









说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

1.项目背景
在全球化的今天,收入不平等已经成为各国政府和社会关注的焦点问题之一。了解居民收入状况,特别是区分收入水平是否超过一定阈值(如5万美元),对于政策制定者、社会学家和经济学家而言至关重要。这不仅有助于揭示社会经济结构的现状,而且对于制定针对性的社会保障政策、税收政策以及经济发展战略具有深远影响。
随着大数据和机器学习技术的迅猛发展,我们拥有了前所未有的工具来分析和预测复杂的经济现象。利用居民的年龄,工作类型,受教育程度等多维度数据,构建预测模型,能够帮助我们更准确地预测个体的收入水平。特别是在美国这样的经济体中,能否达到5万美元的年收入往往被视为中产阶级的门槛,对个人的生活质量、消费模式乃至社会流动性有着显著影响。
本项目致力于开发基于机器学习的居民收入预测模型,主要聚焦于预测个体年收入是否超过5万美元。我们的目标是:
通过实施本项目,我们期望能够为理解和解决收入不平等问题提供有力的技术支撑。预测模型的建立不仅可以帮助政府和相关机构提前规划,还能够为个人的职业规划和财务决策提供参考,促进社会的整体福祉。此外,项目成果还将丰富学术界对收入预测领域的研究,为后续的理论创新和应用开发奠定坚实的基础。
本项目通过决策树分类模型、随机森林分类模型、KNN分类模型和GBDT分类模型完成收入预测。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
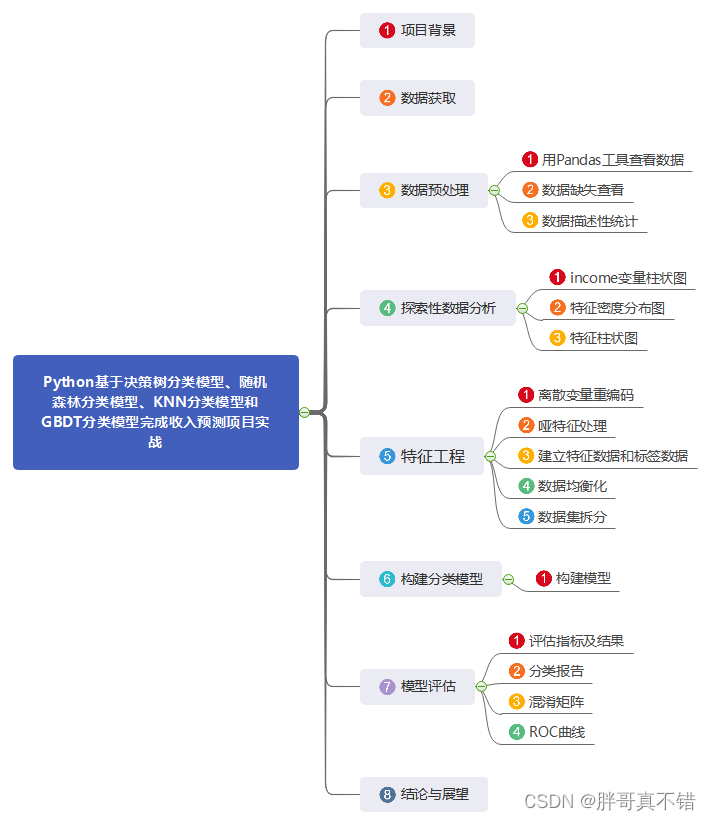
| 编号 | 变量名称 | 描述 |
| 1 | age | 年龄 |
| 2 | workclass | 工作类型 |
| 3 | fnlwgt | 序号 |
| 4 | education | 受教育程度 |
| 5 | education-num | 受教育时长 |
| 6 | marital-status | 婚姻状态 |
| 7 | occupation | 职业 |
| 8 | relationship | 家庭成员关系 |
| 9 | race | 种族 |
| 10 | sex | 性别 |
| 11 | capital-gain | 资本收益 |
| 12 | capital-loss | 资本损失 |
| 13 | hours-per-week | 每周工作小时数 |
| 14 | native-country | 国籍 |
| 15 | income | 收入 |
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
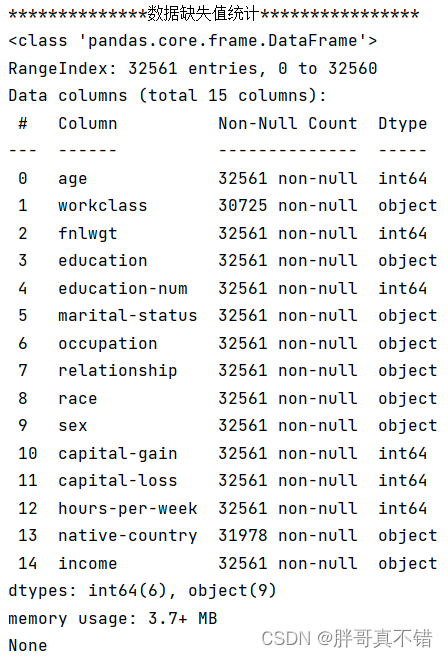

