









 本文深入解析Transformer模型,探讨其如何解决LSTM的串行问题,提升训练效率。通过详细步骤,展示Transformer在NLP任务中的优势,包括多头注意力机制、位置编码、残差连接等关键组件。
本文深入解析Transformer模型,探讨其如何解决LSTM的串行问题,提升训练效率。通过详细步骤,展示Transformer在NLP任务中的优势,包括多头注意力机制、位置编码、残差连接等关键组件。
目前NLP领域最火的是各种各样的BERT。而BERT的核心则是更早出生的transformer。
今天就来理一理transformers,下面是transformer的原论文。
Attention is All You Need:https://arxiv.org/abs/1706.03762
首先是为什么要有transformer,在这之前我们训练seq2seq任务大多使用的是LSTM。效果也还不错,但是LSTM有一个瓶颈,就是串行问题,串行大大制约了训练速度。于是更高效的可并行训练的transformer就诞生了。
很多刚开始接触transformer的同学会问,为什么transformer比LSTM好,大概最主要的因素就是训练快吧。
训练快的结果就是可以在更大量的数据集上训练,于是大力出奇迹。同样的数据在同样复杂度的LSTM模型上不知道要训练到猴年马月了。
接下来就让我们一步步拨开transformer的外衣🙌,详细的看一看transformer的思路及计算细节。
光讲思路,没有计算细节对于新手来说是不够的,至少我在一开始学习的时候是不够的,看完思路之后仍然云里雾里。
模型结构
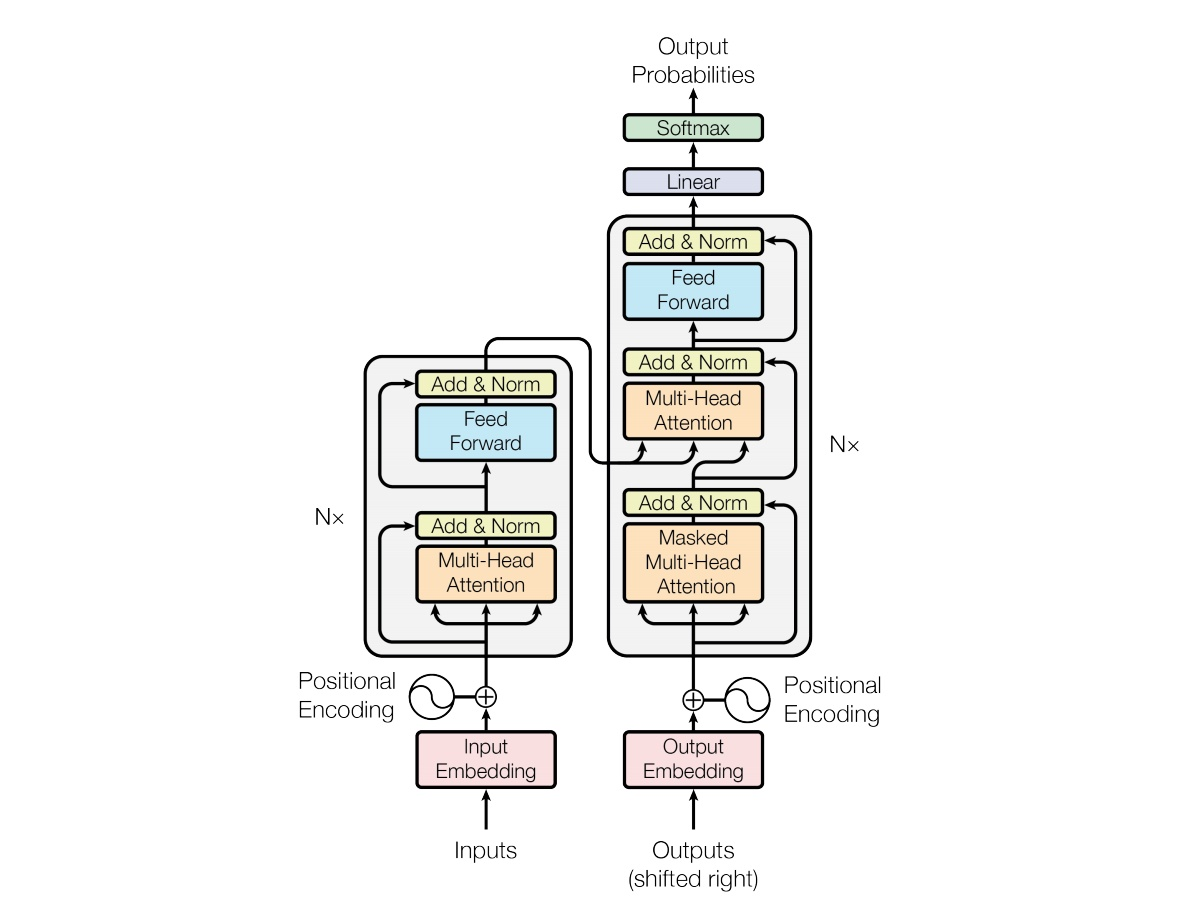
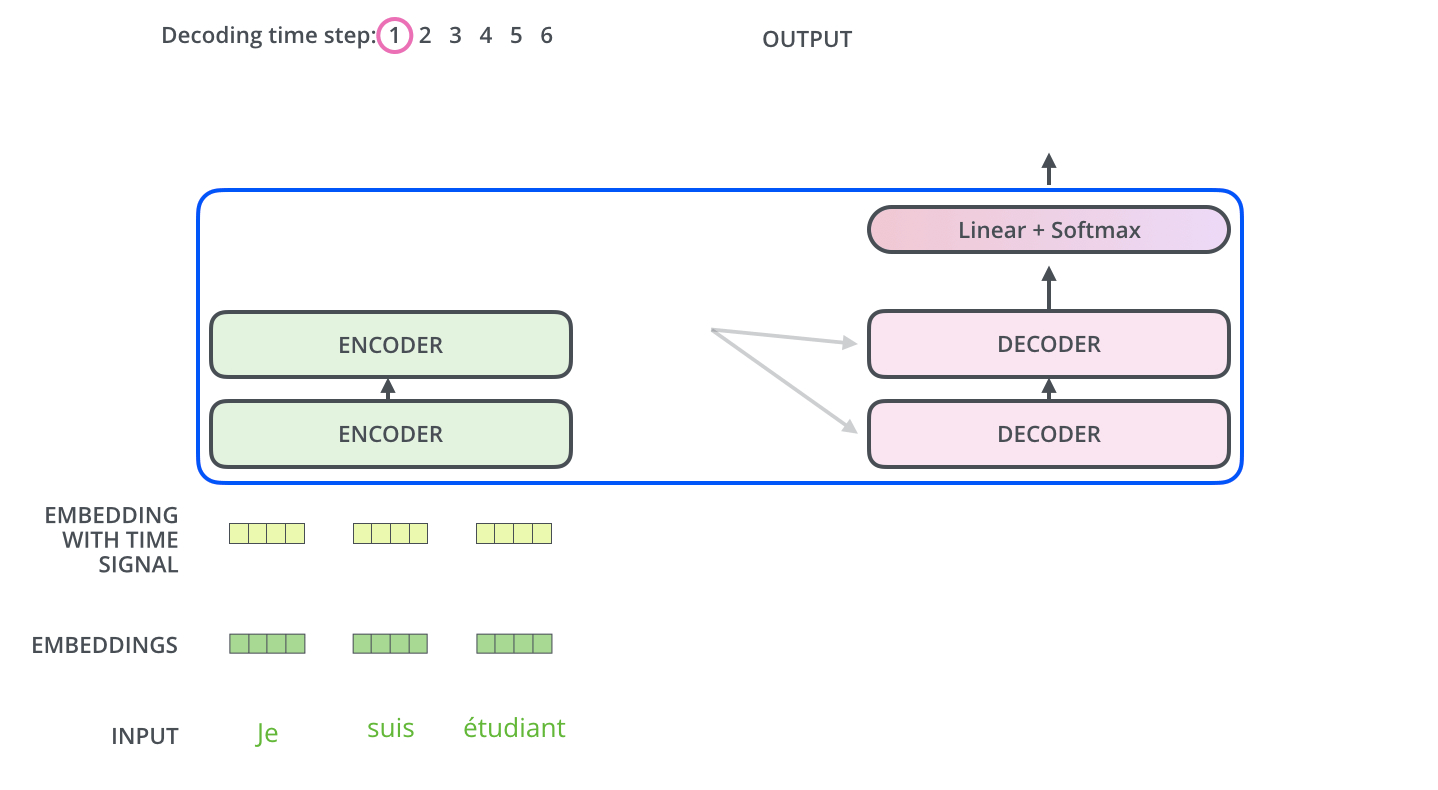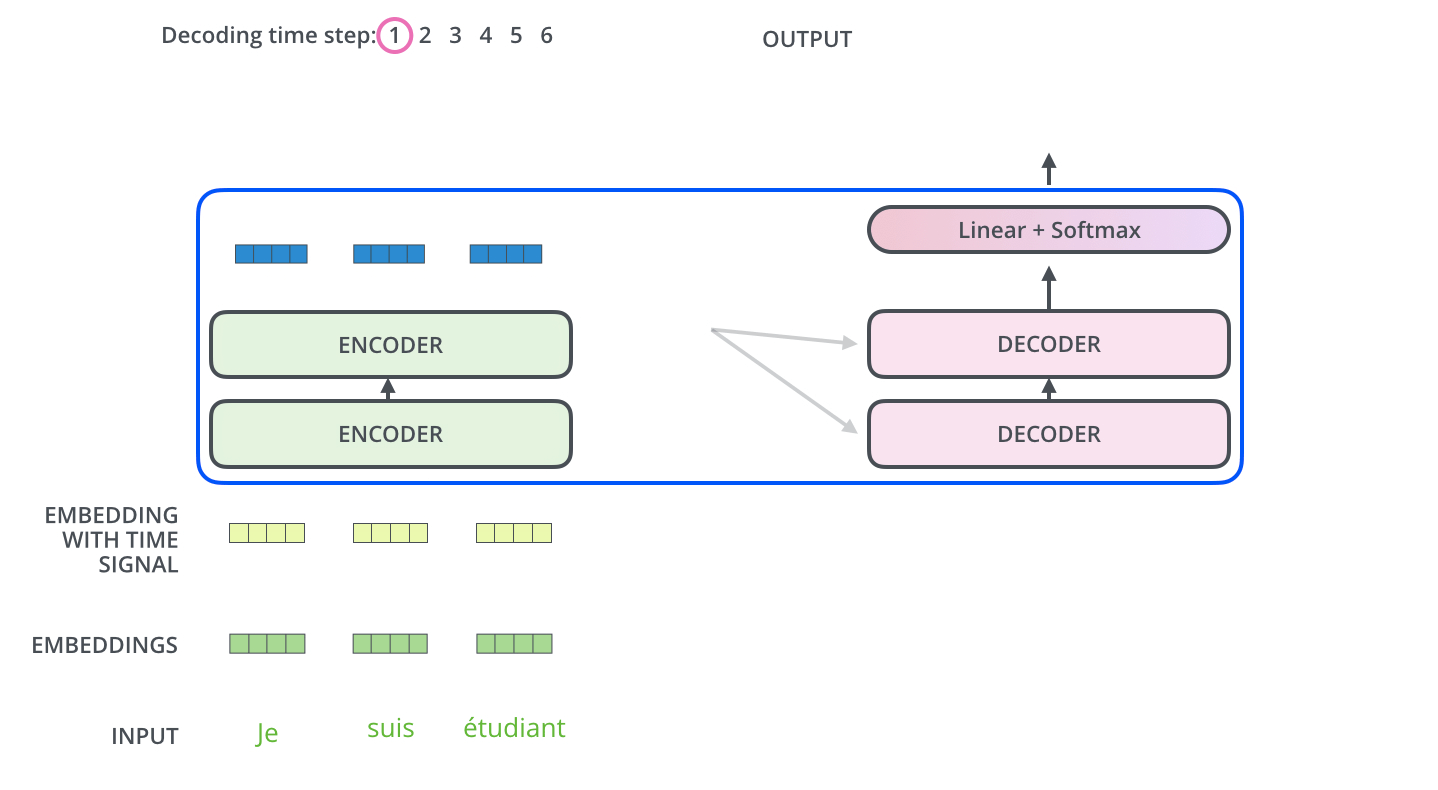