







2020-01-04 20:10:04
作者:Less Wright
编译:ronghuaiyang
导读
MixNet-L 比 ResNet-153 的参数少 8 倍,而 MixNet-M 的性能与之完全相同,但参数少 12 倍,FLOPS 少 31 倍。
摘要:
通过将单个卷积核替换为 3x3 - 9x9 混合分组和神经搜索“MixNet”架构,在标准的移动指标下,ImageNet top 1%的准确率达到了最新的 78.9%。MixNet-L 比 ResNet-153 的参数少 8 倍,而 MixNet-M 的性能与之完全相同,但参数少 12 倍,FLOPS 少 31 倍。
和谷歌 Brain 的 Tan 和 Le 最近在他们的论文中展示了一个新的深度卷积卷积核排布(MixConv)和一个新的神经网络架构,该架构使用 MixConvs 对效率和准确性进行了优化:Mixed depthwise convolutional kernels。
本文将总结 MixConv 的体系结构,MixNet 的核心构建块,以及 MixNet NN 体系结构本身,为你在自己的深度学习项目中使用做好准备。(就我个人而言,我计划在我们下一次的 FastAI 排行榜上使用它)。
让我们从结果开始:
MixNet 能够超越当前的移动架构套件,如下图所示,并使用 MixNet-L 创造了新的 top 1%的记录(State of the Art):
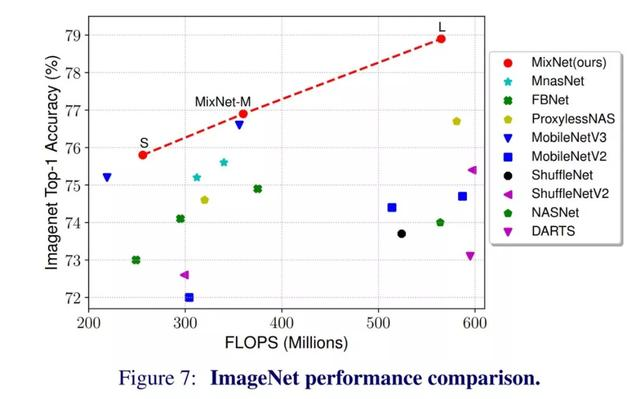
MixNet对比当前深度学习结构套件
也许更令人印象深刻的是计算效率的比较。基于移动的 AI 自然需要最高的计算效率,将 MixNet-M 和 MixNet-L 与 ResNet-153 进行比较……令人大开眼界:
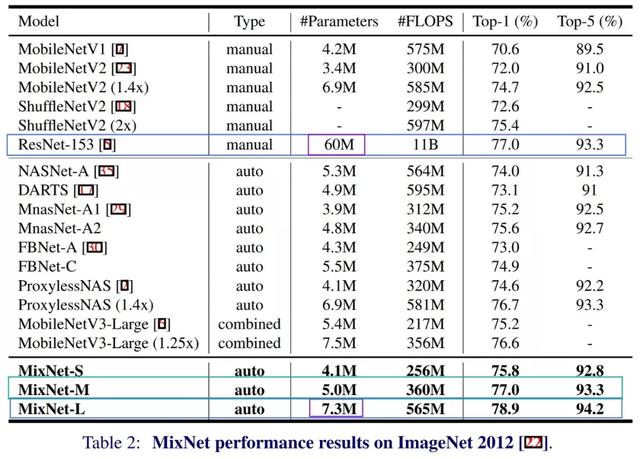
MixNet-M只有5M参数,可以匹配ResNet-153的准确率
在上面的表中,“type”指的是 NN 架构是如何构建的。manual 意思是手工构建,combined 意义是手工构建结合神经结构搜索,auto 指的是完全由神经结构进行搜索。
更重要的是,快速回顾一下性能,你就会发现 MixNet 体系结构的巨大效率。只有 5M 参数的 MixNet-M 与拥有 60M 参数的 ResNet-153 相匹配。此外,与 ResNet-153 的 11B 相比,MixNet-M 的 FLOPS 为 360M。
工作原理:
希望这些结果能让你相信,MixNet 值得你深入研究和理解,我们从“MixConvs”开始,Tan 和 Le 围绕卷积核大小对它进行了初始测试。
在一个标准的神经网络中,深度卷积通常是通过一个固定大小的核来完成的。目前大多数使用 3x3,3x3 的系列被证明比早期的 7x7 结构更有效。
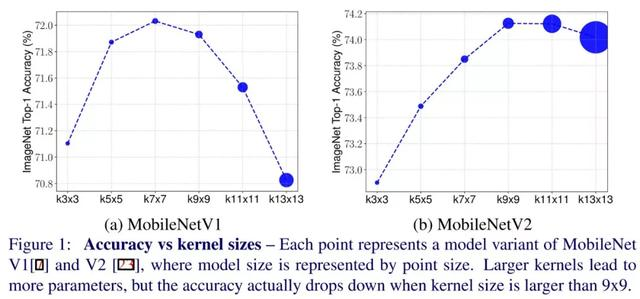
从这项研究中,他们能够辨别出混合的卷积核大小可能比单一的固定卷积核更有效,同时将最大卷积核大小限制在 9x9。
较小的卷积核(3x3, 5x5)用于捕获较低分辨率的细节,而较大的卷积核(7x7, 9x9)用于捕获较高分辨率的模式。从而最终建立一个更高效的网络。
MixConvs — 基于上述直觉,开发了将多个卷积核大小混合到单层中的概念,并将其命名为“MixConvs”。
MixConv 将传入的通道划分为组,并对这些组运行各种大小的卷积核。论文中的这个例子说明了:
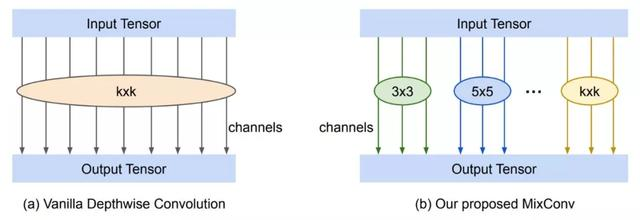
MixConvs将传入的通道分组,并在所有通道上运行各种大小的卷积核,而不是典型的单一卷积核大小
结果是,通过组合不同大小的卷积核,可以捕获低分辨率和高分辨率模式,从而生成更准确、更高效的深度卷积块。
论文中的一个代码示例(TensorFlow)有助于理解这个过程:

