提出的一种损失函数,由Yan et al.在2021年提出。EIoU在原有的IoU基础上,不仅考虑了边界框的交并比,还额外引入了边界框的长宽比(Aspect Ratio)差异和中心点距离的惩罚项,从而在多方面优化边界框的回归效果,特别是在处理具有不同尺度和纵横比变化的对象时更为有效。
EIoU的计算公式如下:
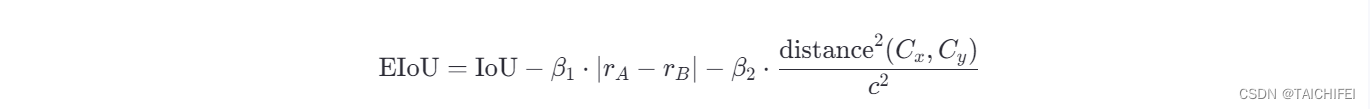
- r A r_A rA和 r B r_B rB分别代表两个边界框的长宽比(Aspect Ratio),即宽除以高。
- ∣ r A − r B ∣ |r_A-r_B| ∣rA−rB∣表示长宽比的差异惩罚项,用于鼓励预测框和真实框在形状上的匹配。
- β 1 \beta_1 β1和 β 2 \beta_2 β2是超参数,用于调整长宽比差异和中心点距离惩罚项的权重。
- 中心店距离的惩罚项与DIoU中的相似,通过 distance 2 ( C x , C y ) c 2 \frac{\text{distance}^2(C_x,C_y)}{c^2} c2distance2(Cx,Cy)计算,其中 C x C_x Cx, C y C_y Cy是边界框中心点的坐标,c是外包矩形的对角线长度,用于归一化距离。
特性说明:
- 长宽比惩罚:通过加入长宽比差异的惩罚项,EIoU能够更好地处理不同纵横比对象的检测,特别是在目标尺度变化大或形状多样的场景下。
- 中心点距离考虑:结合了中心点距离的惩罚,进一步优化边界框的位置预测。
- 综合优化:EIoU在IoU的基础上,通过额外的惩罚项实现了对边界框大小、形状和位置的综合优化,提升了边界框回归的准确性。
9. F-EIoU Loss
Focal EIoU Loss(Focal Enhanced Intersection over Union Loss)是在目标检测领域中提出的一种更进一步的边界框回归损失函数,它是对EIoU(Enhanced Intersection over Union)的扩展,并融入了Focal Loss的思想。Focal Loss最初被设计用于解决类别不平衡问题,通过降低易分类样本的权重,使得模型更多关注难分类的样本。F-EIoU Loss则是将这一思路应用于边界框回归,以进一步提升模型在处理困难边界框情况下的性能。
F-EIoU Loss的动机:
- EIoU(Enhanced IoU) 已经通过考虑边界框的长宽比和中心点距离等因素,提高了边界框回归的准确性。
- Focal机制 引入是为了缓解简单样本带来的过拟合问题,让损失函数更专注于那些难以回归正确的边界框,加速训练并提高模型的泛化能力。
F-EIoU Loss的基本思想:
F-EIou loss首先提出了一种有效的交并集(IOU)损失,它可以准确地测量边界框回归中的重叠面积、中心点和边长三个几何因素的差异:
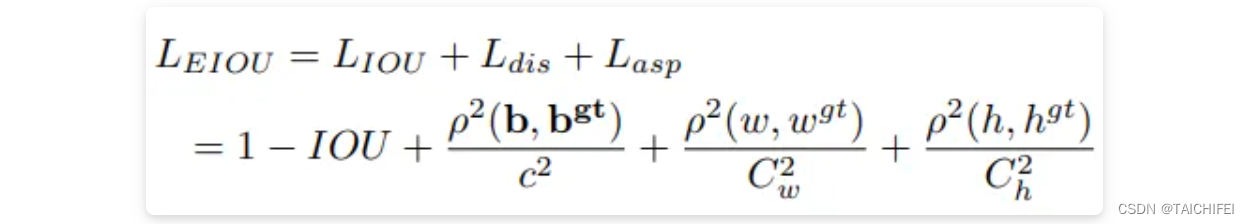
其次,基于对有效样本挖掘问题(EEM)的探讨,提出了Focal loss的回归版本,以使回归过程中专注于高质量的锚框: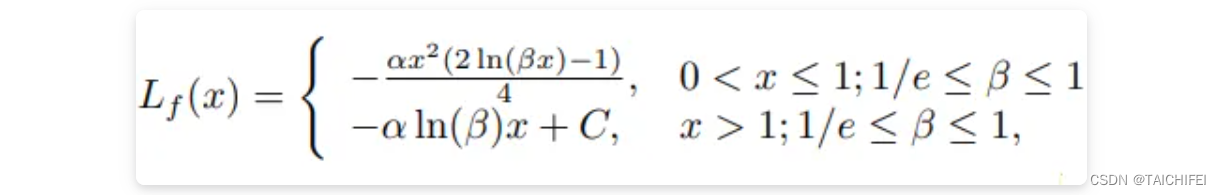
最后,将以上两个部分结合起来得到Focal-EIou Loss:
