






基于搜索的路径规划
Configuration Space & Workspace构型空间和工作空间
Configuration space中的障碍物由workspace中障碍物膨胀得到,膨胀的大小是机器人的体积范围;在configuration space中,机器人可以被表示为一个点。
Graph and Search Methods
Graph
- 有向图
- 无向图
- 带权重图
- 无权重图
Search-based Method

- 搜索图中节点的过程中,生成一个搜索树
- 在搜索树中从某一点回溯,能获得起始点到这一点的路径
总体框架:
- 维护一个容器,用于存储所有需要被访问的节点
- 使用初始状态 X S X_S XS初始化容器
- 在循环中:
- 根据预先定义的规则弹出节点(即当前访问的节点)
- 扩展节点(获得当前节点的所有相邻节点)
- 将邻居节点推回容器中
- 结束循环
何时结束循环?
当容器空时
图有环怎么办?
规定当一个节点被弹出后,它之后不会再被加入到容器中
如何弹出节点,从而尽快到达目标点?
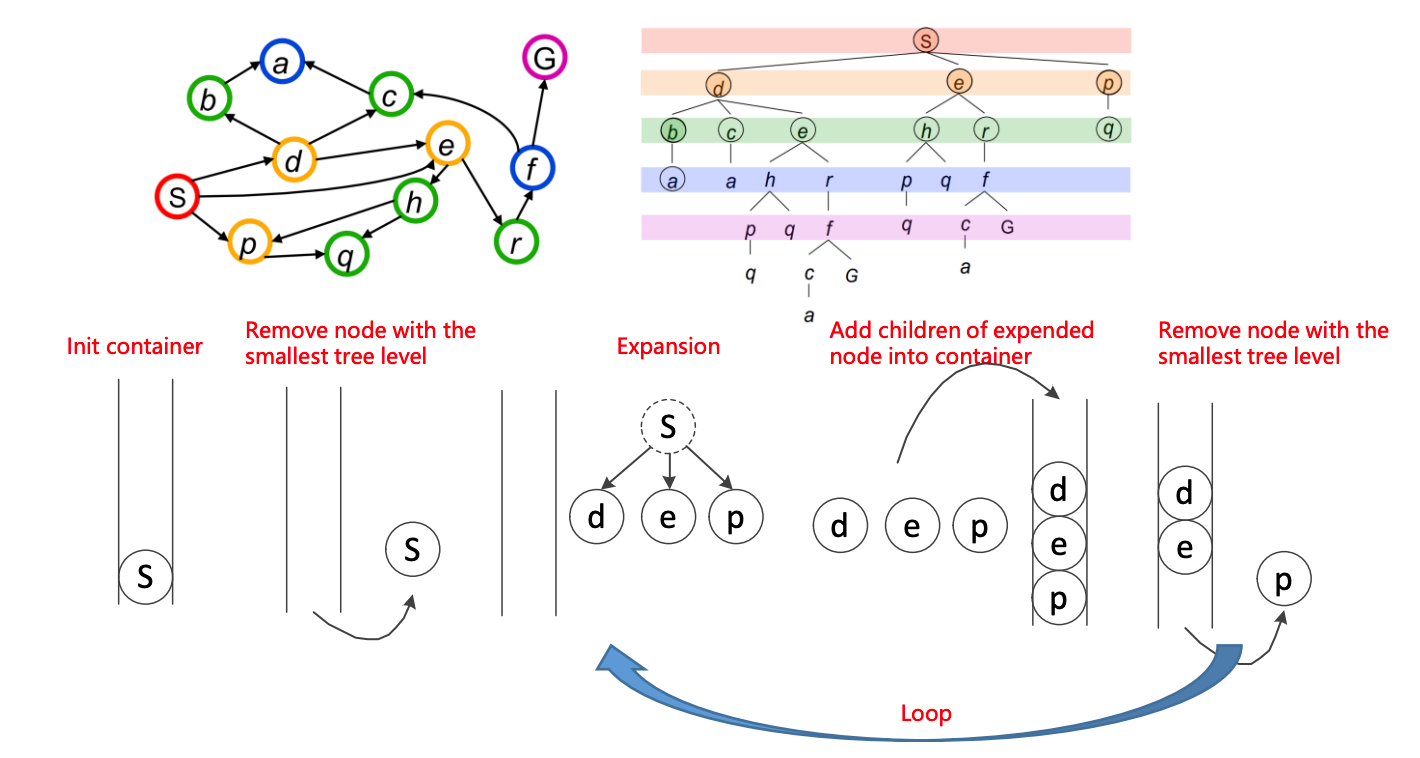
广度优先(队列)
图搜索算法的基础
每次弹出容器中最浅的节点(先入先出)
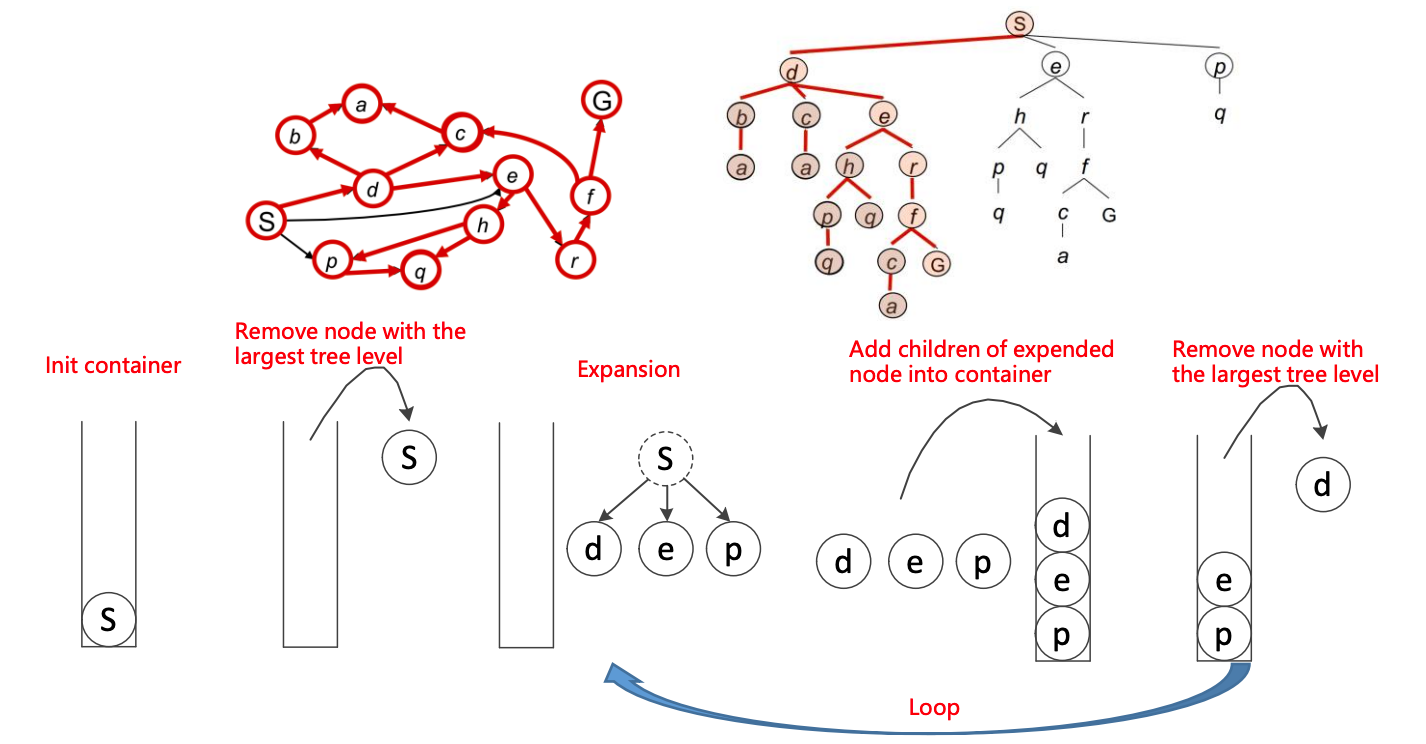
深度优先(栈)
每次弹出容器中最深的节点(先入后出)
