







2020-05-06 12:32:00
不到现场,照样看最干货的学术报告!
嗨,大家好。这里是学术报告专栏,读芯术小编不定期挑选并亲自跑会,为大家奉献科技领域最优秀的学术报告,为同学们记录报告干货,并想方设法搞到一手的PPT和现场视频——足够干货,足够新鲜!话不多说,快快看过来,希望这些优秀的青年学者、专家杰青的学术报告 ,能让您在业余时间的知识阅读更有价值。
人工智能论坛如今浩如烟海,有硬货、有干货的讲座却百里挑一。“AI未来说·青年学术论坛”系列讲座由中国科学院大学主办,百度全力支持,读芯术、paperweekly作为合作自媒体。承办单位为中国科学院大学学生会,协办单位为中国科学院计算所研究生会、网络中心研究生会、人工智能学院学生会、化学工程学院学生会、公共政策与管理学院学生会、微电子学院学生会。2020年4月26日,第14期“AI未来说·青年学术论坛”深度学习线上专场论坛以“线上平台直播+微信社群图文直播”形式举行。中国科学院大学徐俊刚带来报告《自动深度学习解读》。
徐俊刚,中国科学院大学教授,博士生导师,云计算与智能信息处理实验室主任,中国科学院大学《深度学习》课程首席教授。研究方向为大数据与人工智能,主要包括行业大数据分析、自动机器学习、自然语言处理、计算机视觉等。国家科技专家库专家,北京市科委专家,贵安新区战略咨询研究院专家。中国计算机学会人工智能与模式识别专委会委员、中文信息技术专委会委员、数据库专委会委员,中国人工智能学会智能服务专委会常务委员。主持国家科技支撑计划、国家自然科学基金、北京市科技计划、北京市自然科学基金等科研项目多项,发表文章100余篇。获2016年度中国科学院朱李月华优秀教师奖。
报告内容:自动机器学习是实现强人工智能的必备技术之一,必将成为下一个人工智能研究的热点。作为自动机器学习重要分支的自动深度学习备受人们关注。通过介绍目前自动深度学习的一些主要算法和应用案例,解读自动深度学习面临的主要问题,同时指出未来的研究重点以及主要研究方向。

自动深度学习解读

徐老师讲座的第一部分是自动深度学习概述。下图(引自NVIDIA)从两方面介绍人工智能、机器学习和深度学习的关系:一方面,在时间轴上,人工智能自1956年提出后开始发展,到1980年的时候机器学习开始繁荣,2010年之后深度学习在图像处理和语音识别领域取得了突破,使人工智能进一步繁荣起来;另一方面,从包含关系上,机器学习也是人工智能的重要分支之一,而深度学习是机器学习的重要组成部分。
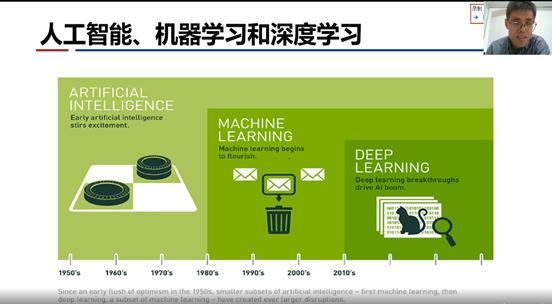
机器学习和深度学习的不同在于:机器学习在输入数据(以图像为例)之后,首先需要人工来进行特征提取,比如图片的纹理、颜色、轮廓等等,基于这些特征再去做分类;而深度学习不需要人工进行特征提取,完全靠神经网络就可以提取特征然后再做分类,最后判断出类别,这样省掉了大部分人工提取特征的工作。
深度学习和自动深度学习的不同在于:深度学习中虽然特征提取和分类都可以由神经网络自动来做,但是神经网络结构还需要人工设计,超参数还需要人工调整;而自动深度学习中神经网络结构设计和超参数调优也可以自动进行,可以把自动深度学习看作一个黑箱。
