






 本文探讨了世界模型在人工智能中的重要性,介绍了如何通过机器学习(如神经网络、自监督学习)构建模型,特别是深度强化学习在含风电电力系统调度中的应用。文章还详细解析了transformer、ConvNet、RNN和GAN等常见模型在网络架构中的角色,以及位置编码在处理序列数据中的作用。
本文探讨了世界模型在人工智能中的重要性,介绍了如何通过机器学习(如神经网络、自监督学习)构建模型,特别是深度强化学习在含风电电力系统调度中的应用。文章还详细解析了transformer、ConvNet、RNN和GAN等常见模型在网络架构中的角色,以及位置编码在处理序列数据中的作用。
世界模型:
是指人工智能系统对现实世界及其相互作用的理解,它包括对物理世界、社会世界和人脑的理解,世界模型使人工智能系统能够理解和应对显示世界中内的各种情况。
世界模型可以用各种方式来构建,一种方法是使用机器学习来训练模型,以预测输入数据的结果,另一种方法是使用专家知识来构架模型,例如由人类专家编写的规则。
以下是一些属于世界模型的算法模型:
神经网络:可以用于各种任务,包括自然语言处理、计算机视觉和机器人等。神经网络可以通过自监督学习来生成,根据未标记的数据来训练模型。
(----------------------------------------------- 自监督学习 ---------------------------------------------------------)
自监督学习:是一种机器学习范式,不需要人工标注的标签就可以训练模型,通过构造一些辅助任务,让模型自己学习数据中的统计关系,优势在于可以利用大量未标记的数据来训练模型,减少标注数据的成本,可以提高模型的泛化能力,不需要依赖特定的标签
有监督学习中,标签是人工标注的,表示数据的真实状态
自监督学习中,标签是模型在训练过程中自动生成的,或者就是输入数据的一部分,代表了数据的某种统计关系
文章:基于世界模型深度强化学习的含风电电力系统低碳经济调度
这个里面应该就是经验池1中有,拿
、
来训练模型,将
、
作为标签,训练好后,将强化学习模型输出的
、
作为输入,预测
、
。所以该世界模型是用来模拟环境的。
(---------------------------------------------------------------------------------------------------------------------------)
生成模型:是一种可以生成新数据的模型,例如文本、图像和视频等。生成模型可以用于各种任务,例如文本生成、图像生成和机器翻译等。
逻辑模型:是一种基于逻辑规则来工作的模型,逻辑模型可以用于各种任务,例如推理、决策和规划等。
世界模型的网络架构
没有统一标准,可以根据不同的任务和数据集进行设计
通常来说,世界模型的网络结构都具有以下特点:
1)使用多层神经网络来学习数据中的统计关系
2)使用卷积神经网络或循环神经网络来处理图像、文本和视频等多模态数据
3)使用生成模型来生成新的数据,以提高模型的泛化能力。
常见的世界模型网络架构
transformer:是一种用于自然语言处理的架构,可以有效捕捉文本中的长距离依赖关系,可以用于预测文本、翻译语言和生成文本等任务
ConvNet:一种用于图像处理的架构,可以有效提取图像中的局部特征,可以用于图像分类、乳香识别、图像生成等任务
RNN:一种用于处理序列数据的架构,它可以有效地捕捉序列数据中的时序关系。RNN 可以用于语言模型、机器翻译和游戏等任务。
