







论文标题:Learning Explicit User Interest Boundary for Recommendation
作者:Jianhuan Zhuo, Qiannan Zhu, Yinliang Yue, Yuhong Zhao
单位:信工所&人大
论文链接:http://arxiv.org/pdf/2111.11026
今天给朋友们分享一篇今年 11 月底公开在 Arxiv 上的论文:Learning Explicit User Interest Boundary for Recommendation。这篇论文结合了 Point-wise 和 Pair-Wise 两种推荐系统 Loss,提出了一种可以显式学习用户兴趣边界的损失函数。
Abstract
隐反馈推荐系统模型的核心目标是使正样本得分 s p s_p sp最大化,负样本得分 s p s_p sp最小化。
这通常可以归纳为两种范式:Point-Wise 和 Pair-Wise。
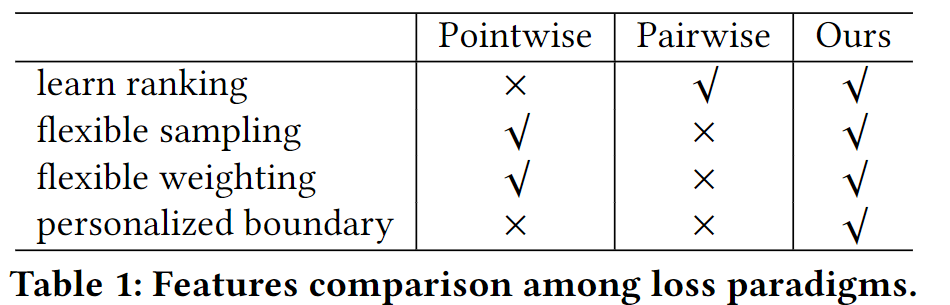
Point-Wise:将每个样本与它的标签单独拟合,这在正负样本的加权和采样方面很灵活,但忽略了推荐中的排名因素。
Pair-Wise:最小化相对分数 s n − s p s_n-s_p sn−sp,捕捉样本的排名,但在训练效率上受到影响。