现在的机器学习、深度学习只能模拟人的部分功能,但希望未来强人工智能能够模拟人的全部功能,并形成具有自我意识的智能机器。自动机器学习是强人工智能的重要分支之一,要实现强人工智能,自动机器学习是必备技术之一,当然自动深度学习又是自动机器学习的组成部分。自动机器学习用算法学习机器学习(Machine learning,ML)算法,自动深度学习用算法学习深度学习(Deep learning, DL)算法(结构),来替代深度学习中的人工操作。
在自动深度学习平台(参见下图)中,首先可以对计算机视觉、自然语言处理等任务中的数据做自动标注,然后将自动标注后的数据输入到NAS和超参数自动调优算法里面,同时可以和迁移学习、元学习进行结合。迁移学习可以把预训练模型迁移到本任务中进行微调,元学习允许模型通过少量的样本就可以完成学习,这两者跟NAS和超参数自动调优算法可以互相交互。
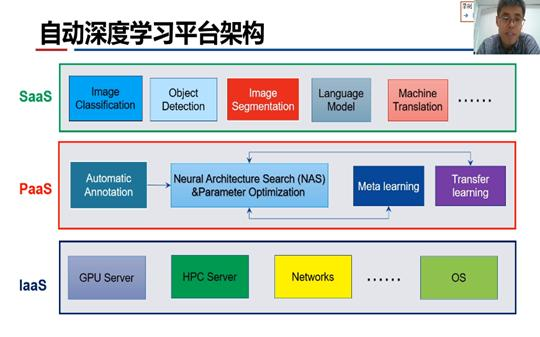
上图从底层到高层介绍了三个层次的自动深度学习平台的架构。底层的IaaS平台使用GPU服务器、高性能服务器、网络和操作系统等来构建,中间的PaaS平台提供自动深度学习应用开发服务,高层的SaaS平台提供基于自动深度学习的应用服务,如图像分类、目标检测、图像分割等计算机视觉应用服务,语言模型、机器翻译、自动摘要等自然语言处理应用服务。通过提供基于自动深度学习的SaaS应用,可以大幅减少甚至免除人工网络结构设计和超参数调优工作,进而大大提高工作效率,降低AI的准入门槛,可以解决AI人才短缺的问题。
徐老师讲座的第二部分介绍自动深度学习核心算法,包括神经架构搜索和超参数优化。
神经架构搜索由搜索空间、搜索策略和评估策略组成。首先确定搜索空间,用搜索策略找出一些结构出来,用评估策略评估每次找到的网络结构,最终确定一个最优结构。目前主流的搜索空间定义分两层:微结构和宏结构。微结构只是搜索一个局部的网络结构(非完整结构),之后将其当成组件按照一定规则堆叠形成宏结构(完整结构)。堆叠方式现在主要有两种:一种是链式堆叠,另外一种是多分支结构。目前主流做法是链式堆叠,多分支结构方面的研究工作还较少。
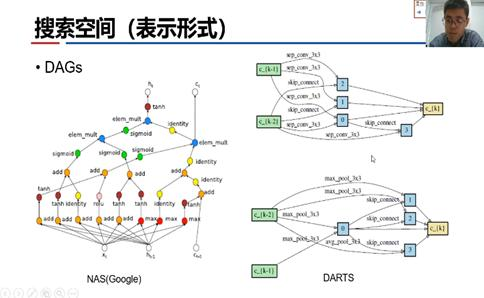
搜索空间一般用有向无环图(Directed Acyclic Graph, DAG)表示。下图中左侧的NAS(Google)用节点定义运算或操作,边表示数据及其流动方向;右侧的DARTS节点是输入数据或中间数据,边是运算或操作,有些不同。当然搜索空间需要预定义一些操作,如恒等操作、卷积操作、空洞卷积、池化操作、深度可分离卷积等(以NASNet为例)。
搜索策略有三大类:基于强化学习的搜索策略、基于进化算法的搜索策略以及基于梯度的搜索策略。
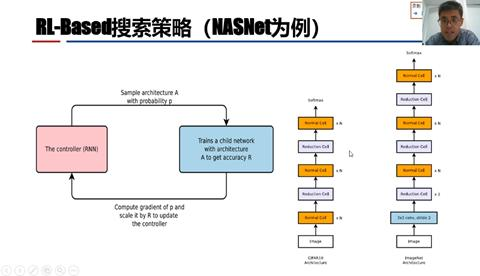
第一种是基于强化学习的搜索策略,以NASNet为例。它使用强化学习的架构,控制器是RNN,把每个微结构划分为若干状态和操作,在t个时间步内依次概率采样出对应的结构(状态、操作)形成微结构,对微结构进行训练得到精度后再计算概率梯度更新控制器。在NASNet中提出了Normal Cell和Reduction Cell的概念,Normal Cell不需要对特征图的大小进行改变,而Reduction Cell需要缩小特征图。
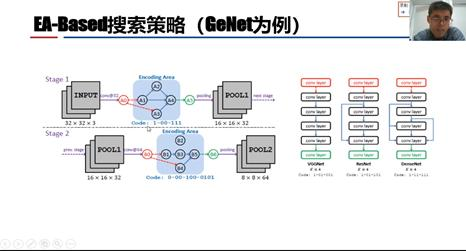
