







参考:https://zhuanlan.zhihu.com/p/102285855
https://blog.csdn.net/Mercedes_wwz/article/details/109028124
[公式] : 用户;
[公式] : 推荐结果集合;
[公式] : [公式] 中已被选中集合; R\S: [公式] 中未被选中集合;
[公式] : 权重系数,调节推荐结果相关性与多样性
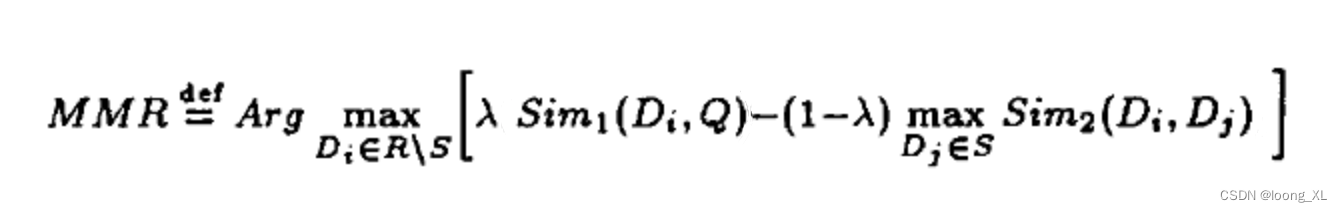
sim1是query与doc的相关权重;sim2是docs之间的相关权重
def MMR(itemScoreDict, similarityMatrix, lambdaConstant=0.5, topN=20):
s, r = [], list(itemScoreDict.keys())
while len(r) > 0:
score = 0
selectOne = None
for i in r:
firstPart = itemScoreDict[i]
secondPart = 0
for j in s:
sim2 = similarityMatrix[i][j]
if sim2 > secondPart:
secondPart = sim2
equationScore = lambdaConstant * (firstPart - (1 - lambdaConstant) * secondPart)
if equationScore > score:
score = equationScore
selectOne = i
if selectOne == None:
selectOne = i
r.remove(selectOne)
s.append(selectOne)
return (s, s[:topN])[topN > len(s)]
或
import numpy as np
class MMRModel(object):
# def __init__(self,item_score_dict,similarity_matrix,lambda_constant,topN):
# self.item_score_dict = item_score_dict
# self.similarity_matrix = similarity_matrix
# self.lambda_constant = lambda_constant
# self.topN = topN
def __init__(self, **kwargs):
self.lambda_constant = kwargs['lambda_constant']
self.topN = kwargs['topN']
def build_data(self):
sorce = np.random.random(size=(self.topN))
item = np.random.randint(1, 1000, size=self.topN)
self.item_score_dict = dict()
for i in range(len(item)):
self.item_score_dict[i] = sorce[i]
item_embedding = np.random.randn(self.topN, self.topN) # item的embedding
item_embedding = item_embedding / np.linalg.norm(item_embedding, axis=1, keepdims=True)
sim_matrix = np.dot(item_embedding, item_embedding.T) # item之间的相似度矩阵
self.similarity_matrix = sorce.reshape((self.topN, 1)) * sim_matrix * sorce.reshape((1, self.topN))
def mmr(self):
s, r = [], list(self.item_score_dict.keys())
while len(r) > 0:
score = 0
select_item = None
for i in r:
sim1 = self.item_score_dict[i]
sim2 = 0
for j in s:
if self.similarity_matrix[i][j] > sim2:
sim2 = self.similarity_matrix[i][j]
equation_score = self.lambda_constant * sim1 - (1 - self.lambda_constant) * sim2
if equation_score > score:
score = equation_score
select_item = i
if select_item == None:
select_item = i
r.remove(select_item)
s.append(select_item)
return (s, s[:self.topN])[self.topN > len(s)]
if __name__ == "__main__":
kwargs = {
'lambda_constant': 0.5,
'topN': 5,
}
dpp_model = MMRModel(**kwargs)
dpp_model.build_data()
print(dpp_model.mmr())
使用tfidf得分来测试
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import jieba
import jieba.analyse
import numpy as np
def stopwordslist(path):
stopwords = [line.strip() for line in open(path, encoding='UTF-8').readlines()]
return stopwords
def split_word(sentence_depart):
# 输出结果为outstr
outstr = ''
# 去停用词
for word in sentence_depart:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr
def cut_(words):
all_querys = []
# qq1 = datas_all["{}".format(word)].unique()
for ii in list(words):
ex_ = split_word(jieba.cut(str(ii)))
# print("111",ii,ex_)
all_querys.append(ex_)
return all_querys
# 进行分词
path = r'D:\LTR_REC\stopwords.txt'
jieba.analyse.set_stop_words(path)
stopwords = stopwordslist(path) # 创建一个停用词列表
query = ["我要看免费电影"]
lists=["电影频道","免费电影","我要看免费电影","西游记","我要"]
query = cut_(query)
lists = cut_(lists)
tfidf_vec = TfidfVectorizer(min_df=1, max_df=1.0, token_pattern='\\b\\w+\\b')
def count_sim(x, y):
x_len = len(x)
y_len = len(y)
coss = np.zeros((x_len,y_len))
# print(coss)
for i in range(x_len):
for j in range(y_len):
corpus = [x[i], y[j]]
# print(corpus)
vectoerizer = tfidf_vec.fit_transform(corpus)
# print(vectoerizer)
cos1 = cosine_similarity(vectoerizer)[0]
# print(cos1)
coss[i][j] = cos1[1]
return coss
print(query, lists)
itemScoreDict = { num:i for num,i in enumerate(count_sim(query, lists)[0])} ##query与docs tfidf相关度
similarityMatrix = count_sim(lists, lists) ## docs内容间tfidf相似度
print(itemScoreDict)
print(similarityMatrix)
def MMR(itemScoreDict, similarityMatrix, lambdaConstant=0.5, topN=20):
s, r = [], list(itemScoreDict.keys())
while len(r) > 0:
score = 0
selectOne = None
for i in r:
firstPart = itemScoreDict[i]
secondPart = 0
for j in s:
sim2 = similarityMatrix[i][j]
if sim2 > secondPart:
secondPart = sim2
equationScore = lambdaConstant * (firstPart - (1 - lambdaConstant) * secondPart)
