







文章目录
1、Value-function Approximation
强化学习中的函数逼近:使用已知策略 π \pi π 生成的经验来逼近值函数 v π v_\pi vπ,且值函数是一种以权重向量 θ ∈ R n \theta \in \R^n θ∈Rn 的参数化函数形式,用 v ^ ( s , θ ) ≈ v π ( s ) \hat{v}(s,\theta) \approx v_\pi(s) v^(s,θ)≈vπ(s) 表示。
学习模拟输入-输出示例的机器学习方法称为监督学习方法。
函数逼近方法期望获得一个函数,该函数能够尽可能地逼近输入-输出行为的示例。
2、The Prediction Objective(MSVE)
需要一个判断近似预测方法质量的计算公式——均方值误差(Mean Squared Value Error,MSVE):
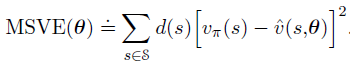
d
(
s
)
d(s)
d(s) 是 on-policy distribution,在目标策略
π
\pi
π下,在状态 s 时花费的部分时间 。
-
在 continuing tasks 中,on-policy distribution 是在 π \pi π 下的平稳分布。
-
在 episodic tasks 中,on-policy distribution 取决于初始状态的选择。
设 h(s) 表示每个状态s是一个事件开始的概率,η(s)表示花费的时间步数(从状态s开始,或者从另一个状态转移到状态s所花费的时间)
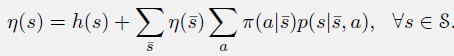
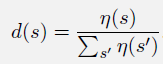
对于 MSVE, 目标就是找到全局最优的权重向量 θ ∗ \theta^* θ∗,使得 M S V E ( θ ∗ ) ≤ M S V E ( θ ) MSVE(\theta^*) \le MSVE(\theta) MSVE(θ∗)≤MSVE(θ)。
对于简单的函数逼近器,如线性逼近器,是有可能达到这个目标的;但是对于复杂的函数逼近器,如人工神经网络和决策树,实现的可能就很小,函数逼近器可能会收敛到局部最优。
3、Stochastic-gradient and Semi-gradient Methods
基于随机梯度下降法(SGD)的用于值预测的函数逼近学习方法。SGD方法是所有函数逼近方法中应用最广泛的一种,特别适合在线强化学习。
在梯度下降法中,权重向量是具有固定数量的实值分量的列向量, θ ≐ ( θ 1 , θ 2 , . . . , θ n ) T \theta \doteq (\theta_1,\theta_2,...,\theta_n)^T θ≐(θ1,θ2,...,θn)T ,逼近值函数 v ^ ( s , θ ) \hat{v}(s,\theta) v^(s,θ) 可微。我们需要在每个离散时间步 t = 0 , 1 , 2 , 3 , . . . t=0,1,2,3,... t=0,1,2,3,... 上更新 θ \theta θ,用 θ t \theta_t θt 表示每一步的权重向量。
随机梯度下降(SGD)方法是这样做的,即在每个例子之后,在最能减少该例子误差的方向上对权重向量进行少量调整:
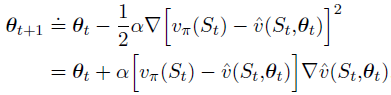
其中,
α
\alpha
α 是正的步长参数,随时间减少;
v
π
(
S
t
)
{v}_\pi(S_t)
vπ(St)是真实值,
v
^
π
(
S
t
,
θ
t
)
\hat{v}_\pi(S_t,\theta_t)
v^π(St,θt)是当前计算值;
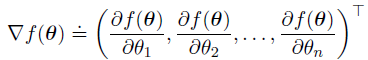
考虑目标输出,用
U
t
∈
R
U_t \in \R
Ut∈R 来表示第 t 次训练的例子(
S
t
↦
U
t
S_t \mapsto U_t
St↦Ut),而不是使用真实值
v
π
(
S
t
)
{v}_\pi(S_t)
vπ(St)。一般
v
π
(
S
t
)
{v}_\pi(S_t)
vπ(St)是未知的,可以用近似值
U
t
U_t
Ut代替。这就产生了以下状态值预测的一般SGD方法:
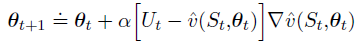
蒙特卡洛状态值估计的梯度下降算法:
半梯度方法(semi-gradient methods):
对于引导性的值估计
v
π
(
S
t
)
{v}_\pi(S_t)
vπ(St) ,由于它需要根据当前的权重向量来计算这个值(当前值的计算需要需要其他值参与计算,这就会导致权重向量的使用,
U
t
U_t
Ut中就含由
θ
\theta
θ的计算),忽略这个权重向量对目标值的影响,称为半梯度方法。
semi-gradient TD(0),使用下式作为目标:
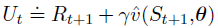