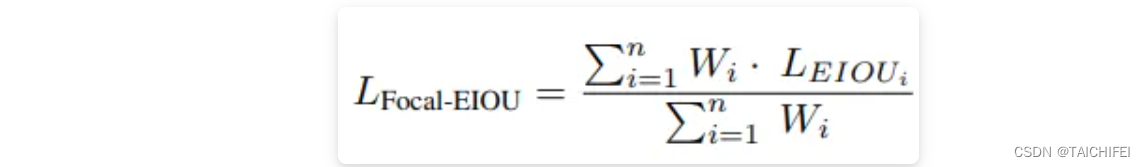
其中,通过加入每个batch的权重和来避免网络在早期训练阶段收敛慢的问题。
特性说明:
重点优化:通过Focal机制,F-EIoU Loss能够更高效地利用训练数据,集中精力优化那些对模型性能提升最有价值的边界框案例。
综合性能提升:结合了多种回归质量指标的考量,F-EIoU Loss在提高检测精度的同时,也致力于减少过拟合风险,增强模型的泛化能力。
适应性广:适合于不同类型的检测任务,无论是标准的矩形框检测还是涉及旋转框的复杂场景。
10. CDIoU Loss
《Control Distance IoU Loss》[7]是由同济大学学者提出的,文章的主要贡献是在几乎不增强计算量的前提下有效提升了边界框回归的精准度。目前检测领域主要两大问题:(1)SOTA算法虽然有效但计算成本高(2)边界框回归损失函数设计不够合理。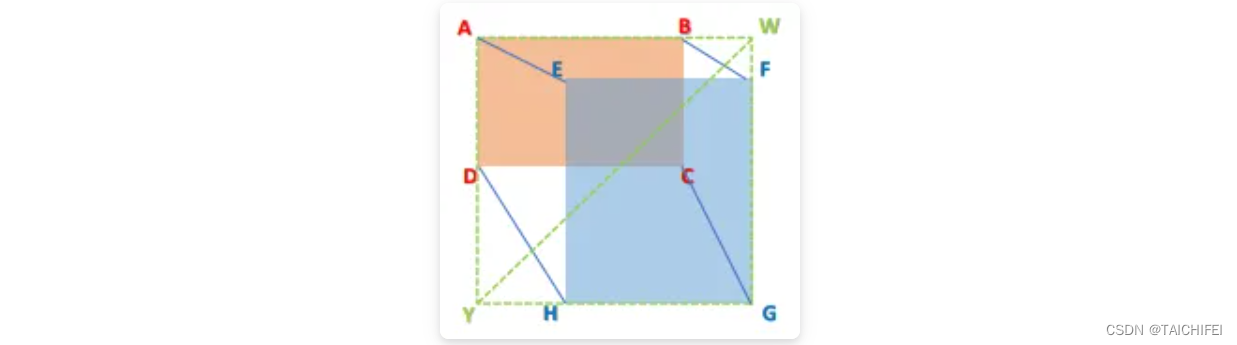
文章首先提出了一种对于Region Propals(RP)和Ground Truth(GT)之间的新评估方式,即CDIoU。可以发现,它虽然没有直接中心点距离和长宽比,但最终的计算结果是有反应出RP和GT的差异。计算公式如下:
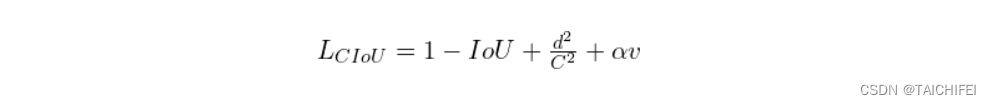
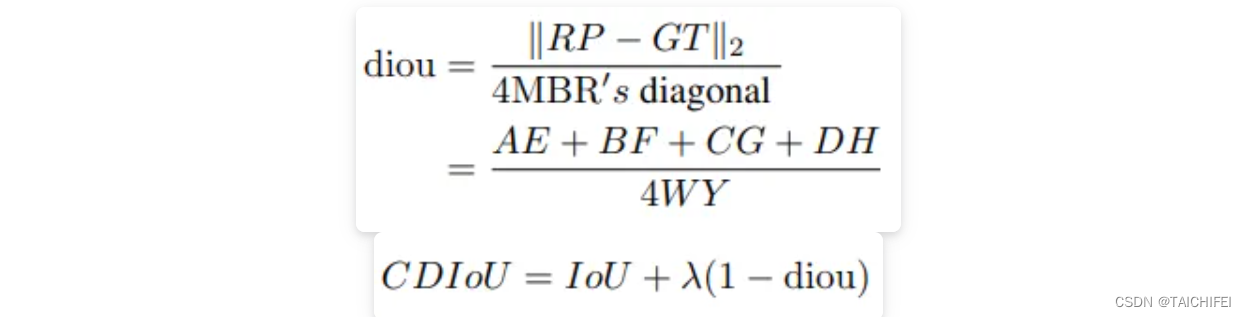
对比以往直接计算中心点距离或是形状相似性的损失函数,CDIoU能更合理地评估RP和GT的差异并且有效地降低计算成本。然后,根据上述的公式,CDIoU Loss可以定义为: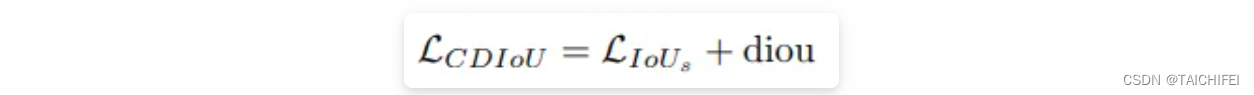 通过观察这个公式,可以直观地感受到,在权重迭代过程中,模型不断地将RP的四个顶点拉向GT的四个顶点,直到它们重叠为止,如下图所示。
通过观察这个公式,可以直观地感受到,在权重迭代过程中,模型不断地将RP的四个顶点拉向GT的四个顶点,直到它们重叠为止,如下图所示。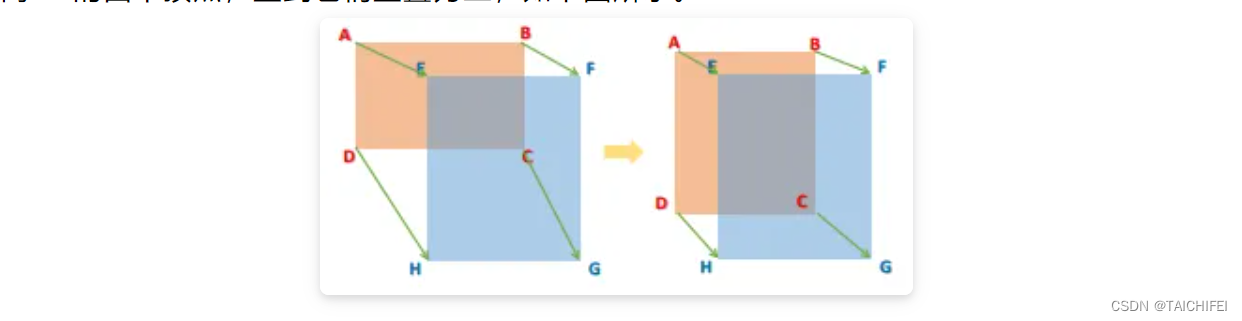
二、分类损失
1. CrossEntropy Loss (交叉损失函数)
交叉熵损失用于衡量两个概率分布之间的差异,特别是模型预测的概率分布与实际数据的标签(即真实概率分布)之间的差异。
Softmax与CrossEntropy Loss结合:模型的输出层通过Softmax函数转换为概率分布(每个类别的概率值,且所有类别概率之和为1),然后与真实标签(通常是one-hot编码)计算交叉熵损失。

特性与优势:
- 优化方向明确:交叉熵损失函数的梯度直接指向了使预测概率向真实概率靠近的方向,有助于模型学习。
- 数值稳定性好:尤其在使用softmax函数时,可以避免概率过小导致的下溢出问题。
- 直观反映模型性能:损失值越低,说明模型的预测概率分布与真实分布越接近,分类性能越好。
在PyTorch中,可以使用nn.CrossEntropyLoss直接计算多分类的交叉熵损失,它内部隐含了Softmax转换,因此模型直接输出未归一化的logit值即可:
import torch
import torch.nn as nn