MixConvs 变为 MixNets:为了将 MixConv 提升到更优的形式,作者必须确定应该使用哪种混合的卷积核大小,即组大小。最终,使用 1-5 个卷积核被认为是最好的标准,通过利用神经结构搜索,最终构建了一个 MixNet-M。MixNet-L 是简化的 MixNet-M,深度乘了 1.3。下面是 MixNet-M 架构,展示了不同的卷积核组:
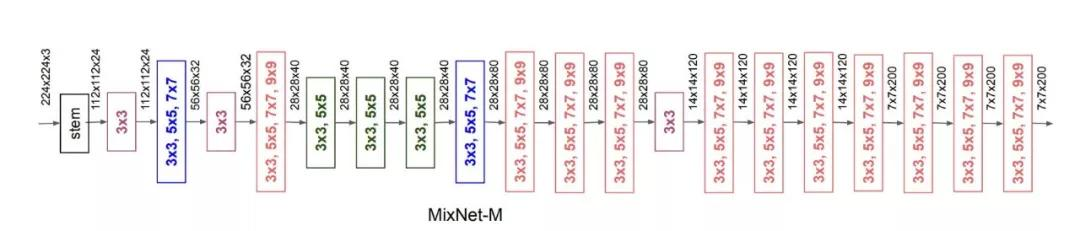
MixNet-M架构,MixNet-L只是一个1.3倍深度的-M。
正如你所看到的,一开始使用的小卷积核与现代 ResNets 当前的趋势类似。然而,当数据流经这些层时,更大的卷积核会被稳定地集成进来。与单个卷积核卷积不同,较大的卷积核通常会降低精度,混合 MixConv 利用 7x7 和 9x9 卷积核有效地捕获更高的分辨率的模式。
简而言之,最终的 MixNet 架构的性能结果也许可以通过与 ResNet-153 的比较得到最好的总结。除了在移动计算能力(< 600M FLOPS)上创造了 ImageNet 1%精确度的最新记录外,它还击败了一般的 ResNet-153,同时使用的参数和 FLOPS 几乎少了一个数量级:
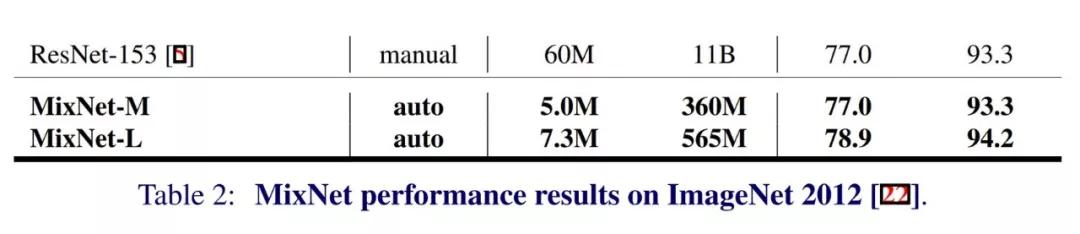
MixNet-M和-L与ResNet-153的直接比较
在你的项目中使用 MixNet:对于 TensorFlow 用户来说,你很幸运,因为 MixNet 已经开源,可以在 github 上找到:
tensorflow/tpu1\] Mingxing Tan and Quoc V. Le. MixConv: Mixed Depthwise Convolutional Kernels. BMVC 2019…github.com
PyTorch 和 FastAI 用户:这里有个非官方的 PyTorch 实现:
romulus0914/MixNet-PytorchA PyTorch implementation of MixNet A PyTorch implementation of MixNet architecture: MixNet: Mixed Depthwise…github.com[
结论: MixNet 通过混合一些卷积核大小和一个新的架构,对提高神经网络的效率和准确性做出了令人印象深刻的贡献。MixNet 是用更好的架构推动深度学习向前发展的一个经典例子,而不是仅仅增加计算能力来获得更好的结果。祝贺研究人员在 AI 方面的进步和 MixNet 架构的开源!
英文原文:https://medium.com/@lessw/meet-mixnet-google-brains-new-state-of-the-art-mobile-ai-architecture-bd6c37abfa3a

















 3544
3544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