Heuristic search 启发式搜索算法
贪心算法
根据某种规则,每次选择最优的节点弹出。如与终点的距离最短
Dijkstra
每次访问的节点的累计代价 g ( n ) g(n) g(n)最小;确保每个已经被访问的节点有从起点出发路径的最小代价
priority queue 优先队列:会对队列中的元素自动进行排列
算法:
- 用一个优先队列来存储所有需要被访问的节点
- 以起点点 X S X_S XS来初始化优先队列
- 令 g ( X S ) ← 0 , g ( n ) ← ∞ g(X_S)\leftarrow 0,g(n)\leftarrow \infin g(XS)←0,g(n)←∞, n n n为其他节点
- LOOP:
- IF 队列空,RETURN FALSE; BREAK;
- 从优先队列中移除有最小代价 g ( n ) g(n) g(n)的节点 n n n
- 标记节点 n n n已经被访问
- IF 节点 n n n是目标点,RETURN TRUE; BREAK;
- FOR 所有未被访问的
n
n
n的相邻节点
m
m
m:
- IF g ( m ) = ∞ g(m)=\infin g(m)=∞, g ( m ) ← g ( n ) + C n m g(m)\leftarrow g(n)+C_{nm} g(m)←g(n)+Cnm,将节点 m m m推入队列