# 假设模型输出(未经Softmax处理)
outputs = torch.randn(3, 5) # 3个样本,5分类
# 实际标签(假设为类别索引,而非one-hot)
targets = torch.tensor([1, 0, 4])
# 初始化交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 计算损失
loss = criterion(outputs, targets)
print(loss)
2. Binary Cross Entropy Loss(二元交叉损失函数)
二元交叉熵损失函数是衡量两个概率分布差异的一种方法,特别适用于有两个可能结果的分类任务,如真(1)或假(0)。在神经网络中,它用于优化模型预测的概率分布与实际标签之间的差距。

PyTorch这样的深度学习框架中,你通常会这样使用二元交叉熵损失函数:
import torch
import torch.nn as nn
# 假设 outputs 是模型的预测概率(未经过sigmoid或softmax,因为 BCELoss 内部会处理)
outputs = torch.tensor([[0.6], [0.3], [0.8]], requires_grad=True) # 预测概率
labels = torch.tensor([[1], [0], [1]]) # 实际标签
# 初始化二元交叉熵损失函数
criterion = nn.BCEWithLogitsLoss() # 这个包含了logits的版本直接接受未经过sigmoid的输出
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化步骤略
3. BCEWithLogitsLoss
BCEWithLogitsLoss是PyTorch中提供的一个损失函数,全称为二进制交叉熵带Logits损失(Binary Cross-Entropy Loss with Logits)。它主要用在二分类问题中,特别是神经网络的输出层直接预测的是未经过Sigmoid函数的logits值(即模型的原始输出,可以视为预测为正类的概率的对数几率),而不仅仅是概率值。
工作原理:
在传统的二元交叉熵损失函数中,通常要求模型的输出经过Sigmoid函数转换为概率(值域在0到1之间),然后再计算与实际标签之间的交叉熵。但是,BCEWithLogitsLoss将Sigmoid函数的运算合并进了损失函数内部,直接作用于未经过激活函数的网络输出(logits)。这样做有几个好处:
- 数值稳定性:直接在logits上操作可以减少梯度消失或爆炸的风险,因为Sigmoid函数在输入值较大或较小时会导致梯度接近于0。
- 计算效率:合并了操作减少了正向和反向传播中的步骤,提高了计算效率。
- 简化模型定义:用户无需显式地在模型中加入Sigmoid层,简化了模型结构。

在PyTorch中,使用BCEWithLogitsLoss非常直接:
import torch
import torch.nn as nn
# 假设我们的模型直接输出logits
outputs = torch.randn(3, requires_grad=True) # 3个样本的logits输出
