回归是统计学中最有力的工具之一。机器学习监督学习算法分为分类算法和回归算法两 种,其实就是根据类别标签分布类型为离散型、连续性而定义的。回归算法用于连续型分布 预测,针对的是数值型的样本,使用回归,可以在给定输入的时候预测出一个数值,这是对 分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签。 回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示, 这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因 变量和自变量之间是线性关系,则称为多元线性回归分析。
多元线性回归
假定预测值与样本特征间的函数关系是线性的,回归分析的任务,就在于依据样本 X 和 Y 的观察值。去预计函数 h,寻求变量之间近似的函数关系。定义:
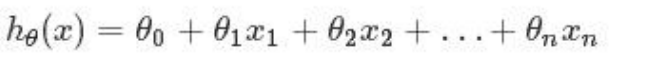
当中,n=特征数目; xj=每一个训练样本第 j 个特征的值,能够觉得是特征向量中的第 j 个值。 为了方便。记 x0=1。则多变量线性回归能够记为:
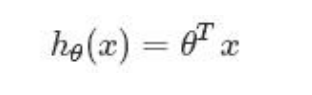
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import SGDRegressor
from sklearn.linear_model import Ridge
plt.rcParams['font.sans-serif']='SimHei'
plt.rcParams['axes.unicode_minus']=False
def show_res(</








 本文详细介绍了如何利用线性回归模型进行房价预测,并通过绘制散点图和折线图来直观展示预测结果与实际数据的关系。首先,我们收集并预处理了房屋特征与价格的数据集,接着构建了线性回归模型进行训练。然后,我们绘制散点图,用实线表示实际房价,虚线表示预测房价,展示了模型的预测能力。同时,折线图揭示了房价随特征变化的趋势,帮助理解模型的预测效果。
本文详细介绍了如何利用线性回归模型进行房价预测,并通过绘制散点图和折线图来直观展示预测结果与实际数据的关系。首先,我们收集并预处理了房屋特征与价格的数据集,接着构建了线性回归模型进行训练。然后,我们绘制散点图,用实线表示实际房价,虚线表示预测房价,展示了模型的预测能力。同时,折线图揭示了房价随特征变化的趋势,帮助理解模型的预测效果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4227
4227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