- IF g ( m ) > g ( n ) + C n m g(m)>g(n)+C_{nm} g(m)>g(n)+Cnm, g ( m ) ← g ( n ) + C n m g(m)\leftarrow g(n)+C_{nm} g(m)←g(n)+Cnm
- END FOR
- END LOOP
Dijkstra的缺点:盲目地向所有方向搜索
A*
Dijkstra + 启发式算法
代价函数变为 f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n),其中 h ( n ) h(n) h(n)为从当前节点到目标点的估计的最小代价
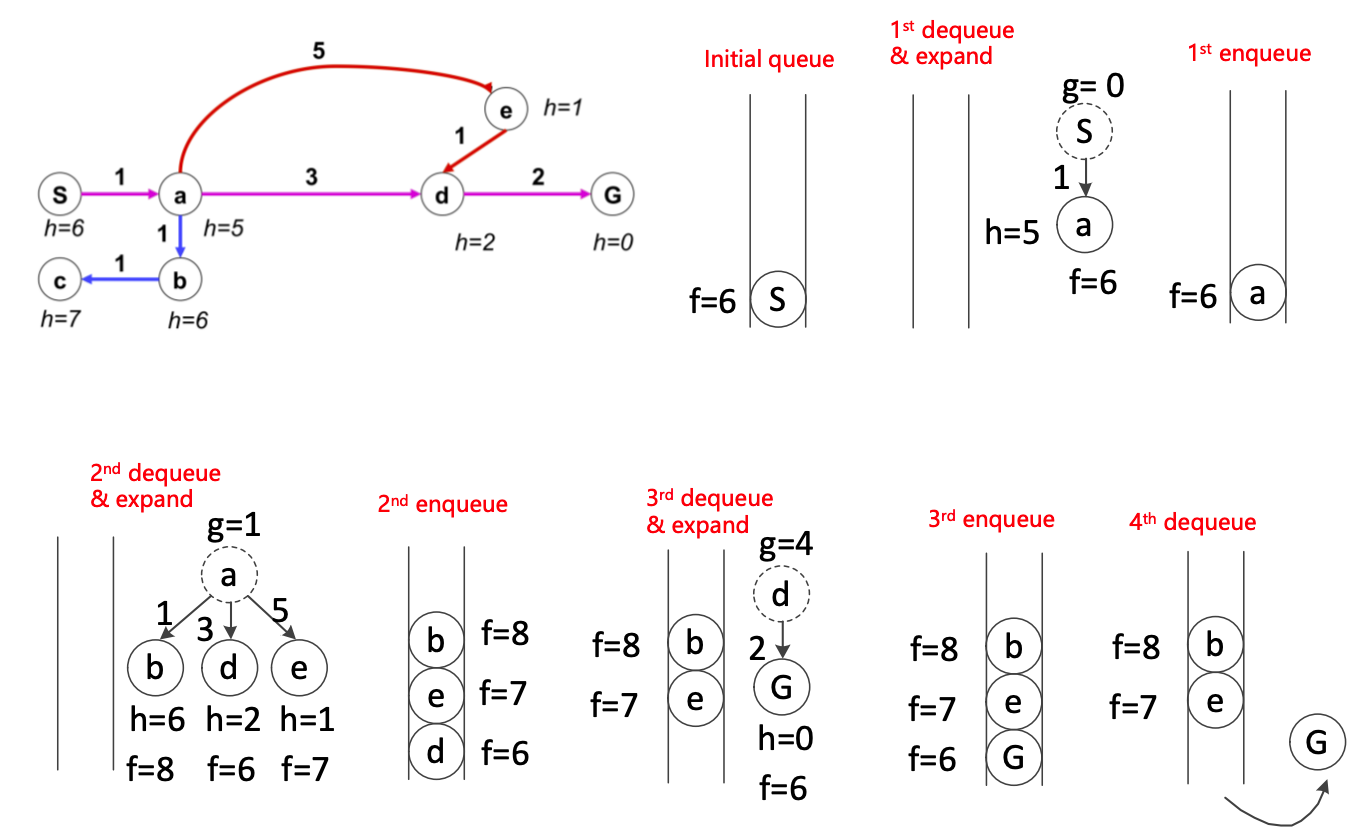
算法:
- 用一个优先队列来存储所有需要被访问的节点
- 以起点点 X S X_S XS来初始化优先队列
- 令 g ( X S ) ← 0 , g ( n ) ← ∞ g(X_S)\leftarrow 0,g(n)\leftarrow \infin g(XS)←0,g(n)←∞, n n n为其他节点
- LOOP:
- IF 队列空,RETURN FALSE; BREAK;
- 从优先队列中移除有最小代价$ f(n)=h(n)+g(n) 的节点 的节点 的节点n$
- 标记节点 n n n已经被访问
- IF 节点 n n n是目标点,RETURN TRUE; BREAK;
- FOR 所有未被访问(不在close set)的
n
n
n的相邻节点
m
m
m:
- IF g ( m ) = ∞ g(m)=\infin g(m)=∞, g ( m ) ← g ( n ) + C n m g(m)\leftarrow g(n)+C_{nm} g(m)←g(n)+Cnm,将节点 m m m推入队列(open set)
- IF g ( m ) > g ( n ) + C n m g(m)>g(n)+C_{nm} g(m)>g(n)+Cnm, g ( m ) ← g ( n ) + C n m g(m)\leftarrow g(n)+C_{nm} g(m)←g(n)+Cnm
- END FOR
- END LOOP
A*算法的最优性条件
估计出来的最短距离
h
(
n
)
h(n)
h(n)必须不大于真实的最短距离
h
∗
(
n
)
h^*(n)
h∗(n):
h
(
n
)
≤
h
∗
(
n
)
h(n)\leq h^*(n)
h(n)≤h∗(n)
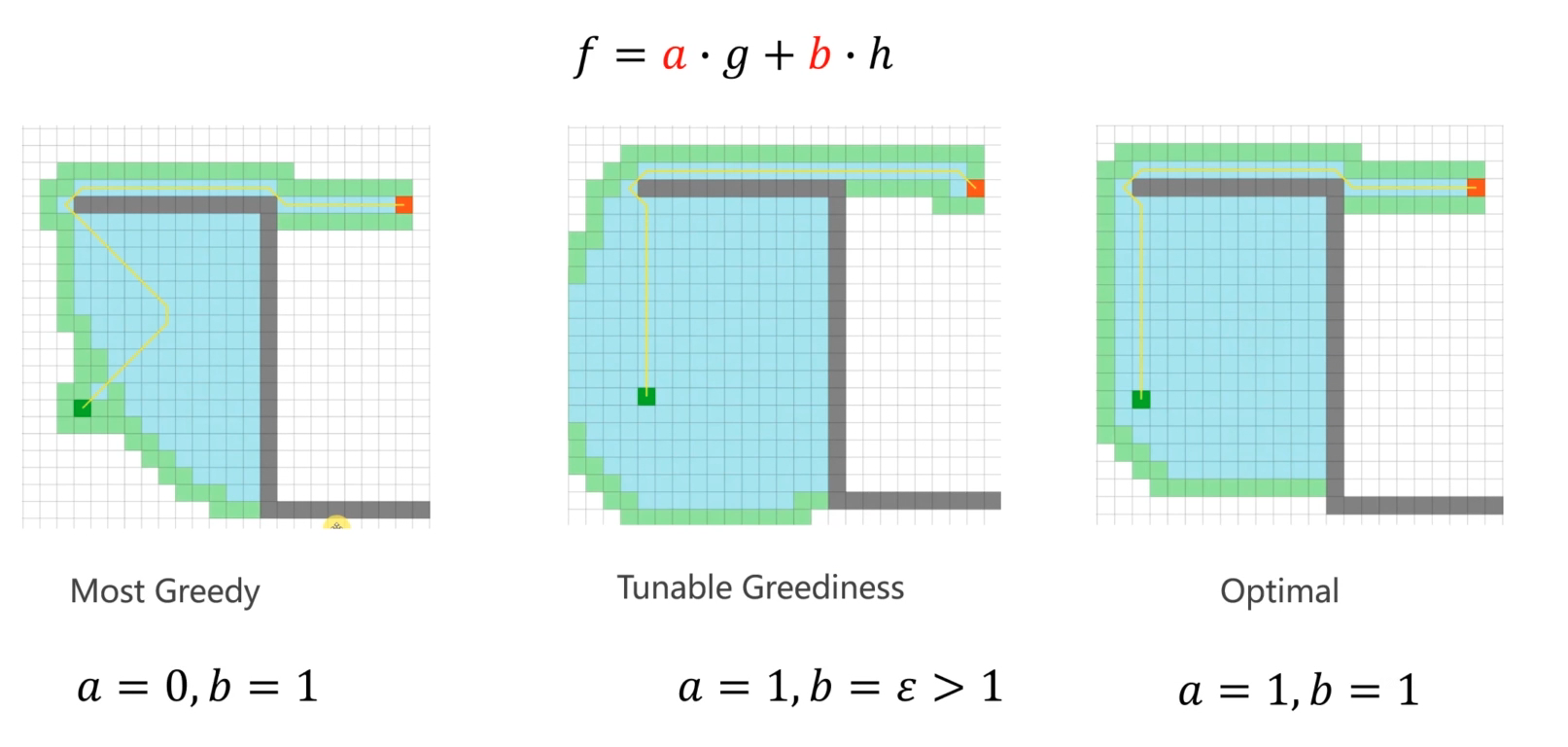
Weighted A*
f ( n ) = g ( n ) + ε h ( n ) f(n)=g(n)+\varepsilon h(n) f(n)=g(n)+εh(n)
获得的路径结果是次优的,但是加快了算法的速度。
栅格到图的转化
- 4邻接
- 8邻接
改进
A*会存在代价相同的许多对称路径,降低了程序的效率
-
Diagonal Heuristic 对角启发式算法

-
Tie breaker:对于 f ( n ) f(n) f(n)值相等的节点,再进行排序:重新计算 h ( n ) h(n) h(n)值

Jump Point Search
Look Ahead Rule

相比于A*算法搜索所有邻点加入Open list,JPS利用了parent node的信息,不去搜索inferior neighbors。inferior neighbors是由parent node出发前往,不经过当前节点的路径不比经当前节点路径更长的节点。因此:当先前的方向是直线时,倾向于继续沿这个直线行走,跳过其他点;当先前方向是对角时,倾向于向前方对角以及左前、右前方行走。

forced neighbor:当出现障碍物时,某些inferior neighbors经当前节点前往距离更短,因而称为forced neighbor
Jumping Rule
先往直线方向(垂直/水平)走,如果找不到jump point则往对角方向走。
标记为jump point的点:
- Forced neighbors
- 含有forced neighbor的节点
- 上述节点的parent node


算法

与A*相比,搜索的邻节点不同。
缺点:
- 只适用于不带权重的栅格地图
















 8083
8083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