labels = torch.tensor([1, 0, 1], dtype=torch.float32) # 实际标签
# 初始化损失函数
criterion = nn.BCEWithLogitsLoss()
# 计算损失
loss = criterion(outputs, labels)
# 然后进行反向传播和优化等操作
loss.backward()
4. Focal Loss
Focal Loss 是一种用于解决类别不平衡问题的损失函数,首次被提出并应用于目标检测任务中,尤其是在One-Stage检测器(如RetinaNet)中表现显著。它通过调整每个样本的损失权重来增强模型对难分类样本的关注,同时减少对易分类样本的重视,从而改善了模型的鲁棒性和精确度。
出自何凯明的《Focal Loss for Dense Object Detection》[9],出发点是解决目标检测领域中one-stage算法如YOLO系列算法准确率不高的问题。
作者认为样本的类别不均衡(比如前景和背景)是导致这个问题的主要原因。比如在很多输入图片中,我们利用网格去划分小窗口,大多数的窗口是不包含目标的。如此一来,如果我们直接运用原始的交叉熵损失,那么负样本所占比例会非常大,主导梯度的优化方向,即网络会偏向于将前景预测为背景。
即使我们可以使用OHEM(在线困难样本挖掘)算法来处理不均衡的问题,虽然其增加了误分类样本的权重,但也容易忽略掉易分类样本。而Focal loss则是聚焦于训练一个困难样本的稀疏集,通过直接在标准的交叉熵损失基础上做改进,引进了两个惩罚因子,来减少易分类样本的权重,使得模型在训练过程中更专注于困难样本。


应用
Focal Loss不仅限于目标检测,也被扩展到了图像分类、语义分割、实例分割等多种计算机视觉任务以及自然语言处理领域中,尤其适用于处理类别不平衡数据集时。
import torch
import torch.nn as nn
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = nn.functional.binary_cross_entropy_with_logits(inputs, targets, reduce=False)
else:
BCE_loss = nn.functional.binary_cross_entropy(inputs, targets, reduce=False)
pt = torch.exp(-BCE_loss) # prevents nans when probability 0
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
# 使用示例
focal_loss = FocalLoss(alpha=0.25, gamma=2)
outputs = torch.tensor([0.9, 0.1, 0.8, 0.7], requires_grad=True) # 假设模型输出
targets = torch.tensor([1, 0, 1, 1], dtype=torch.float32) # 假设真实标签
loss = focal_loss(outputs, targets.unsqueeze(1)) # unsqueeze是为了形状匹配
