







Research Topic
Learning goal-directed behavior in environments with sparse feedback is a major challenge for reinforcement learning algorithms.
这里有两个名词需要注意:goal-directed behavior, sparse feedback
这篇文章提出了一种hierarchical-DQN (h-DQN), a framework to integrate hierarchical value functions, operating at different temporal scales, with intrinsically motivated deep reinforcement learning.
The model takes decisions over two levels of hierarchy:
- the top level module (meta-controller)
takes in the state and picks a new goal - the lower-level module (controller)
uses both the state and the chosen goal to select actions either until the goal is reached or the episode is terminated.
In their work, they propose a scheme for temporal abstraction that involves simultaneously learning options and a control policy to compose options in a deep reinforcement learning setting.
这里有必要对intrinsic motivation和extrinsic motivation进行解释一下,这其实都是心理学名词:
- intrinsic motivation
使用内部评价体系的人,对别人的评价不大在乎,他们做事情的动力,是来自于自己内心, 内在动机提供了一个促进学习和发展的自然力量,它在没有外在奖赏和压力的情况下,可以激发行为。 - extrinsic motivation
使用外部评价体系的人,对别人的评价特别在乎,甚至会内化别人对自己的评价,认为自己就是这样的。这样的人他们在做事情时,首先考虑的,也是别人怎么看、怎么认为。他们做事情的动力,常是为了博取别人的认可、金钱等
现在的强化学习对agent的研究基本都集中在外部动机上,一般认为外部强化是激发外部动机的必要条件,在强化条件下个体会产生对下一步强化的期待,从而以获得外部强化作为个体行为的目标。
Model
agents
现在的exploration method(e.g.
ϵ
−
g
r
e
e
d
y
\epsilon-greedy
ϵ−greedy)只对local exploration有用, 但是fail to provide provide impetus for the agent to explore different areas of the state space.
因此,为了解决这个问题,引入了一个重要的概念——goals
Goals provide intrinsic motivation for the agent. The agent focuses on setting and achieving sequences of goals in order to maximize cumulative extrinsic reward.
use temporal abstraction of options to define policy π g \pi_{g} πg for each goal g g g
其实本文的目标就是有两个:
- learning option policy
- learning the optimal sequence of goals to follow
Temporal Abstraction
as below:

critic的作用:
The internal critic is responsible for evaluating whether a goal has been reached and providing an appropriate reward
r
t
(
g
)
r_{t}(g)
rt(g) to the controller.
The intrinsic reward functions are dynamic and temporally dependent on the sequential history of goals.
Deep Reinforcement Learning with Temporal Abstraction
这篇文章使用了deep Q-Learning framework to learn policies for both the controller and the meta-controller.
- the controller estimates the following Q-value function:
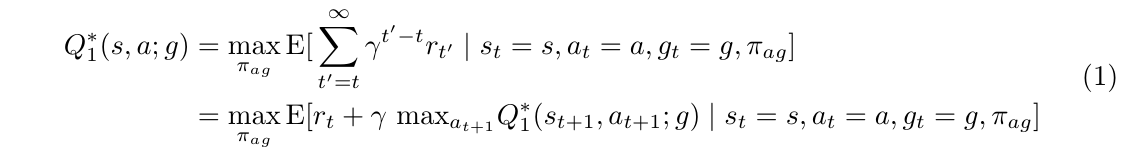
- the meta-controller estimates the following Q-value function:
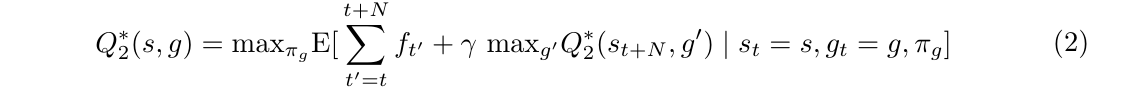
It is important to note that the transitions ( s t , g t , f t , s t + N ) (s_{t}, g_{t}, f_{t}, s_{t+N}) (st,gt,ft,st+N) generate by Q 2 Q_{2} Q2 run at a slower time-scale than the transitions ( s t , a t , g t , r t , s t + 1 ) (s_{t}, a_{t}, g_{t}, r_{t}, s_{t+1}) (st,at,gt,rt,st+1) generate by Q 1 Q_{1} Q1
Learning Algorithm
Parameters of h-DQN are learned using stochastic gradient descent at different time-scales.


Experiments
ATARI game with delayed rewards
Model Architecture

The internal critic is defined in the space of
<
e
n
t
i
t
y
1
,
r
e
l
a
t
i
o
n
,
e
n
t
i
t
y
2
>
<entity1, relation, entity2>
<entity1,relation,entity2> , where relation is a function over configurations of the entities.
Training Procedure
- First Phase
set the exploration parameter ϵ 2 \epsilon_{2} ϵ2 of the meta-controller to 1 and train the controller on actions. This effectively leads to pre-training the controller so that it can learn to solve a subset of the goals. - Second Phase
jointly train the controller and meta-controller















 2318
2318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









