







1、SRN网络结构
2、Backbone Network
3、Parallel Visual Attention Module(PVAM)
4、Global Semantic Reasoning Module(GSRM)
5、Visual Semantic Fusion Decoder(VSFD)
1、SRN网络结构

图1 SRN网络流程图
如上图所示,SRN主要由四部组成:主干网络、并行视觉提取模块(PVAM)、全局语义推理模块(GSRM)和视觉语义融合解码器(VSFD)。其主要流程为:
(1) 使用主干网络(ResNet50+FPN)提取二维特征,并利用Transformer unit增强视觉特征
(2) 使用PVAM生成N个对齐的一维特征G,其中每个特征对应于文本中的一个字符,并捕获对齐的视觉信息G
(3) 将一维特征输入到GSRM以捕获语义信息S
(4)使用VSFD融合视觉特征G和语义信息S,预测N个字符
对于短于n的文本字符串,将填充"EOS"
2、Backbone Network
使用 FPN 从 ResNet50 的 stage-3, stage-4 和 stage-5 聚合特征图。使用 transformer unit ( 位置编码,多头注意力,前馈网络 ) 捕获全局空间依赖。将特征图输入到 2 个 transformer units 中,提取出增强的视觉特征。其主要借鉴传统图相处理中的非局部均值滤波,该方法对于像素相似的区域给与较大权重,针对相似相差较大的区域给予小权重。
3、Parallel Visual Attention Module(PVAM)
key-value 为输入的 2D 视觉特征 (𝑣𝑖𝑗v_ij, 𝑣𝑖𝑗v_ij) ,Bahdanau attention 使用上一时刻的隐藏状态生成当前时刻的特征,为了并行计算,该算法使用阅读顺序作为 query 代替上一时刻的隐藏状态,比如第一个字符为 0,第二个字符为 1 。如下公式:


4、 Global Semantic Reasoning Module(GSRM)
之前的单向串行传输 ( 类 RNN 结构 ) : 首先它只可以感知到局部信息,甚至在解码第一步没有使用语义信息;其次,当在较早的时间步上产生错误的解码时,它可能会传递错误的语义信息并导致错误累积,很大可能造成之后的解码产生错误的结果。
本文提出GSRM克服以上问题,以多路并行传输方式来考虑全局语义上下文,多路并行传输可以同时感知全部字符的语义信息。同时,单个字符的错误语义内容只能对其他步骤造成非常有限的负面影响。

图2 单向串行传输与多路并行传输对比
该模块主要包括两部分: visual-to-semantic embedding block 和 semantic reasoning block。其中, visual-to-semantic embedding block为了避免Attention的时间依赖性,不使用真实的word embedding作为输入,所以该模块是生成近似的word embedding。首先将PVAM的输出G输入到全连接层中,经过softmax,然后通过argmax和embedding layer,生成近似的Word embedding作为 semantic reasoning block的输入。 semantic reasoning block利用Transformer unit生成视觉特征对应的语义信息。
5、Visual-Semantic Fusion Decoder
使用门控单元控制视觉信息和语义信息的比重,公式如下:

其中,𝑊𝑧是是训练权重,𝑓𝑡是第t个融合向量t∈1,𝑁∈[1,N]。全部的融合特征为F,用来预测最终的字符。
最终的损失函叔为:

其中,
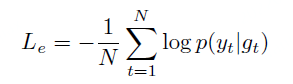
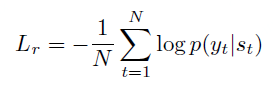
















 4579
4579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