loss.backward()
5. KL Loss
KL散度(Kullback-Leibler Divergence),也称为相对熵,是一种衡量两个概率分布之间差异的方法。在机器学习和信息论中,KL散度被用作损失函数来衡量模型预测的分布与实际数据分布之间的不一致程度,特别是在生成模型(如VAE、GANs)和强化学习等领域中应用广泛。

应用:
- 信息理论:用于量化两个概率分布的信息差异。
- 机器学习:
- 变分自编码器(VAE):在重构损失中使用KL散度来约束编码器产生的先验分布和后验分布的差异。
- 生成对抗网络(GANs):虽然直接使用Wasserstein距离或JS散度更常见,但KL散度的概念在理论探讨和某些变体中有所体现。
- 强化学习:在策略迭代中,KL散度可以用来限制新旧策略之间的差异,促进探索的同时保持策略的稳定性。
- 主题模型:如LDA(Latent Dirichlet Allocation)中,用于测量文档主题分布和模型先验的差异。
在PyTorch中,可以直接使用torch.nn.functional.kl_div或torch.distributions.kl_divergence来计算两个分布的KL散度。
import torch
import torch.nn.functional as F
# 假设P和Q是两个概率分布的张量
P = torch.tensor([0.4, 0.3, 0.3])
Q = torch.tensor([0.3, 0.4, 0.3])
# 计算KL散度,reduce='batchmean'表示求平均值,log_target=True表示在Q上取log
kl_div = F.kl_div(P.log(), Q, reduction='batchmean', log_target=True)
print("KL散度:", kl_div.item())
补充
对于交叉熵损失,除了我们在这里使用预测概率的对数(log(q(i)))外,它看起来与上面熵的方程非常相似。如果我们的预测是完美的,那就是预测分布等于真实分布,此时交叉熵就等于熵。但是,如果分布不同,则交叉熵将比熵大一些位数。交叉熵超过熵的量称为相对熵,或更普遍地称为库尔贝克-莱布里埃发散度(KL Divergence)。总结如下:

通常来说,一般分类损失最常用的损失函数之一便是交叉熵损失。假设我们当前做一个3个类别的图像分类任务,如猫、狗、猪。给定一张输入图片其真实类别是猫,模型通过训练用Softmax分类后的输出结果为:{“cat”: 0.3, “dog”: 0.45, “pig”: 0.25},那么此时交叉熵为:-1 * log(0.3) = 1.203。当输出结果为:{“cat”: 0.5, “dog”: 0.3, “pig”: 0.2}时,交叉熵为:-1 * log(0.5) = 0.301。可以发现,当真实类别的预测概率接近于0时,损失会变得非常大。但是当预测值接近真实值时,损失将接近0。
6. Dice Loss
Dice Loss 是一种在医学影像分割和其他计算机视觉任务中常用的损失函数,尤其是处理类别不平衡问题时(如背景像素远多于前景像素的情况)。它源于Sørensen-Dice系数,也称为Dice相似系数(Dice Similarity Coefficient, DSC),用于衡量两个样本集之间的相似度。在深度学习中,Dice Loss 被用作训练模型以优化分割预测和真实分割标签之间的重叠度。出自V-Net。