此外,这两种方法都很难明确地提供一个个性化的决策边界来确定用户是否对未见过的项目感兴趣。
为了解决这些问题,本文创新性的为每个用户引入了一个辅助分数 b u b_u bu 来代表用户兴趣边界(User Interest Boundary),并通过Pair-Wise对跨越边界的样本进行惩罚,即分数低于 b u b_u bu 的正样本和分数高于 b u b_u bu 的负样本。
通过这种方式,本文成功地实现了 Point-Wise 和 Pair-Wise 的混合损失,结合了两者的优点。通过分析,本文方法可以提供一个个性化的决策边界,并且在没有任何特殊采样策略的情况下显著提高训练效率。广泛的结果表明,本文的方法不仅对经典的点式或对式模型,而且对具有复杂损失函数和复杂特征编码的最先进的模型都取得了明显的改进。
Introduction
在信息过载的情况下,推荐系统在有效地为用户提供有用信息方面发挥着重要作用。协同过滤是一种广泛应用的推荐系统技术,用来从用户-商品的历史交互数据中学习潜在偏好,并利用学习到的偏好向用户推荐商品。
通常情况下,协同过滤方法包含两个步骤:
- 定义一个打分函数,来构建用户和商品之间的偏好得分。
- 定义一个损失函数,优化用户和商品之间的打分。
损失函数通常希望正样本有较高的分数,而未观测值和负样本有较低的分数。
之前的损失函数通常可以分为两类,Pointwise 和 Pairwise 。
Pointwise 通常使用 0.5 来作为正负预测的阈值,但这个阈值不够个性化,不能建模排序信息。