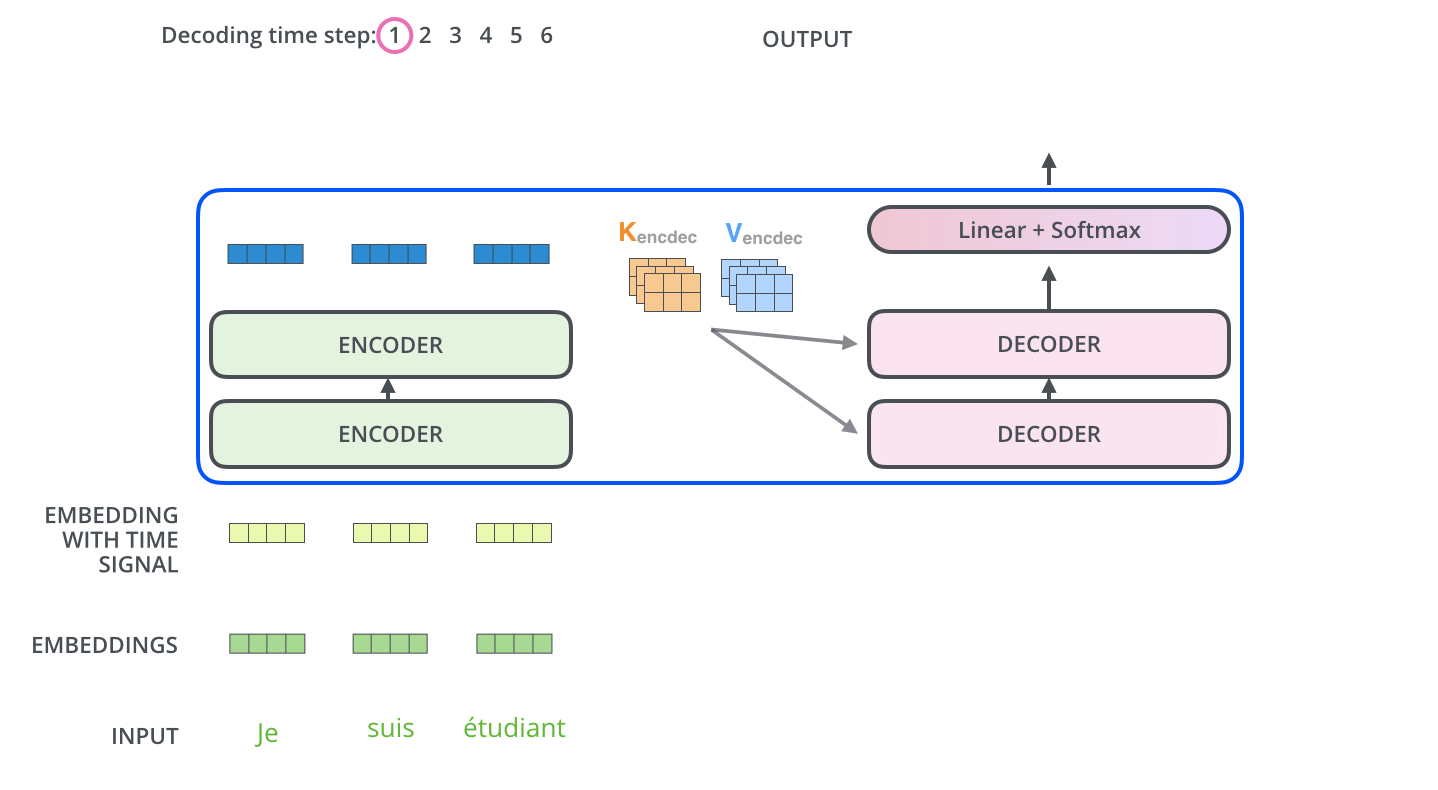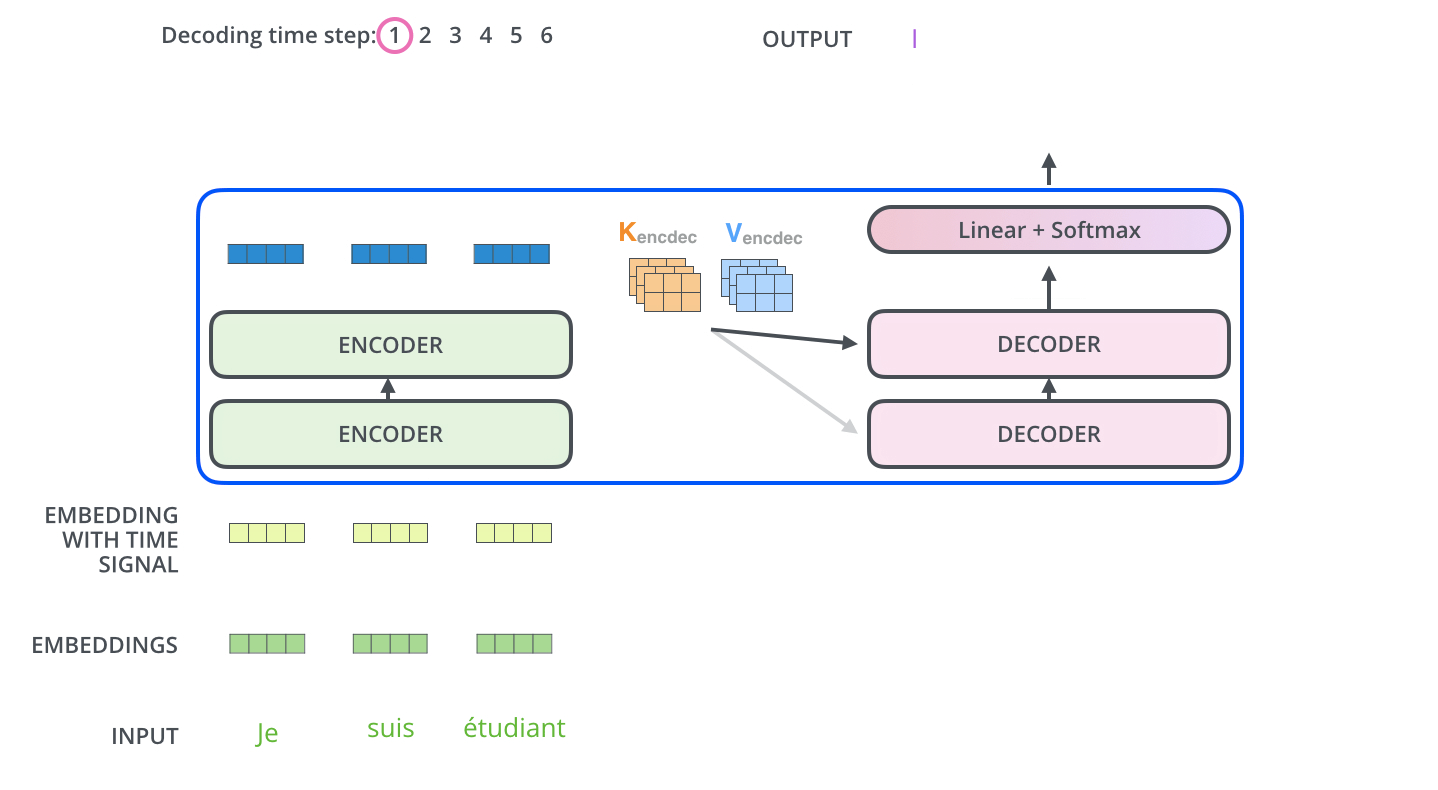
以上是论文中的原图,整个模型分为两大部分,左边为Encoder,右边为Decoder。
本文以上下文预测作文案例进行讲解,比如下面的两句话,我们尝试用第一句来预测第二句。
第一话全部送入Encoder,然后从Decoder输出第二句话。
<s> Bob wanted to play a video game . </s>
<s> He found the game he wanted online and ordered it . </s>Encoder
Encoder主要由6个Layer构成,然后这6个Layer就构成了一个encoder,多个相同的encoder就构成了一个Encoder,也就是图中最左边的Nx,意思就是这个Encoder可以根据需要自定义多少个,各个小的encoder相互之间是串行的,transformer论文中是6个。
Decoder中也主要是这几个Layer构成,下面就先介绍一下这6个Layer,然后再讲多个encoder是如果工作的。
Input Embedding
这一层大家应该是比较熟悉的,LSTM中也离不开这一步,即将所有的单词都映射到一个词向量,这里假设是256.