从上图可以看到,总共有15个变量,数据中有缺失值,工作类型缺失值1836条、国籍缺失值583条,共有32561条数据。
关键代码:

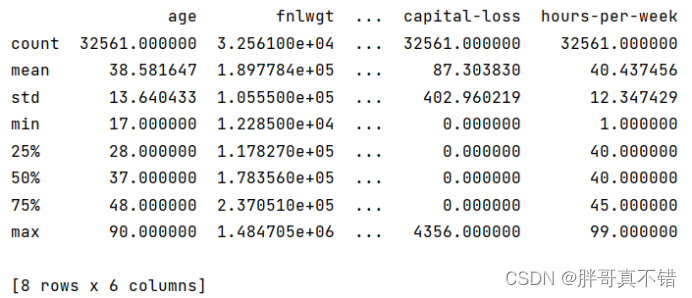
3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:

4.探索性数据分析
4.1 income变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:

4.2 特征密度分布图
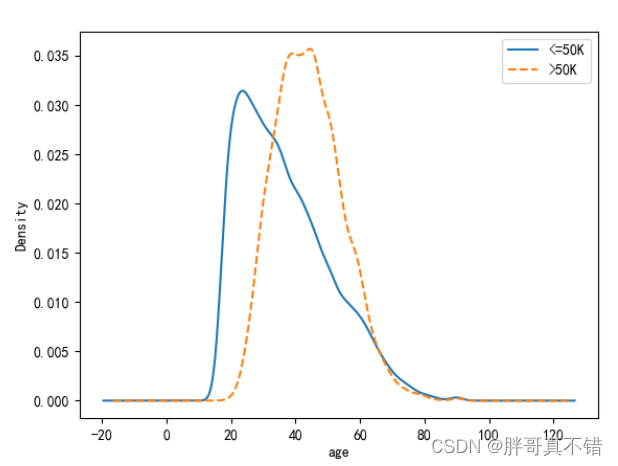
通过上图可以看出,在不同收入水平下,年龄的核密度分布图,对于年收入超过5万美元的居民来说,他们的年龄几乎呈现正态分布,而收入低于5万美元的居民,年龄呈现右偏特征,即年龄偏大的居民人数要比年龄偏小的人数多。
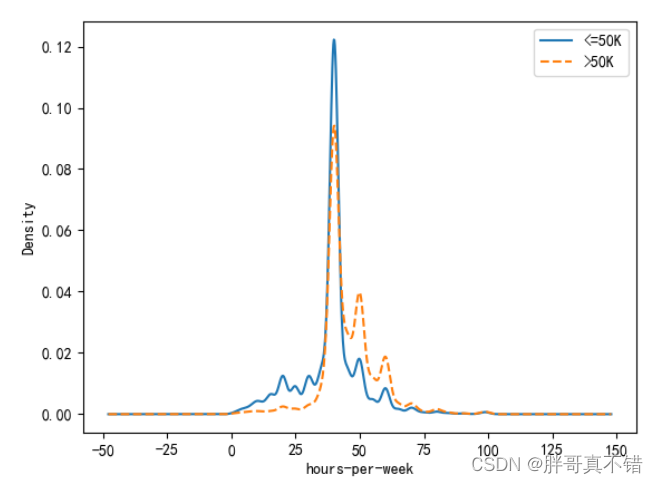
通过上图可以看出,不同收入水平下,周工作小时数的核密度图,很明显,两者的分布趋势非常相似,并且出现局部峰值。
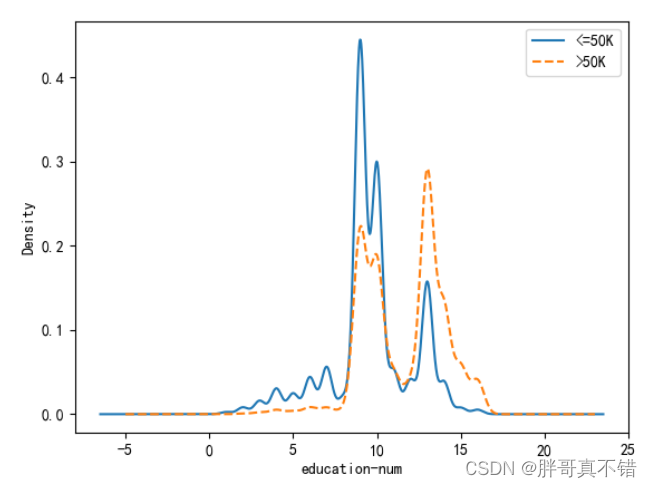
通过上图可以看出,不同收入水平下,教育时长的核密度图,很明显,两者的分布趋势非常相似,并且也多次出现局部峰值。
4.3 特征柱状图

