









本人学习单建华教授在人民邮电出版社出版发行的 《卷积神经网络的Python实现》 ,将笔记记录于此。如有不详,敬请谅解,因为此笔记主要为自用。如有侵权,请联系我删除博文。
(PS:单老师书中有很多举例,非常生动形象,甚至起到“一点就通”的效果,如果大家有需要可以学习一下)
本人使用WIN10+Pycharm2017进行操作。
第一部分 模型篇
第二章 线性分类器
一、线性模型及分类器
1、机器学习模型的本质是得到由属性x到标签y的映射 f :y = f(x,w),通过最优化理论获得最优值。当y采用最简单的线性函数时,就得到线性分类器。线性函数虽然简单,却是理解神经网络和卷积神经网络的基础。线性模型和神经网络模型中,图像矩阵需要拉伸为一个向量,卷积网络不需要。
2、矩阵形式的线性模型 s = xiW + b
(s是分值行向量,b是偏置行向量,W是权重矩阵,每列由wi个列向量构成。)
如果把该模型中的每个向量或矩阵当做标量,则线性模型就变成一元一次方程,变成最简单的线性模型了。
对于线性模型,注意以下几点:
①进行多分类,只需一个矩阵乘法xiW和矩阵加法,每个分类器就是W的一个列向量。
②训练集(xi,yi)的给定且不可改变的,可变的是权重W和偏置向量b。
③模型训练的结果是得到最优参数W和b。预测样本类别时,只需计算分值向量,无需训练集。
3、线性分类器计算图像的所有像素值与权重的内积,从而得到该分类器的类别分值。(书上19-20页我不是太理解) 线性分类器只能对线性可分的样本进行有效分类,线性可分指可以用一个线性函数把多类样本分开,比如二维空间中的直线、三维空间中的平面以及高维空间中的超平面就是线性函数。线性不可分指有部分样本用线性分类器划分时会产生分类错误。对于线性不可分样本集,可以采用神经网络来分类,神经网络就是线性分类器的升级版本。
4、numpy是python开源数值计算库,存储和处理大型矩阵十分方便,比python自身的列表list结构要高效很多。
"""
numpy实现线性模型
"""
import numpy as np
D = 784 #数据维度
K = 10 #类别数
N = 128 #样本数量
X = np.random.randn(N,D) #数据矩阵,每行一个样本
W = 0.01 * np.random.randn(D,K)
b = np.zeros((1,K)) #偏置
scores = np.dot(X,W) + b #广播机制
print('The result is:',scores) #查看结果,自加
当数组的shape不一致时,numpy会使用广播机制扩展数组使得shape一致,满足广播规则,有利于编写高效简洁的程序。所以即使在上述程序中,偏置b是行向量,不是矩阵,不满足严格的矩阵运算规则,但有了广播机制这些问题也可以迎刃而解。
(自加) 程序运行结果为:

二、softmax损失函数
1、在我的这篇博文里,涉及到softmax(),可以参考:

让我们回到书中。
2、通过线性模型可以得到图像属于不同类别的分值向量,真实类别的分值对应分值向量中的最大值。
3、损失函数(loass function,也叫代价函数,cost function)用来评价分值向量的好坏。分值向量与真实标签之间的差异越大,损失函数值就越大,反之则越小。
4、“真实类别所对应的分值应当取最高分值,分值的绝对大小不能用来直接做出判断,只有相对大小或所占比例才能体现哪个更高。softmax损失函数采用所占比例判断,而SVM损失函数采用相对大小来判断。”
5、当真实类别的概率值大于阈值(如0.99),则认为损失为0,停止学习,这样可以缓解过拟合。
6、(书上P23-P24损失函数的定义,多是数学公式,未细看)
7、softmax损失函数计算(可以但没必要,在1中给出了softmax()的计算函数,非常简便)
"""
softmax()的计算
"""
import numpy as np
D = 784
K = 10
N = 128
scores = np.random.randn(N,K) #scores是分值矩阵,每行代表一个样本
y = np.random.randint(K,size = N) #样本标签
exp_scores = np.exp(scores) #指数化分值矩阵
#行求和,一行代表一个样本分值向量
exp_scores_sum = np.sum(exp_scores,axis = 1) #样本归一化函数
#获得样本对应类别的归一化分值,每行一个值,位置由标签y决定
corect_probs = exp_scores[range(N),y]/exp_scores_sum #样本真实类别的归一化分值
corect_logprobs = -np.log(corect_probs) #负对数损失函数
data_loss = np.sum(corect_logprobs)/N #平均损失
print('the average loss is',data_loss)
(自加) 程序运行结果为:
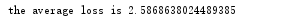
三、优化
1、寻找最优的参数,使损失最小,这就是最优化。
2、对于简单优化问题,可以使用解析法。
对于复杂优化问题,一般使用数值迭代法。梯度下降法是最优化的经典迭代法,牛顿迭代法是解方程的经典迭代法。
3、梯度下降法:最优化的经典理论。也是目前训练神经网络最常用、最有效的优化方法。
由于梯度是向量,有方向有大小,但由于学习率的调整,所以梯度大小没有意义,只有其方向才对最优化有影响。
如何选择大小合适的学习率一直是机器学习的中心问题,目前还没有解决方案,只能用试错法。
梯度下降法代码实现,以一元函数为例:
alpha = 1
epslon = 0.5 #学习率
iter_num = 100
x0 = 1
def f(x):
return alpha*x**2/2
def df(x):
return alpha*x
def GD_update(x):
return x - epslon*df(x)
x = x0
for k in range(iter_num):
x = GD_update(x)
print(k,x,f(x),df(x))















 1106
1106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









