









说明:这是一个机器学习实战项目(附带数据+代码),如需数据+完整代码可以直接到文章最后获取。
1.问题定义
在日常银行、电商等公司中,随着时间的推移,都会积累一些客户的数据。在当前的大数据时代、人工智能时代,数据就是无比的财富。并且消费者需求显现出日益差异化和个性化的趋势。随着我国市场化程度的逐步深入,以及信息技术的不断渗透,对大数据的分析已是必然趋势。本案例就是使用机器学习聚类算法对客户进行分组,为销售人员进行精准营销提供帮助。
2.数据收集
本数据是模拟数据:
数据集:data.xcsv
在实际应用中,根据自己的数据进行替换即可。
特征:
Gender:性别
Age:年龄
Income:年收入
Spending:消费分数
3.数据预处理
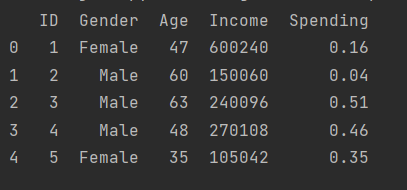
1)原始数据描述:
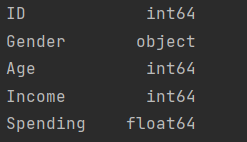
2)数据完整性、数据类型查看:
print(data.dtypes)
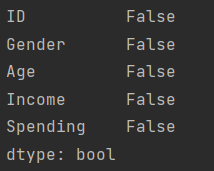
3)数据缺失值查看:
print(data.isnull().any())
可以看到数据不存在缺失值。
4.探索性数据分析
1)特征变量年收入分析:
2)特征变量消费分数分析:
3)相关性分析
说明:正值是正相关、负值时负相关,值越大变量之间的相关性越强。
5.聚类模型
1)确定K值
for i in range(1, 11): # 尝试不同的K值 kmeans = KMeans(n_clusters=i, init='k-means++', random_state=0) kmeans.fit(X) cost.append(kmeans.inertia_) # inertia_ 是我们选择的方法,其作用相当于损失函数通过手肘图法进行确定K值,手肘图如下:
通过手肘图上判断,肘部数字大概是3或4,我们选择4作为聚类个数。
2)建立聚类模型,模型参数如下:
kmeansmodel = KMeans(n_clusters=4, init='k-means++')
编号
参数
1
n_clusters=4
2
init='k-means++'
其它参数根据具体数据,具体设置。
3)聚类算法结果输出
r1 = pd.Series(kmeansmodel.labels_).value_counts() # 统计各个类别的数目 r2 = pd.DataFrame(kmeansmodel.cluster_centers_) # 找出聚类中心 r = pd.concat([r2, r1], axis=1) # 横向连接(0是纵向),得到聚类中心对应的类别下的数目 r.columns = list(data_tmp.columns) + ['类别数目'] # 重命名表头 print(r)
分群类别
第一类
第二类
第三类
第四类
样本个数
68
50
20
62
样本占比个数
34.00%
25.00%
10.00%
31.00%
聚类中心
Income
273933.0588
137054.8000
548719.4000
389187.8710
Spending
0.500147
0.494800
0.520000
0.504032
从上述表格可以看出,分群1占比34%,分群2占比25%,分群3占比10%,分群4占比31%。
6.聚类可视化
1) 客户聚类结果图
plt.scatter(X[y_kmeans == 0, 0], X[y_kmeans == 0, 1], s=100, c='cyan', label='Cluster 1') plt.scatter(X[y_kmeans == 1, 0], X[y_kmeans == 1, 1], s=100, c='blue', label='Cluster 2') plt.scatter(X[y_kmeans == 2, 0], X[y_kmeans == 2, 1], s=100, c='green', label='Cluster 3') plt.scatter(X[y_kmeans == 3, 0], X[y_kmeans == 3, 1], s=100, c='red', label='Cluster 4') plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='yellow', label='Centroids') plt.title('Clusters of customers') plt.xlabel('Income') plt.ylabel('Spending Score') plt.legend()
通过上图可以看到,黄色高亮得大点是聚类的质心,可以看到算法中的质心并不止一个。
2)聚类概率密度图
聚类群1的概率密度图:
聚类群2的概率密度图:
聚类群3的概率密度图:
聚类群4的概率密度图:
1)分群1特点:年收入集中在30万,消费分数集中在0.50左右;
2)分群2特点:年收入集中在10万~15万,消费分数集中在0.25和0.75;
3)分群3特点:年收入集中在50万,消费分数集中在0.30和0.80;
4)分群4特点:年收入集中在35万~40万万,消费分数集中在0.10和0.80;
5)比对分析:分群3年收入高、分数高属于高价值人群;分群4年收入良好、消费分数综合良好,属于中等人群;分群1年收入一般、消费分数一般,属于一般人群;分群2年收入低、消费分数中等,属于价格较低的客户群体。
7.实际应用
根据数据聚类结果对客户的分组,在后面展开的营销活动中,我们可以采取差异化手段进行客户分类的精准营销,以提高消费成功率,使客户的整体消费感受更好。
聚类结果如下:













# 本次机器学习项目实战所需的资料,项目资源如下: # 项目说明: # 获取方式一: # 项目实战合集导航: https://docs.qq.com/sheet/DTVd0Y2NNQUlWcmd6?tab=BB08J2 # 获取方式二: 链接:https://pan.baidu.com/s/1R2ux6m1nEIyGrQ1t3FU41A 提取码:ysj5
















 3063
3063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











