







这是苏神的论文,从BERT-flow到BERT-whitening,越来越接近文本的本质,处理方法也越来越简单了。其实昨天已经看完这个论文了,但是在看苏神的博客时发现这篇论文竟然还有一点小插曲:一篇使用了同样白化方法来优化预训练表征的论文发表在了EMNLP上,然后苏神把这件事的来龙去脉,双方交流过程写在了他的科学空间里,然后我当然就很感兴趣啦,所以就没来的及写阅读笔记。今天把两篇论文都看了,一起补在这里。
Title: Whitening Sentence Representations for Better Semantics and Faster Retrieval
From: arXiv
Link: https://arxiv.org/abs/2103.15316
Code: https://github.com/bojone/BERT-whitening

核心思想:
-
通过whitening来缓解BERT句子表征中的各向异性的问题,达到和BERT-flow差不多的结果。
-
whitening还可以降低表征的维度,减小storage cost.
模型
flow模型不是解决问题的关键部分,只需要一个线性变化就可以达到相近的效果。
因为从余弦相似度的公式来看,等号只有在“标准正交基”下才是成立的,而BERT生成句向量很可能不满这个条件,由于基底的不同,导致向量的坐标也不同,通过上述公式计算出的余弦值也就不能体现句子本身的语义相似度了。
所以我们希望把现有的句向量投影到一个基于标准正交基的空间下,重新计算句向量的坐标。我们知道标准正态分布的均值为0,协方差矩阵为单位阵,那么我们也对句向量做这样一个变换。具体来说,也把句向量的平均值变换为0,协方差矩阵变换为单位矩阵。这个过程也就是传统数据挖掘中的白化操作(Whitening)。
具体的过程推到看苏神的原文吧。
实验
也是在7个STS的数据集上做的实验。
- 主实验


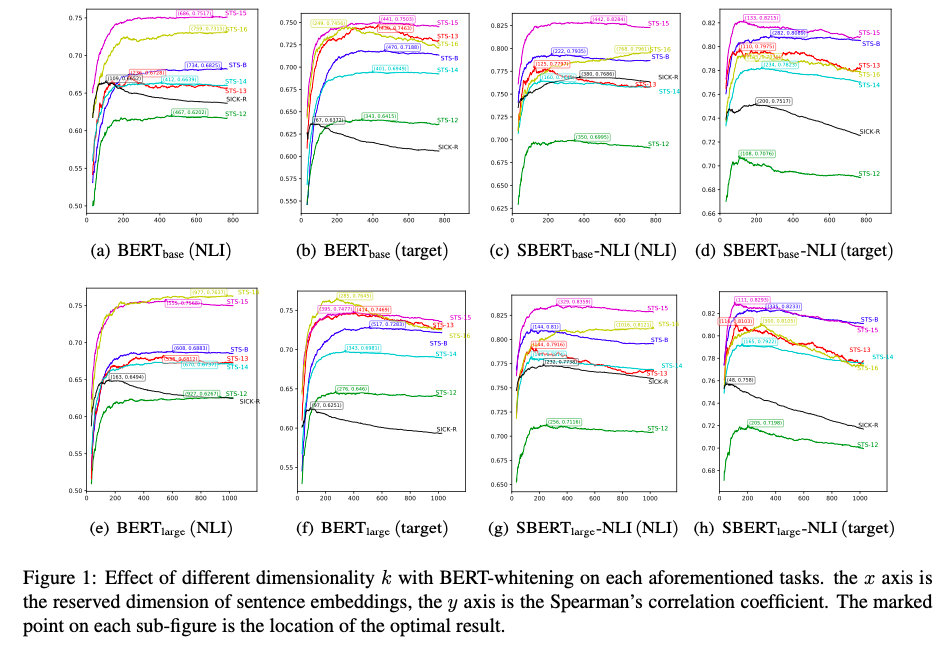
- 降维后的维度K对效果的影响
同时呢,我也找到了这篇存在一些争议的论文,发表于EMNLP2021:
WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach
这篇论文在BERT、RoBERT、DistilBERT和LaBSE四个预训练模型上做了实验,主要的贡献点是:
- [CLS]没有平均有效。(其实这一点已经在之前的论文里验证过了)
- L1+L12最有效。
- 白化很有用。
确实和苏神的论文很像,不过这种实验丰富、验证广泛类型的论文挺符合EMNLP的喜好吧。
对BERT不同层数组合的效果做了可视化,比较有趣。

参考:
苏神blog: 你可能不需要BERT-flow:一个线性变换媲美BERT-flow
知乎专栏:细说Bert-whitening的原理
知乎专栏:细说Bert-whitening的原理















 1354
1354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