假设原始数据是
X =(batch_size * seq_len)=(64 * 20),即一个batch为64, 每句话有20个单词。
那么经过这一层之后得到的输出为
X_e = (batch_size * seq_len * emb_dim)= (64 * 20 * 256)
Positional Encoding
为什么会多一个position encoding呢?因为在transformer的架构中并没有像LSTM一样一个词一个词串行训练的步骤,因此就缺少了词的先后关系,而NLP任务中,词的先后关系是至关重要的,因此就有了这一层。
而这一步是有成熟方法的。
用不同频率的sine和cosine函数直接计算。为什么是它,看了下面的效果就会理解了。
该方法中给偶数位置和奇数位置分别定义了sin和cos函数。pos为句子中当前词的位置,本文中则是0 - 19.
d_{model} 就是前面embedding层的向量长度,即128
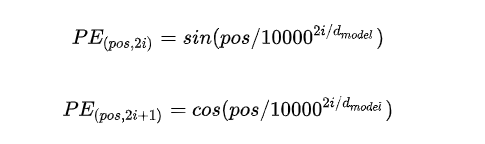
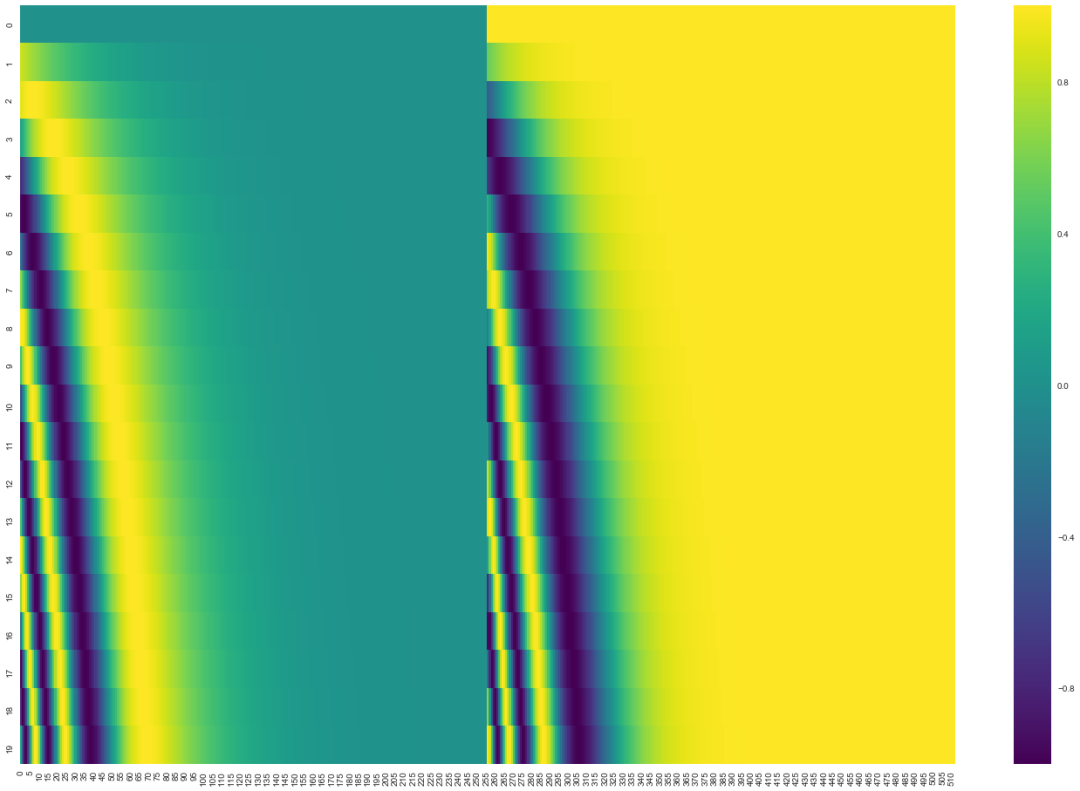
下图是position encoding结构的可视化图,可以看到从0 - 19是由一个渐近的变化,这里利用了sin,cos函数的周期性规律,即表示出了不同位置的差异及关系。
这一层的输出Tensor shape和上面embeding是一样的,
X_p = (batch_size * seq_len * emb_dim)= (64 * 20 * 256)
然后将embedding的输出和position encoding的输出相加就得到了下一步的输入。
X_e_p = (batch_size * seq_len * emb_dim)= (64 * 20 * 256)
会有同学问为什么是相加不是拼接,相加能有效果吗?