第二种是基于进化算法的搜索策略,以GeNet为例。它对网络结构种群进行编码,如下图左上部分所示,两个节点A1和A2之间有连接,用1表示,A1和A3之间没有连接,用0表示。下图右半部分是典型卷积深度网络VGGNet、ResNet、DenseNet对应的编码。编码后就可以进行选择、交叉、变异、评估,最终输出一个最优的结构。
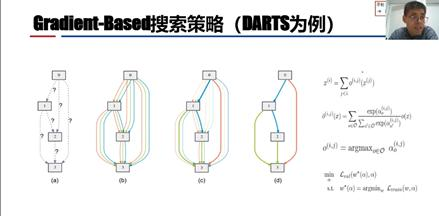
第三种是基于梯度的搜索策略,以DARTS为例。前面介绍的算法使用的是离散的网络结构,而DARTS将离散结构连续化,如下图所示。假设网络结构有四个节点,一开始相关操作是未知的,后面把操作加上来,它的核心思想是最大化节点之间边(操作)的概率。在与目前主流NAS算法对比中,DARTS在CIFAR10数据集上的图像分类测试错误率和搜索成本都得到了降低。徐老师的实验室在DARTS上引入注意力机制,做了一些新的研究工作。
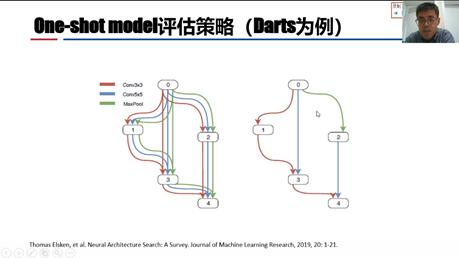
评估策略有三种方法,首先是性能估计方法,它使用数据集的子集进行评估,不需要考虑全部数据。One-shot model方法在DARTS及其变种中用的比较多,它训练的是包括所有可能操作的超图,之后选择它的全部子图进行评估,示意图如下。权重共享的方法会记忆每条边的权重,边携带自己的权重出现在不同的微结构中。
NAS策略介绍完毕后,徐老师接着介绍了超参数优化,主要包括网格搜索、随机搜索、贝叶斯优化和进化算法等。网格搜索和随机搜索比较好理解。贝叶斯优化首先随机生成超参数组合,接着对超参数组合做高斯过程建模,并对这些采集点(超参数组合)做预测,之后迭代更新超参数组合,通过置信区间约束超参数的更新范围,最终找到比较好的超参数组合出来。还可以通过遗传算法等进化算法对超参数进行优化,Deepmind提出了一种基于遗传算法的超参数优化算法,比贝叶斯优化性能要好。
目前NAS存在的问题有:搜索空间的表示形式不一,有些算法用节点表示操作,有的用边表示操作;而且宏结构形式单一,目前多分支结构还比较少;DAG节点和边数量固定、有限,等等。此外,NAS目前在CV领域应用比较多,其他领域应用还比较少。而在超参数优化中,某些超参数是非凸性的,导致求解困难,而且还有组合爆炸问题。另一个问题是混合优化问题,有些超参数的类型不一样,导致混合优化比较困难。同时,贝叶斯优化不适合高维超参数优化场景。
徐老师最后展望了自动深度学习的未来研究方向:在微结构中探索可变的DAG设计,以扩大搜索空间;在宏结构中探索多分支结构设计;可以探索与量子算法、图神经网络结合的NAS算法;开发通用的NAS-Bench,目前的基准测试集徐老师觉得还不是很通用,还能进一步实现多数搜索所得结构性能的查询。徐老师还建议将NAS和超参数优化结合起来,形成一阶段同时完成两项任务;他还建议将NAS跟元学习紧密结合。而在应用方面希望能够探索更多应用,如图像描述、机器翻译、自动摘要、自动写作、图像生成和视频生成等等;基于多源数据融合的应用目前仍有较大探索空间。

















 3058
3058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