目前广泛使用的Pairwise最小化 s n − s p s_n-s_p sn−sp 虽然可以建模排序信息,但不能够提供一个明确的边界来区分正负样本。
此外Pairwise还存在训练效率低的问题。随着训练后期模型的收敛,大部分的负样本都被正确分类了,但由于参与训练的数据中0的个数太多了,模型可以很容易的把这些0分类正确,从而导致了梯度消失的问题。
之前也有一些工作利用困难采样的方法再次训练来缓解这种梯度消失的问题,但这治标不治本。困难分类的样本通常是靠近用户兴趣边界的样本,模型很难区分这些样本。与其改进采样策略,本文认为直接用明确的边界来界定困难样本的分类更合适。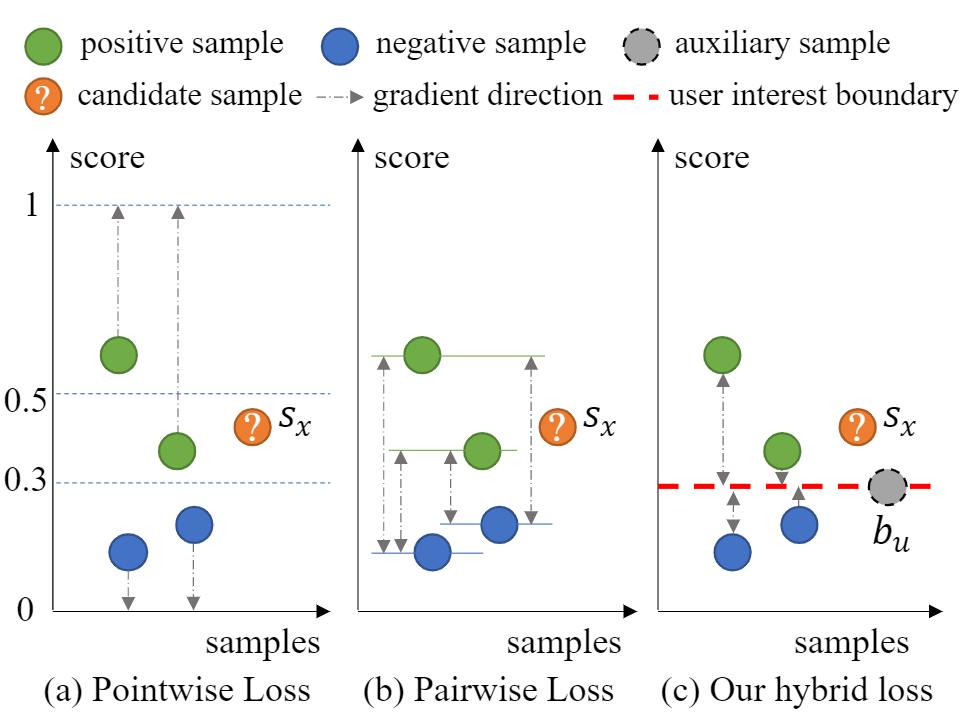
由此,本文提出了一种显式建模用户兴趣边界的损失,该损失为每个用户引入了一个辅助分数,并使用Pairwise的模式惩罚错误越过边界的样本。如上图c所示,用户的兴趣边界可以很好的来界定候选样本为正样本。
通过这个损失,整合了 Pointwise 和 Pairwise 的优点,即在整个损失中 Pointwise 但对于每个样本来说又是 Pairwise。同时明确的用户兴趣边界又从源头上缓解了困难样本的梯度消失问题。
Method
定义
个性化的用户兴趣边界: b u = W T P u b_u = W^TP_u bu=WTPu , 其中 p u p_u pu 为用户Embedding, W W W 为可学习参数。