因为后序的计算会把拼接也变成相加:
假设接下来做一个线性变换,相拼也会变成相加,具体后序更新。
Multi-Head Attention
这一步是transformer的核心了,它的作用就是替代LSTM,对整句话提取全局的词与词之间的关系等信息,是怎样的关系信息呢,比如途中,机器学习到了“it”指的是“animal”,而不是其他的名词如“street”。

在encoder中这一层叫做multi-head attention,即有多个attention,那么就先来将一个attention是怎么样的,我可以叫它self-attention更准确,主要是对第一句话进行充分理解,是通过寻找每一个词与这句话中所有词的关系来进行理解。
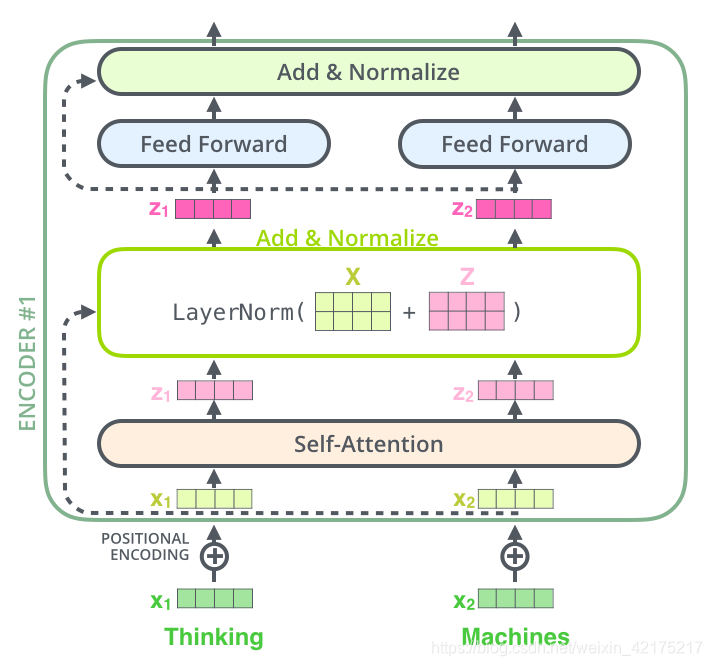
经过了前面embedding和position之后,我们拿到了一个词的综合Embedding,在下图中我们输入了Thinking、Machines两个词,然后得到了他们的Embedding向量 X1, X2
从第一个词开始寻找关系和所有词的关系,这里其实就是把当前词的向量与所有的向量依次点积就得到了与每个词的关系结果。由于我们还需要并行计算,所以把Embedding copy两份,这样就得到了图中的query 和 key 两个向量。

我们从第一个词开始,于是就计算q1 * k1, q1 *k2, 即得到了第一个词与第一个词和第二个词的关系分数,如下图。

既然得到了关系分数,即权重,而我们在计算权重时通常需要进行归一化,所以将上面得到的分数除以,再做softmax。图中案例embedding维度是64,所以是除以8。这一步主要是为了保证梯度的稳定性,避免由于词向量维度大小的变化对训练造成剧烈波动。

得到归一化之的权重后,如果我们再把这个权重乘以每个词本来的Embedding再求和,就得到了一个新的第一个词的词向量z1,该词向量不仅有第一个词自己的信息还包含了其他所有词相关的信息。
这就是图中Values的作用,Values也是原始Embedding的copy。

对所有Querys都进行一次这样的计算,就完成了一次self-attention。
得到一个全新的
Z = (batch_size * seq_len * emb_dim)= (64 * 20 * 256)

那么Multi-Head Attention又是怎么来的呢,为了避免单个self-attention提取的信息有限,所以一次性多个self-attention并行进行。既然要并行就需要给每一个head一套embedding,所以这里加入了一个线性变换,使得Q,K,V可以变得更大,然后再平均拆分一部分给每一个head,最后将每一个head的到的Z向量进行合并。

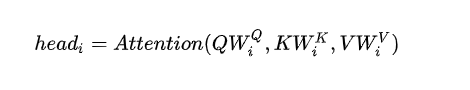
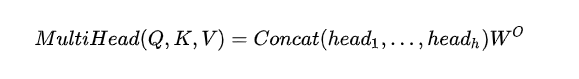
原文中是有8个head,假设W的维度是512
经过W之后的X_w =(batch_size * seq_len * all_head_dim)=(64 * 20 * 512)
那么 经过W之后的 Q, K, V = (batch_size * seq_len * num_head * head_dim)= (64 * 20 * 8 * 64)
而每一个head得到的 q, k, v (batch_size * seq_len * head_dim)= (64 * 20 * 64)
最后得到的 Z =(batch_size * seq_len * all_head_dim)=(64 * 20 * 512)
Add & Norm
这一层做一个简单的Residual network残差网络,将X_w与Z相加。残差网络在CNN中是应用很多的,如ResNet,Yolo,它是为了在深层网络中保证高效的梯度传递。
然后再增加一个LayerNorm归一化,即对每一个维度减去平均数,除以标准差。
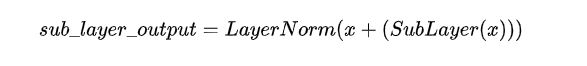
这一步并未改变向量大小,仍然是
Z_a =(batch_size * seq_len * all_head_dim)=(64 * 20 * 512)
Feed Forward
然后再进行一个简单的线性变换,同时使用relu作为激活函数。
FFN=max(0,xW1+b1)W2+b2
这一步也并未改变向量大小,仍然是
Z_f =(batch_size * seq_len * all_head_dim)=(64 * 20 * 512)
Add & Normal
最后再做一次前面的残差操作,将Z_a 和Z_f加在一起,然后再归一化