通过上图可以看出,相同的种族下,居民年收入水平高低的人数差异。
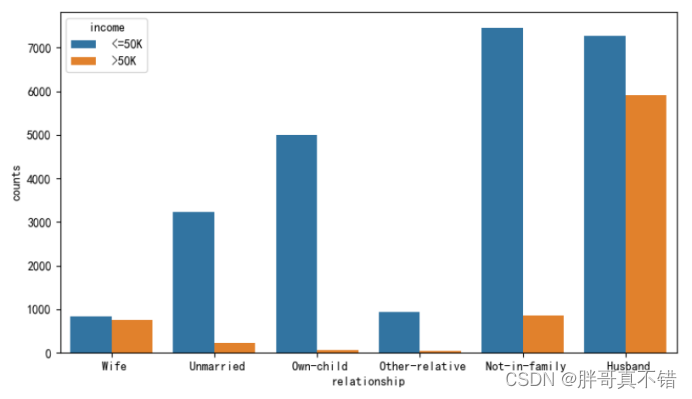
通过上图可以看出,相同的家庭成员关系下,居民年收入水平高低的人数差异。但无论怎么比较,都发现一个规律,即在某一个相同的水平下(如白种人或未结婚人群中),年收入低于5万美元的人数都要比年收入高于5万美元的人数多,这个应该是抽样导致的差异(数据集中年收入低于5万和高于5万的居民比例大致在75%:25%)。

通过上图可以看出,相同的性别下,居民收入水平高低人数的差异;其中,女性收入低于5万美元的人数比高于5万美元人数的差异比男性更严重,比例大致为90%:10%, 男性大致为70%:30%。
5.特征工程
5.1离散变量重编码
如下是编码后的结果展示:
5.2 哑特征处理
关键代码如下:

5.3 建立特征数据和标签数据
关键代码如下:

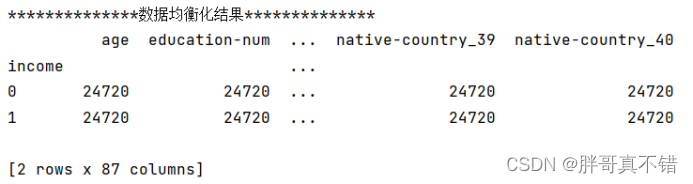
5.4 数据均衡化
采用过采样工具进行数据均衡化,结果如下:
5.5 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:
![]()
6.构建分类模型
主要使用决策树分类算法、随机森林分类算法、KNN分类算法和GBDT分类算法,用于目标分类。
6.1 构建模型
| 编号 | 模型名称 | 参数 |
| 1 | 决策树分类模型 | 默认参数值 |
| 2 | random_state=123 | |
| 3 | 随机森林分类模型 | 默认参数值 |
| 4 | random_state=42 | |
| 5 | KNN分类模型 | 默认参数值 |
| 6 | GBDT分类模型 | 默认参数值 |
| 7 | random_state=42 |
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
| 模型名称 | 指标名称 | 指标值 |
| 测试集 | ||
| 决策树分类模型 | 准确率 | 0.8680 |
| 查准率 | 0.8574 | |
| 查全率 | 0.8832 | |
| F1分值 | 0.8701 | |
| 随机森林分类模型 | 准确率 | 0.8925 |
| 查准率 | 0.8855 | |
| 查全率 | 0.9018 | |
| F1分值 | 0.8936 | |
| KNN分类模型 | 准确率 | 0.8545 |
| 查准率 | 0.7979 | |
| 查全率 | 0.9499 | |
| F1分值 | 0.8673 | |
| GBDT分类模型 | 准确率 | 0.8642 |
| 查准率 | 0.8403 | |
| 查全率 | 0.8996 | |
| F1分值 | 0.869 | |
从上表可以看出,4个模型的F1分值都在0.8以上,说明4个模型在月亮数据集上效果良好,其中随机森林表现最好。
7.2 分类报告
决策树分类模型:
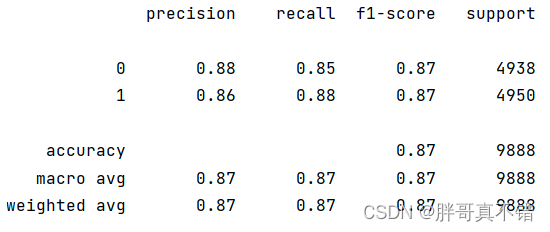
从上图可以看出,分类为0的F1分值为0.87;分类为1的F1分值为0.87。
随机森林分类模型:

从上图可以看出,分类为0的F1分值为0.89;分类为1的F1分值为0.89。
KNN分类模型:
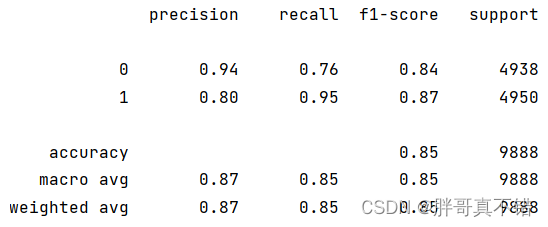
从上图可以看出,分类为0的F1分值为0.84;分类为1的F1分值为0.87。
GBDT分类模型:

从上图可以看出,分类为0的F1分值为0.86;分类为1的F1分值为0.87。
7.3 混淆矩阵
决策树分类模型:
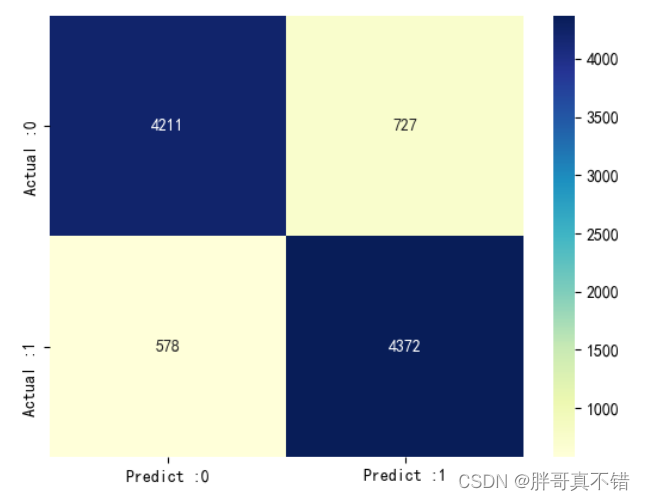
从上图可以看出,实际为0预测不为0的 有727个样本;实际为1预测不为1的 有578个样本。
随机森林分类模型:
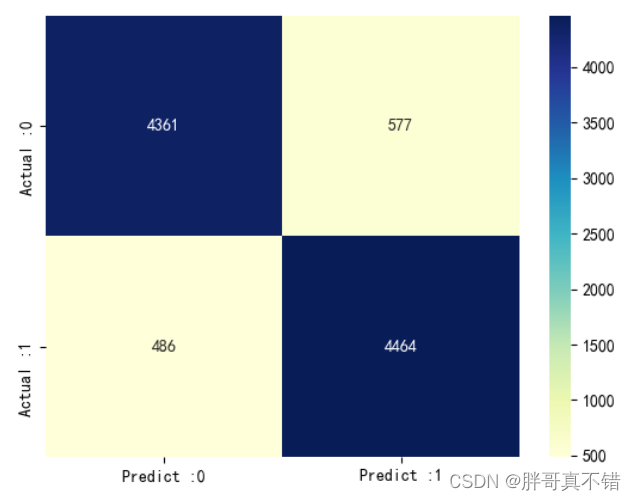
从上图可以看出,实际为0预测不为0的 有577个样本;实际为1预测不为1的 有486个样本。
KNN分类模型:
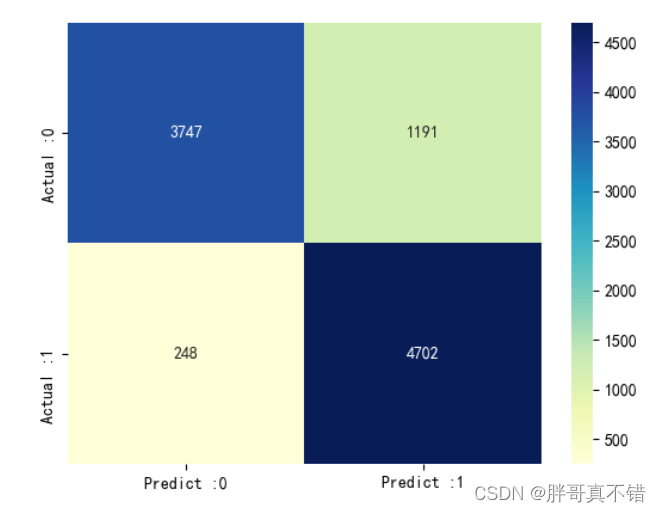
从上图可以看出,实际为0预测不为0的 有1191个样本;实际为1预测不为1的 有248个样本。
GBDT分类模型:

从上图可以看出,实际为0预测不为0的 有846个样本;实际为1预测不为1的 有497个样本。
7.4 ROC曲线
决策树分类模型:
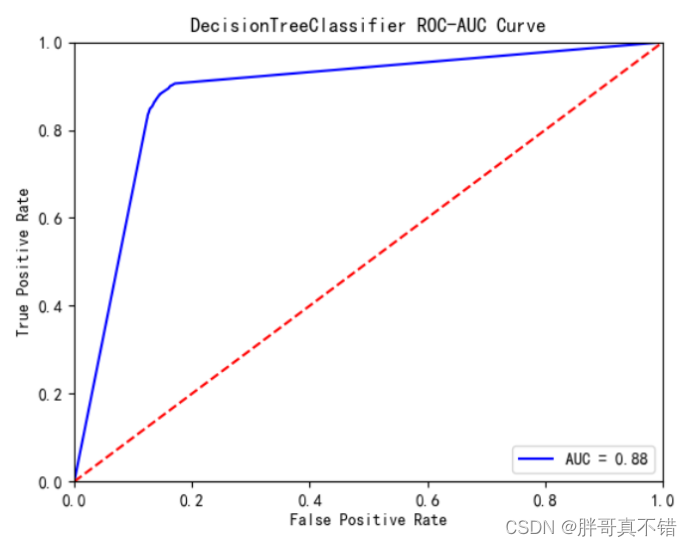
从上图可以看出,决策树分类模型的AUC值为0.88。
随机森林分类模型:
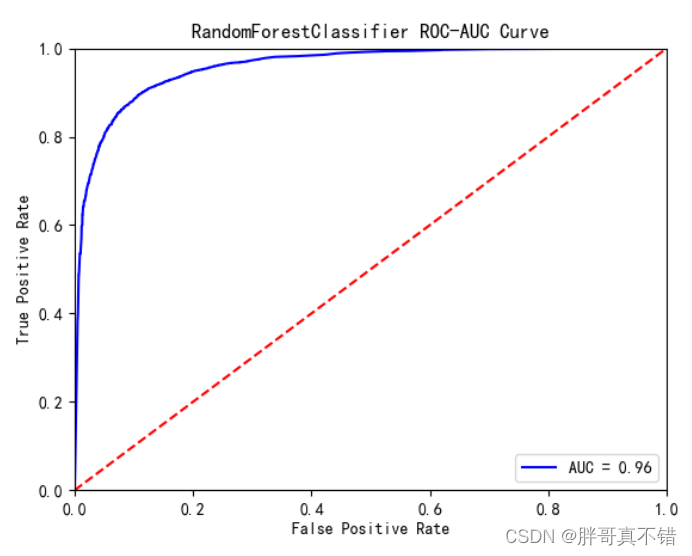
从上图可以看出,随机森林分类模型的AUC值为0.96。
KNN分类模型:
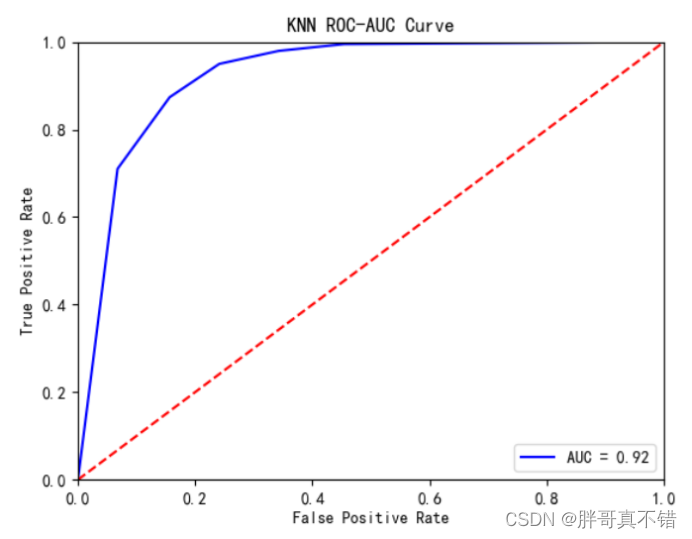
从上图可以看出,KNN分类模型的AUC值为0.92。
GBDT分类模型:
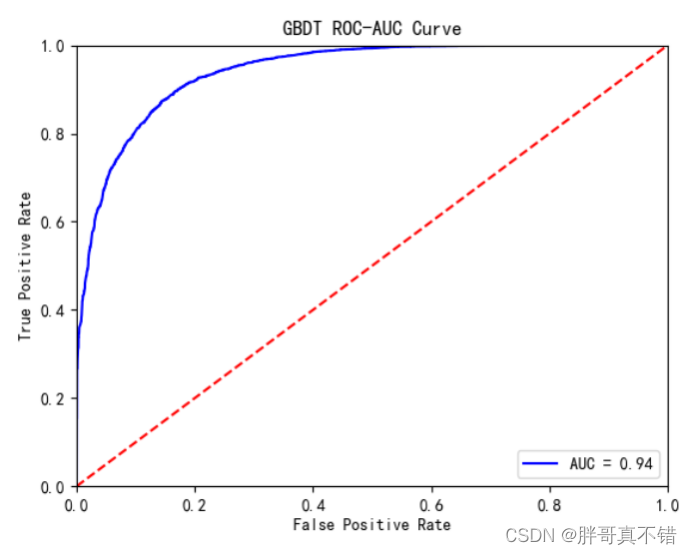
从上图可以看出,GBDT分类模型的AUC值为0.94。
8.结论与展望
综上所述,本文采用了决策树、、随机森林、KNN和GBDT算法来构建分类模型,最终证明了4种模型效果良好。此模型可用于日常产品的预测。
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 获取方式一:
# 项目实战合集导航:
https://docs.qq.com/sheet/DTVd0Y2NNQUlWcmd6?tab=BB08J2
# 获取方式二:
链接:https://pan.baidu.com/s/1t-Y8CL-9kKfsZKYz6xIroQ
提取码:9rwu















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