具体的损失函数为: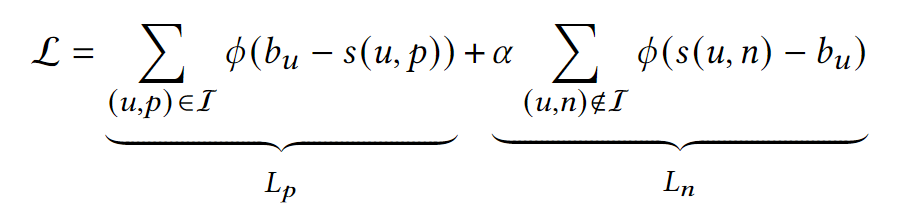
其中 s ( u , p ) s(u,p) s(u,p) 为用户u对正样本的偏好得分, s ( u , n ) s(u,n) s(u,n) 为对负样本的偏好得分, α \alpha α 为负样本的权重。
可以理解为把 Pairwise Loss 拆解由原来的 s ( u , n ) − s ( u , p ) s(u,n)-s(u,p) s(u,n)−s(u,p) 拆分成了两部分 s ( u , n ) − b u s(u,n)-b_u s(u,n)−bu 和 b u − s ( u , p ) b_u-s(u,p) bu−s(u,p) 。
用户兴趣边界
明确的边界对于许多应用也是有实际价值的,例如可以过滤掉大量没有明显价值的商品。
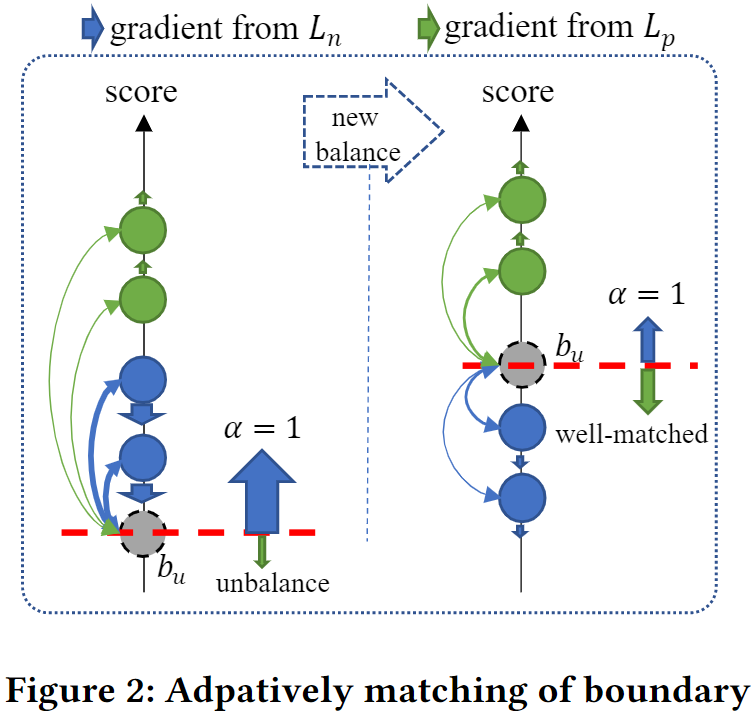
个性化且可学习的用户兴趣边界可以对每个用户进行自适应匹配。并且在正负样本之间,也就是损失函数的两个子部分之间达成共识。
缓解梯度消失问题
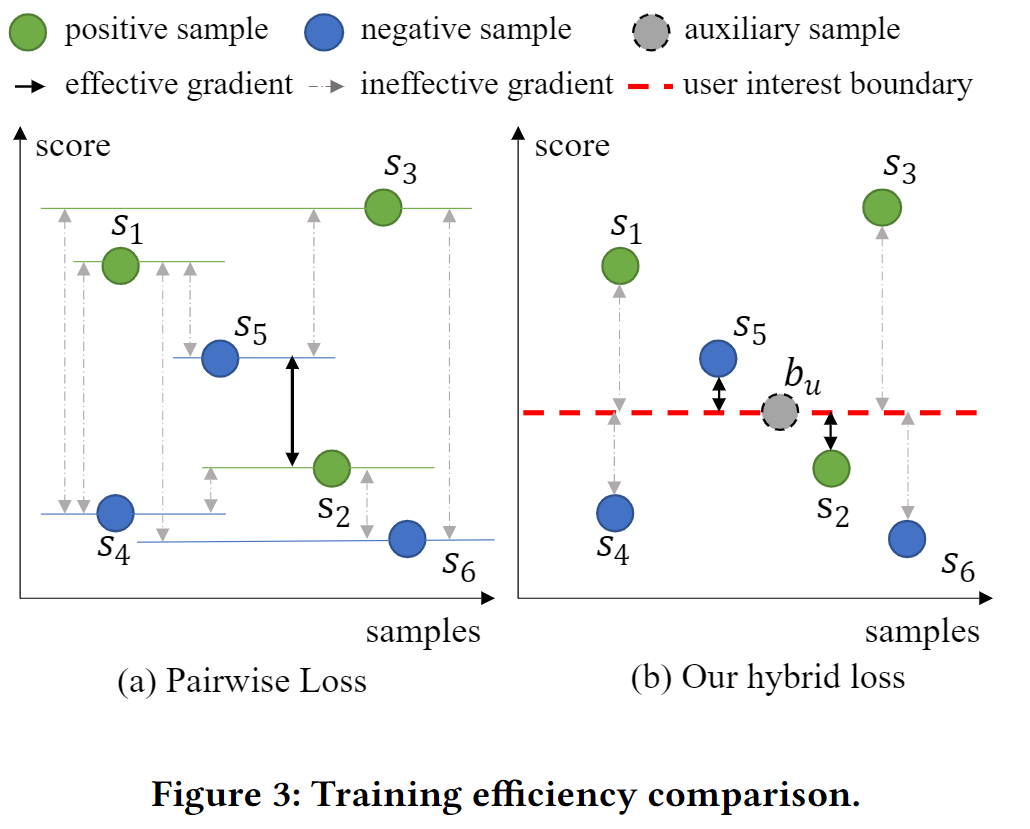