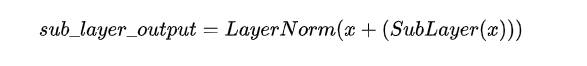
至此,Encoder层就走完了,整个步骤如下图。然后就可以进入Decoder层了。
Decoder
Masked Multi-Head Attention
decoder比 encoder最主要是多了这一层,这一层大致和Multi-head attention 是一样的。
区别在于decoder是做预测,假设一句话20个词,那就是依次预测y_0, y_1, y_2, ... , y_19,当预测y_2时,只能看到y_0, y_1,所以计算y_2的与各词的权重分数时,只能得到与y_0, y_1的分数。所以就需要把y_2及以后的位置mask起来。
那么我只输入y_0, y_1的值不就完了,之际预测的时候是这样的,但是训练的时候是知道左右y的,为了避免训练时作弊,所以需要mask起来,达到更真实的训练效果。
我们通过构建一个如下的mask矩阵来起到mask的效果,将看不到的部分权重置为零 .
([[[``1``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``],
``[``1``, ``1``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``],
``[``1``, ``1``, ``1``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``],
``[``1``, ``1``, ``1``, ``1``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``],
``[``1``, ``1``, ``1``, ``1``, ``1``, ``0``, ``0``, ``0``, ``0``, ``0``],
``[``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``0``, ``0``, ``0``, ``0``],
``[``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``0``, ``0``, ``0``],
``[``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``0``, ``0``],
``[``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``0``],
``[``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``]]])Masked Multi-Head Attention 之后再来一个残差和归一化,
这一步得到一个y_i = (batch_size * 1 * all_head_dim)= (64 * 1 * 512)
我们需要依据Encoder得到的信息来预测,然后就可以把这一步得到的信息与 Encoder进行attention了。
计算方式一样,将y_i 与 Z_i每一个计算权重,然后求和得到一个新的向量。
只是这一步中Querys就是y了,Keys和Values是encoder的输出。
这一步的输出形状未改变为 y_i = (batch_size * 1 * all_head_dim)= (64 * 1 * 512)
再经过一个和Encoder中一样的Feed Forward及Add & Norm
最后得到一个最终的y_i = (batch_size * 1 * all_head_dim)= (64 * 1 * 512)
Final Liear and Softmax Layer
上面一部的到的一个512维的向量,而我们实际是要预测一个词,因此再进行一次线性变换 及 softmax归一化。
softmax的输出就是词表中每一个词的概率。假设词表大小是20000,
那么最后的输出就是 out = (batch_size * 1 * vocab_size) = (64 * 1* 20000)

Loss Function
既然是预测词,那么transformer的loss function就和其他模型一样是Crossentropy交叉熵。
模型效果对比
文章开头既然提到了LSTM与transformer的比较。
下面就把我自己做的实验拿来对比一下。
后序更新,
欢迎留言讨论

















 3118
3118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