GAN:一种生成对抗网络,它可以生成逼真的数据。GAN 可以用于生成图像、生成文本和生成视频等任务。
transformer
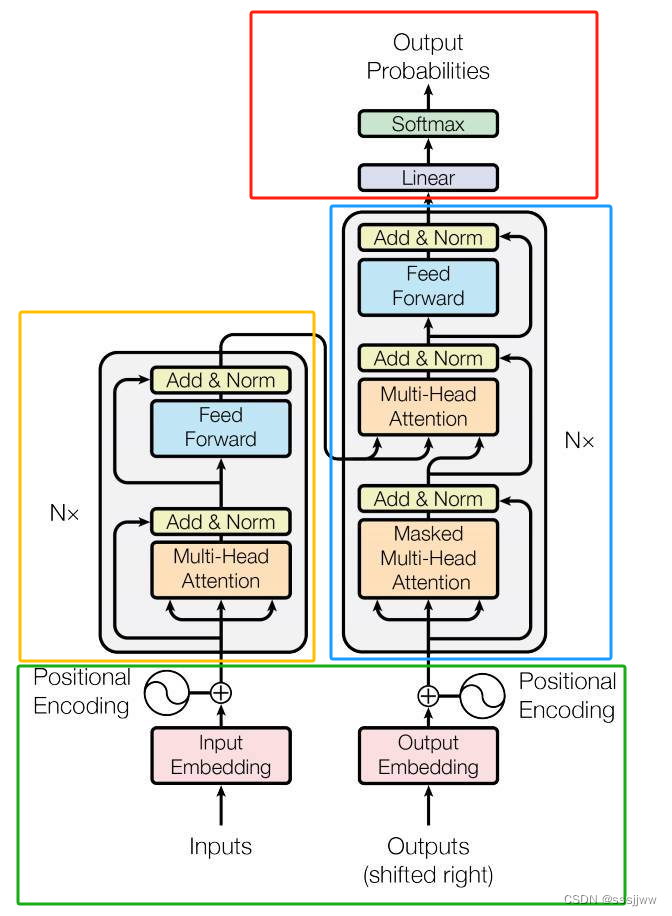
绿色框:input_输入
transformer的输入是一个序列数据,假设是“Tom chase Jerry”,inputs就是“Tom chase Jerry”分词后的词向量

进入input embeddingh后需要给每个word的词向量添加位置编码position encoding
添加位置编码的原因:词语出现在句子中的位置不同,代表的句意也会不同。
位置编码获取方式:使用正余弦位置编码,位置编码通过使用不同频率的正弦、余弦函数生成,然后与对应的位置的词向量相加(拼接和相加都是可行的,但是拼接的话会增加维度,两者效果差不多,但是效率不同),位置向量编码和字向量的维度是一致的。
pos:单词在句子中的绝对位置,:词向量的维度,i:词向量中的第几维
transformer的decoder的输入与encoder的输入处理方法步骤是一样的,一个接收source数据,一个接收target数据。例如:encoder接收英文Tom chase Jerry”,decoder接收中文“汤姆追逐杰瑞”。只是在有target数据时才会进行监督学习,进行预测的时候是不接收output embedding的。
黄色框:encoder
黄色框内部是由多个encoder堆叠而成的,灰色框部分就是一个encoder及其内部结构,一个encoder由multi-head attention、全连接神经网络feed forward network构成。
self-attention:
假设输入序列为“thinking machines”,x1、x2分别对应“thinking”和“machines”添加过位置编码之后的词向量,维度(2, 512),然后通过三个权值矩阵、
、
,维度均为(512, 64),转变为计算attention所需要的Query、keys、values向量,维度为(2,64)。
获得Q、K、V之后,计算attention
1) 对输入序列中每个单词之间的相关性得分,,点积法,得(2,2)的矩阵
2) 对于输入序列中每个单词之间的相关性得分进行归一化,,
是k的维度,当前例子为64
3) 经过softmax函数,将每个单词之间的得分向量转换为[0, 1]之间的概率分布,score成为一个值分布在[0, 1]之间的(2,2)维度的概率分布矩阵
4) 在第三步的基础上乘上对应的values值,点积,(2,2)*(2,64)=(2,64)
总结:
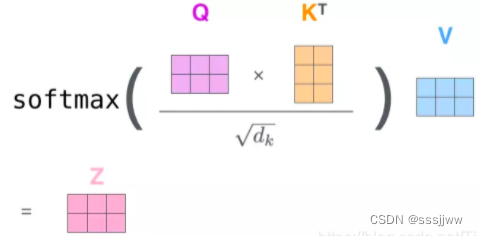
multi-head attention:
在self-attention的基础上,使用多组、
、
得到多组Q、K、V,然后每组分别计算得到一个Z矩阵,最后将得到的多个Z矩阵进行拼接,transformer里面使用了8组不同的
、
、
。
每个self-attention之后得到的Z矩阵,会直接到add&normalize中。
add:在Z的基础上加了一个残差块X,目的:防止在深度神经网络训练过程中发生退化问题
原理:如果神经网络的最佳层数为18,但是设计的时候不清楚多少层为最优解,所以设计了32层,但是实际上多的14层是多余的,想要达到18层的最优效果,就需要让多出来的14层进行恒等映射,即输入是x,输出为x,添加残差之后则是h(x)=F(x)+x,F(x)为残差,只需要让F(x)=0即可,神经网络通过训练变成0比变成x更容易。