如上图所示,在 S 5 S_5 S5 和 S 2 S_2 S2 相对关系错误的情况下,Pairwise 中实际有指导意义的梯度方向只有 1 / 9 1/9 1/9 (黑色箭头占比), 而本文提出的新损失具有指导意义的梯度方向占有 1 / 3 1/3 1/3 。
类别不均衡
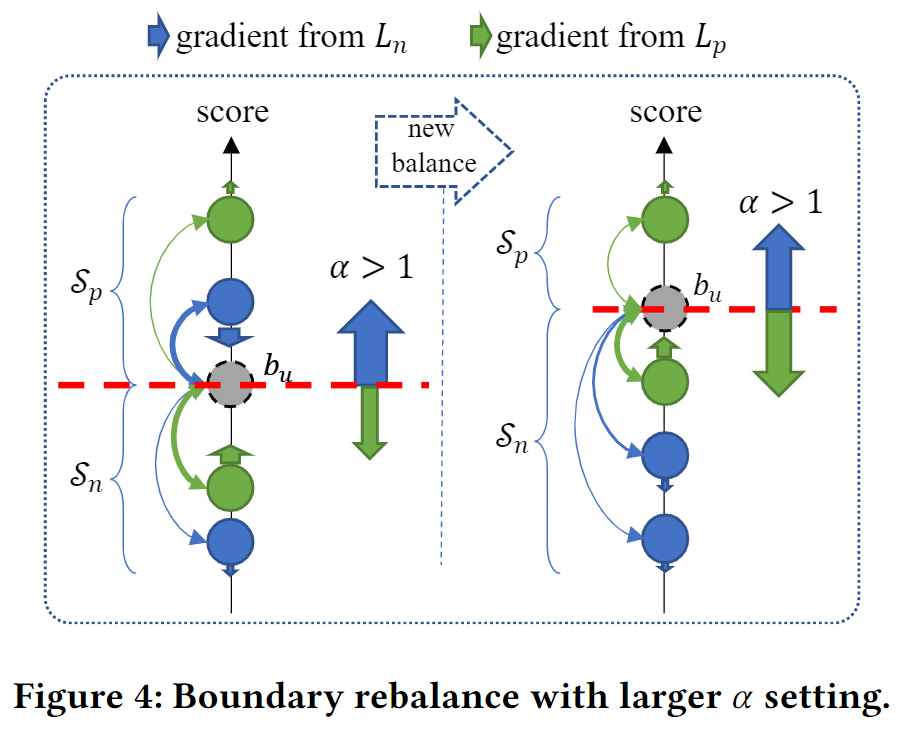
由于本文提出的损失函数把正负样本的惩罚性分为两部分,因此可以很简单的通过调节 α \alpha α 来缓解隐反馈推荐中的类别不平衡问题。
实验
对比方法

实验数据集
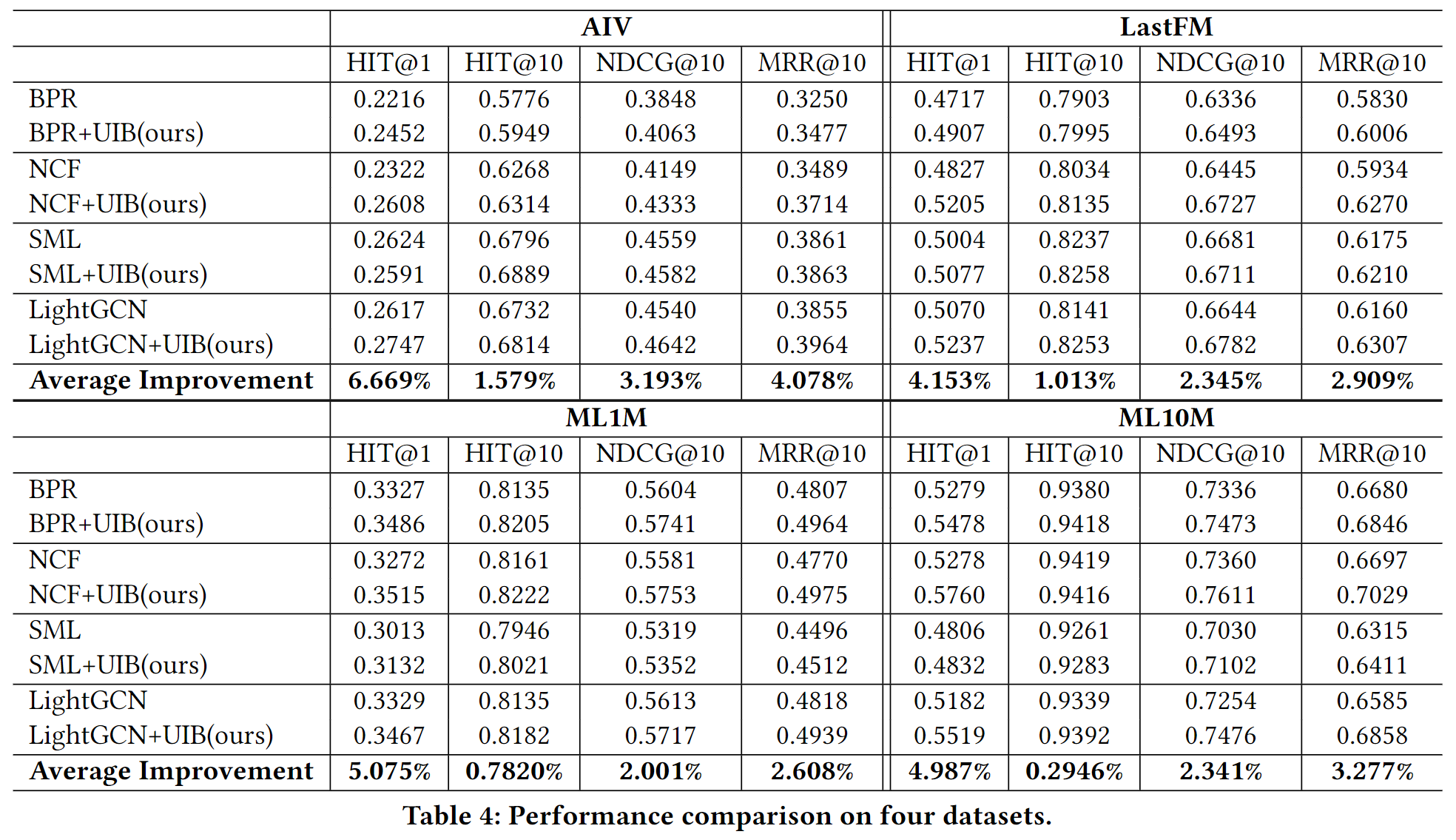
性能表现
训练效率(梯度消失问题)
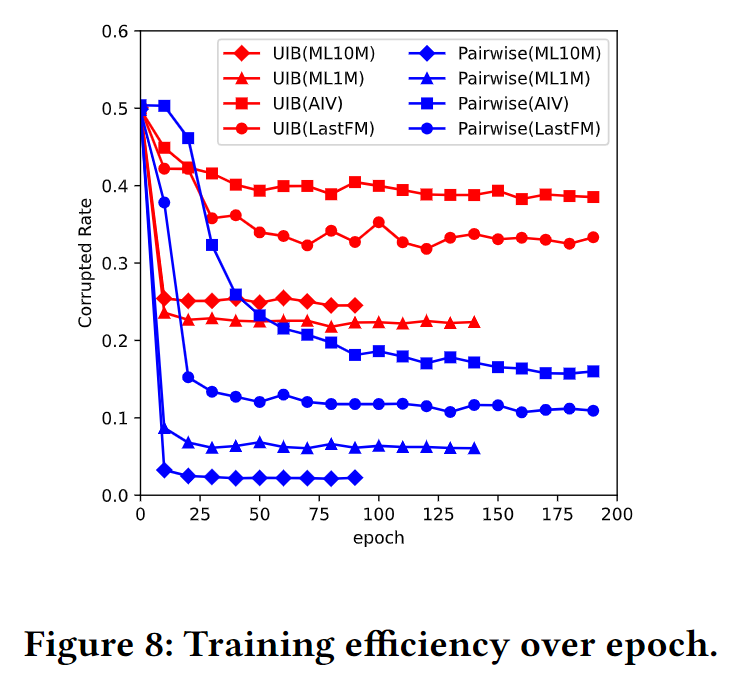
y 轴是损坏率,也就是前文中讲的有效梯度占比,由此可以看出本文提出的方法缓解了 Pairwise 的梯度消失问题。
结论
在这项工作中,本文创新地为每个用户引入了一个辅助分数来表示用户兴趣边界(UIB),并使用 Pairwise 惩罚跨越边界的样本。由此实现了逐点和成对的混合损失,以结合两者的优势。具体来说,它遵循整体损失表达式上的 Pointwise,而每个样本中的 Pairwise。分析表明,本文的方法可以提供个性化的决策边界并显着提高训练效率,而无需任何特殊的采样策略。















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