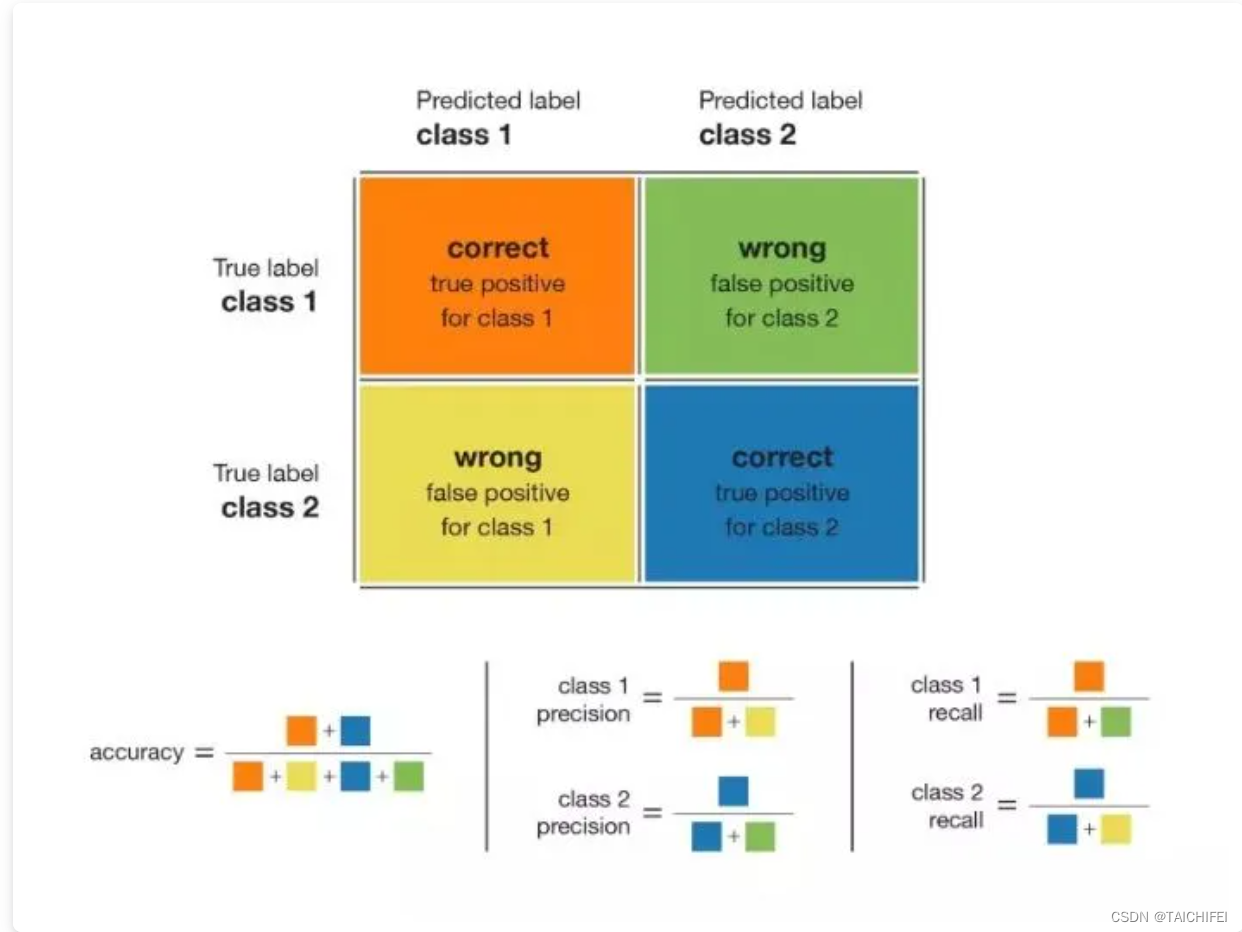
从公式右边也可以看出,其实Dice系数是等价于F1分数的,优化Dice等价于优化F1值。此外,为了防止分母项为0,一般我们会在分子和分母处同时加入一个很小的数作为平滑系数,也称为拉普拉斯平滑项。Dice损失有以下主要特性:
- 有益于正负样本不均衡的情况,侧重于对前景的挖掘;
- 训练过程中,在有较多小目标的情况下容易出现振荡;
- 极端情况下会出现梯度饱和的情况。
所以一般来说,我们都会结合交叉熵损失或者其他分类损失一同进行优化。
import torch
import torch.nn.functional as F
def dice_loss(preds, targets, eps=1e-6):
preds = preds.sigmoid() # 如果你的模型输出没有经过sigmoid激活,需要加上这一行
intersection = (preds * targets).sum(dim=(2, 3))
union = preds.sum(dim=(2, 3)) + targets.sum(dim=(2, 3))
dice_score = (2. * intersection + eps) / (union + eps)
return 1 - dice_score.mean()
# 假设preds和targets是形状为(N, C, H, W)的张量
preds = torch.rand(4, 1, 128, 128) # 预测概率
targets = torch.rand(4, 1, 128, 128).round() # 真实标签,通常是0或1
loss = dice_loss(preds, targets)
print("Dice Loss:", loss.item())
7. Tversky loss
Tversky Loss 是一种用于图像分割和目标检测任务的损失函数,特别是在处理高度不平衡数据集时。它基于经典的Sørensen-Dice系数(Dice Loss)进行了扩展,通过引入两个额外的参数来赋予错分类(False Positives和False Negatives)不同的惩罚权重,从而提供更大的灵活性以适应不同的应用场景。Tversky Loss最初由 Salehi等人在2017年提出,用于医学图像分割任务。

Tversky loss,发表于CVPR 2018上的一篇《Tversky loss function for image segmentation using 3D fully convolutional deep networks》文章,是根据Tversky 等人于1997年发表的《Features of Similarity》文章[11] 所提出的Tversky指数所改造的。
Tversky系数主要用于描述两个特征(集合)之间的相似度,其定义如下: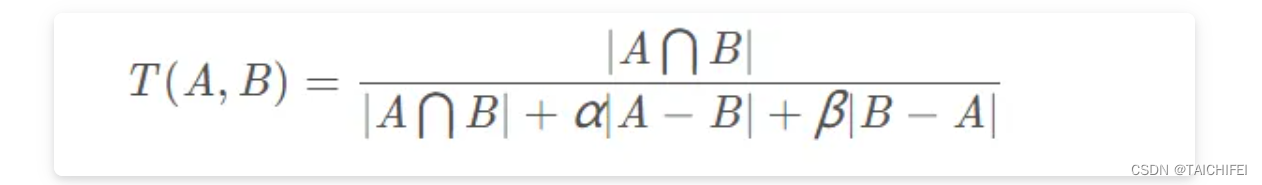
由上可知,它是结合了Dice系数(F1-score)以及Jaccard系数(IoU)的一种广义形式,如:
- 当 α = β = 0.5时,此时Tversky loss便退化为Dice系数(分子分母同乘于2)
- 当 α = β = 1时,此时Tversky loss便退化为Jaccard系数(交并比)
因此,我们只需控制 α 和 β 便可以控制假阴性和假阳性之间的平衡。比如在医学领域我们要检测肿瘤时,更多时候我们是希望Recall值(查全率,也称为灵敏度或召回率)更高,因为我们不希望说将肿瘤检测为非肿瘤,即假阴性。因此,我们可以通过增大 β 的取值,来提高网络对肿瘤检测的灵敏度。其中,α + β 的取值我们一般会令其1。
import torch
import torch.nn.functional as F
def tversky_loss(preds, targets, alpha=0.3, beta=0.7, eps=1e-6):
"""
preds: 预测概率,形状为(N, C, H, W)或(N, C, H, W, D)
targets: 真实标签,形状为(N, H, W)或(N, H, W, D),值为0或1
alpha, beta: 控制FP和FN的权重,默认值为0.3和0.7
eps: 防止除以零的小常数
"""
preds = preds.sigmoid() # 如果模型输出没有经过sigmoid激活,需要这一步
num_classes = preds.shape[1]
# 确保targets的通道维度与preds匹配
targets = targets.unsqueeze(1).expand(-1, num_classes, -1, -1, -1)
TP = (preds * targets).sum(dim=(2, 3)) # 计算每类的真正例
FP = (preds * (1-targets)).sum(dim=(2, 3)) # 假正例
FN = ((1-preds) * targets).sum(dim=(2, 3)) # 假负例
tversky = (TP + eps) / (TP + alpha*FP + beta*FN + eps)
return 1 - tversky.mean()
# 示例使用
preds = torch.rand(4, 1, 128, 128) # 预测概率
targets = torch.rand(4, 128, 128).round() # 真实标签
loss = tversky_loss(preds, targets)
print("Tversky Loss:", loss.item())
8. Contrastive Loss
Contrastive Loss(对比损失)是一种在机器学习和深度学习领域中广泛使用的损失函数,尤其在无监督学习和半监督学习场景下,以及自监督学习中的对比学习方法里尤为重要。它的主要目的是通过最大化相似样本对之间的相似度(正样本对)和减少非相似样本对之间的相似度(负样本对),从而使得模型学习到数据的有效表示。
基本概念:
在对比学习的框架下,通常涉及到成对的数据样本,分为正样本对和负样本对:
- 正样本对:通常指的是来自同一对象或语义相似的两个不同表示(例如,一张图片的不同视角或同一语句的不同变形)。
- 负样本对:指来自不同对象或语义不同的表示,理论上不应该相似。