4、Linear Methods
最特殊的一种函数逼近是线性函数:
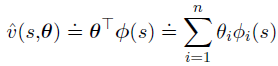
其中,特征向量为:
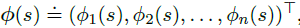
每个
ϕ
i
(
s
)
\phi_i(s)
ϕi(s) 称为基函数(basis functions)。
线性函数逼近的SGD更新:
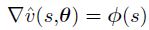
对于半梯度TD(0)算法在线性函数逼近下是局部收敛的,每个时间t的更新为:
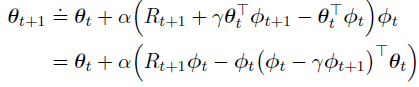
The semi-gradient n-step TD algorithm:
主要的公式为
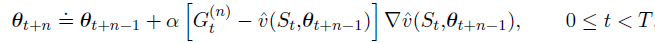
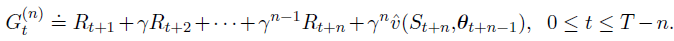

5、Feature Construction for Linear Methods
选择适合任务的特征是将先验领域知识加入强化学习系统的重要途径。直观地说,特征应该与任务的本质特征相对应,也就是泛化最合适的特征。
多项式基(Polynomials Basis)
假设有一个二维状态向量:
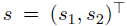
可以选择下面形式的向量作为特征:
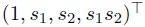
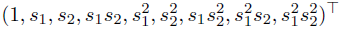
这些示例特征向量是选择多项式基函数集的结果,这些基函数集是为任意维度定义的,可以包含状态变量之间高度复杂的结合。
多项式基函数
ϕ
i
\phi_i
ϕi 通常可以写成:
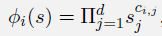
傅里叶基(Fourier Basis)
基于傅立叶级数,将周期函数表示为不同频率的正弦和余弦基函数的加权和。适用于具有多维连续状态空间和不需要周期性的函数的强化学习问题。
一般有正弦基函数和余弦基函数,一般使用余弦基函数,因为偶函数比奇函数更容易近似。
N阶傅里叶余弦基:
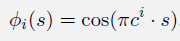
其中,
c
i
=
(
c
1
i
,
.
.
.
,
c
d
i
)
T
,
c
j
i
∈
{
0
,
.
.
.
,
N
}
,
f
o
r
j
=
1
,
.
.
.
d
a
n
d
i
=
0
,
.
.
.
.
,
(
N
+
1
)
d
c^i=(c^i_1,...,c^i_d)^T, c^i_j \in \{0,...,N\},for \ j=1,...d \ and \ i=0,....,(N+1)^d
ci=(c1i,...,cdi)T,cji∈{0,...,N},for j=1,...d and i=0,....,(N+1)d
粗编码(Coarse Coding)
考虑一个状态是连续二维的任务,状态是在二维空间的一个点,有两个分量的向量,这种情况下的一种特征是与状态空间种的圆相对应的特征,如下所示。如果状态在圆内,则对应的特征值为1,即为存在;否则,该特性为0,并被认为是不存在的。这种值为1-0特征被称为二进制特征。给定一个状态,其中的二进制特征表示该状态位于哪个圆内(每个圆是一个权重 θ \theta θ的一部分),因此对其位置进行粗编码。以这种方式表示具有重叠特性的状态称为粗编码。
一维情况,对应的就是一段区间;三维情况,就是一个球。

块编码(Tile Coding)
块编码是多维连续空间的一种粗编码形式,灵活且计算效率高。
在块编码中,特征的接受域被分组到输入空间的分区中。每个这样的分区称为tiling,而分区的每个元素称为tile。比如,二维状态空间的Tile :

径向基函数(Radial Basis Functions)
径向基函数(RBFs)是粗编码对连续值特征的推广。每个特性不再都是0或1,而是区间[0,1]内的任何值,反映特性出现的不同程度。相对于二进制特征,RBFs的主要优点是它们产生的近似函数变化平稳且可微,缺点是计算复杂度更高。
经典的RBF特征具有高斯响应
ϕ
i
(
s
)
\phi_i(s)
ϕi(s),其仅依赖于状态s和中心状态
c
i
c_i
ci之间的偏差以及相对特征宽度
σ
i
\sigma_i
σi。
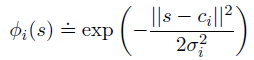
一维径向基函数:

6、Nonlinear Function Approximation: Artificial Neural Networks
人工神经网络(ANNs)在非线性函数逼近中有着广泛的应用。神经网络是由相互连接的单元组成的网络,具有神经元的一些特性,是神经系统的主要组成部分。例如,下图是一个具有四个输入单元、两个输出单元和两个隐含层的通用前馈神经网络。

神经网络学习通常采用随机梯度法。每个权值都被调整到一个方向,以提高网络的总体性能,该性能由一个目标函数来衡量,该目标函数可以最小化,也可以最大化。
在最常见的监督学习中,目标函数是一组标记的训练示例的期望误差或损失。在强化学习中,神经网络可以利用TD误差来学习价值函数,也可以以最大化期望回报为目标。
神经网络存在过拟合的缺点,解决方法:交叉验证、正则化、权值共享、dropout等。
7、Least-Squares TD
最小二乘TD算法:
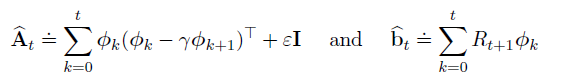
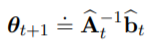

















 4410
4410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