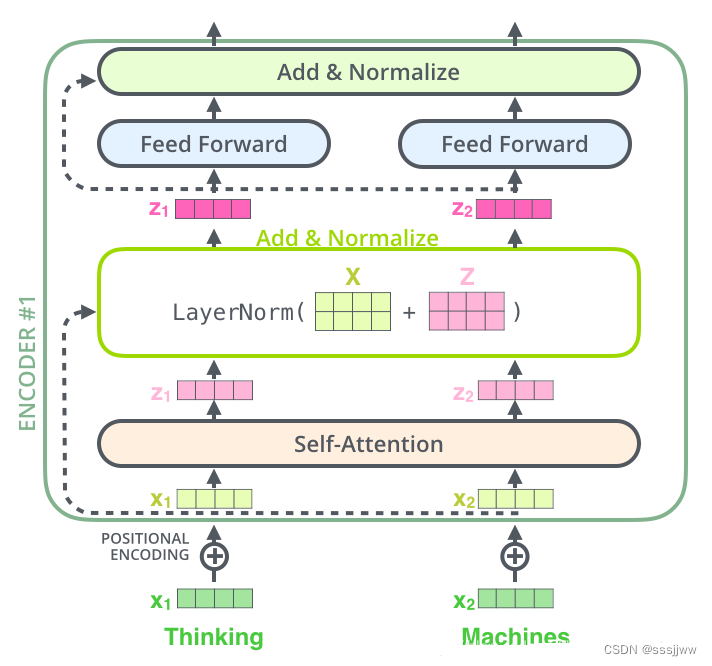
normalize:对数据进行归一化,目的:①加快训练速度;②提高训练稳定性
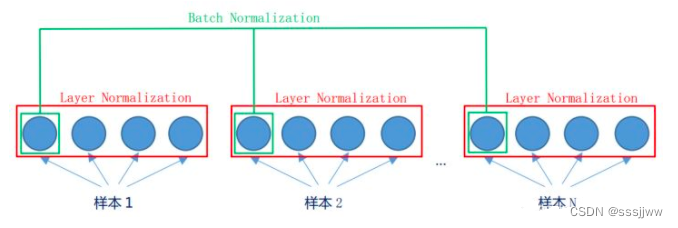
使用layer normalization(LN)而没有用batch normalization(BN)的原因:LN是同一个样本中不同神经元之间进行归一化;BN为同一个batch中不同样本的同一个位置的神经元之间的归一化。对于词向量,单独分析每一维是没有意义的。
全连接层:两层的神经网络,为了将输入的Z映射到更高维度的空间中
维度(64,1024)
维度(1024,64),FFN的输出结果维度为(2,64)
FFN的结果经过add&normalize,输入下一个encoder中,当所有encode经过之后,输入到decoder中。
蓝色框:decoder
decoder block也由多个decoder堆叠二测会给你,灰色部分为一个decoder的内部结构,一个decoder是由masked multi-head attention、multi-head attention以及全连接神经网络FNN构成。
decoder的输入:①训练时的输入(target数据,上文提到的中文“汤姆追逐杰瑞”);②预测时的输入(初始:起始符,之后为上一时刻transformer的输出)
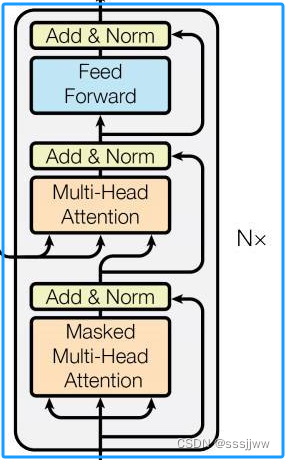
masked multi-head attention
与multi-head attention的计算原理一样,只是多了一个mask码,即掩码,对某些值进行掩盖,使其在参数更新时不产生效果,transformer中有两种mask,一种是padding mask;另一种是sequence mask。
padding mask:对输入序列进行对齐,在较短的序列后面填充0,如果序列太长,截取左边的内容,多余的部分舍弃。Multi-Head Attention中只有padding mask
sequence mask:在t时刻,解码输出应该值依赖于t时刻之前的输出,与t时刻之后的输出无关,所以需要将t时刻之后的信息隐藏起来,训练的时候,target是完整输入的,所以训练时需要改操作;预测的时候只能得到前一时刻的输出,所以不需要。
multi-head attention
encoder中的multi-head attention是基于self-attention的,而decoder中的multi-head attention只基于attention,输入①masked multi-head attention的输出Q;②encoder的输出K&V
红色框:输出
经过线性变化、softmax得到输出的概率分布,输出概率最大的对应的单词作为预测输出。
transformer的优缺点
优:
1、长距离依赖捕捉能力:通过self-attention能够有效地捕捉序列数据带着狗内的长距离依赖关系
2、并行处理能力:相较于RNN、LSTM等,可以并行处理数据,提高计算效率
3、强大的表征能力
缺:
1、计算和内存需求大
2、需要大量的训练样本,小样本数据集上无法发挥最佳性能
3、self-attention的局限性:可能无法很好地处理某些类型的结构化数据或需要特定位置信息的任务。

















 9843
9843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