对比损失函数通过比较正负样本对之间的相似度来优化模型,鼓励学习到的特征空间中相似样本尽可能接近,而不同样本尽可能远离。

简化的对比损失在PyTorch中的实现示例:
import torch
import torch.nn.functional as F
def contrastive_loss(embeddings_a, embeddings_b, labels, margin=1.0, scale=10):
# 计算嵌入间的相似度,这里使用点积
similarities = torch.matmul(embeddings_a, embeddings_b.t())
# 获取正样本对的相似度,即同一标签下的样本
mask_pos = torch.eq(labels.expand(embeddings_a.size(0), labels.expand(embeddings_b.size(0)).t()).unsqueeze(1))
similarities_masked = similarities.masked_select(mask_pos).view(-1)
# 对正样本对计算损失,这里使用margin-based的损失简化版,实际中可能更复杂
loss_contrastive = F.relu(margin - similarities_masked).pow(2).mean()
return scale * loss_contrastive
# 示例用法
embeddings = torch.randn(4, 128) # 假设有4个样本的128维嵌入表示
labels = torch.tensor([0, 0, 1, 1, 1]) # 假定的标签
loss = contrastive_loss(embeddings, embeddings, labels)
print("Contrastive Loss:", loss.item())
三、不同深度学习框架下的损失函数自定义方式
1. Pytorch
import torch
import torch.nn as nn
import torch.nn.functional as F
class Loss(nn.Module):
def __init__(self):
super(Loss, self).__init__()
# 添加需要初始化的参数
def forward(self, inputs, targets):
# 添加相关的计算逻辑
loss_output = ...
return loss_output
2. Tensorflow
class CustomMSE(keras.losses.Loss):
def __init__(self):
super(CustomMSE, self).__init__()
# 添加需要初始化的参数
def __call__(self, y_true, y_pred):
# 添加相关d的计算逻辑
loss_output = ...
return loss_output
参考:















 8782
8782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