if equationScore > score:
score = equationScore
selectOne = i
if selectOne == None:
selectOne = i
r.remove(selectOne)
s.append(selectOne)
return (s, s[:topN])[topN > len(s)]
print(MMR(itemScoreDict, similarityMatrix))
****优化版,只算一半的矩阵,docs间矩阵计算
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import jieba
import jieba.analyse
import numpy as np
def stopwordslist(path):
stopwords = [line.strip() for line in open(path, encoding='UTF-8').readlines()]
return stopwords
def split_word(sentence_depart):
# 输出结果为outstr
outstr = ''
# 去停用词
for word in sentence_depart:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr
def cut_(words):
all_querys = []
# qq1 = datas_all["{}".format(word)].unique()
for ii in list(words):
ex_ = split_word(jieba.cut(str(ii)))
# print("111",ii,ex_)
all_querys.append(ex_)
return all_querys
# 进行分词
path = r'D:\LTR_REC\stopwords.txt'
jieba.analyse.set_stop_words(path)
stopwords = stopwordslist(path) # 创建一个停用词列表
query = ["西游记"]
lists=['西游记',
'西游记',
'西游记',
'西游记',
'西游记',
'新西游记',
'西游记续集',
'西游记续集',
'西游记后传',
'新西游记',
'西游记手绘版',
'西游记少儿版',
'西游记红孩儿',
'西游记比丘国',
'天真派西游记',
'西游记之沙僧',
'西游记之唐僧',
'西游记的故事',
'西游记:女儿国',
'凯叔·西游记【贝塔】',
'西游记之白龙马',
'西游记之猪八戒',
'西游记之孙悟空',
'不一样的西游记',
'西游记故事儿歌',
'西游记之红孩儿',
'西游记 张掖寻踪',
'水木剧场西游记',
'西游记里的故事',
'西游记:张掖寻踪',
'西游记之再世妖王',
'名著导读之西游记',
'眼镜叔叔讲西游记',
'西游记之西梁女国',
'西游记之大圣归来',
'西游记之三件宝贝',
'西游记里的那些事',
'西游记之大闹天宫',
'你不知道的西游记',
'凯叔西游记全集音频',
'小戏骨西游记红孩儿',
'西游记之锁妖封魔塔',
'西游记精彩片段集锦',
'西游记中的那些事儿',
'百家讲坛 玄奘西游记',
'七彩童书坊:西游记音频',
'西游记之大闹天宫粤语',
'西游记篇500个汉字轻松学',
'紫微斗数之西游记—白龙马',
'紫微斗数评说西游记系列',
'西游记之再世妖王 动漫版',
'韩田鹿讲给青少年的西游记',
'紫微斗数评说西游记特辑1',
'西游记师徒四人是什么星座',
'西游记之孙悟空三打白骨精',
'西游记之大闹天宫环绕声版',
'西游记中不为人知的奇葩事',
'弹词选曲西游记·白虎岭遇妖',
'妖怪密码:解密神魔巅峰西游记',
'精编趣讲西游记让孩子开心学名著',
'百万孩子都在看的西游记精选故事集',
'西游记女儿情-李萍丨炫舞未来广场舞蹈',
'西游记之动物世界:妖怪原型竟然是这些动物']
query = cut_(query)
lists = cut_(lists)
tfidf_vec = TfidfVectorizer(min_df=1, max_df=1.0, token_pattern='\\b\\w+\\b')
def count_sim(x, y):
x_len = len(x)
y_len = len(y)
coss = np.zeros((x_len,y_len))
# print(coss)
for i in range(x_len):
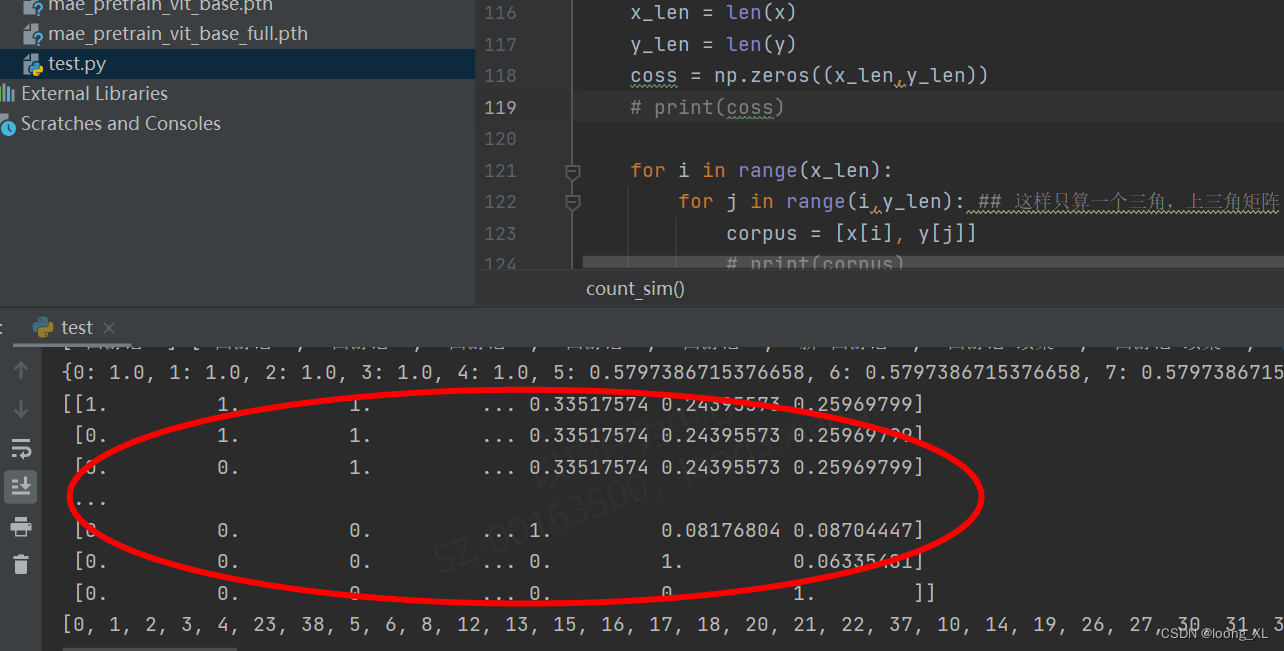
for j in range(i,y_len): ## 这样只算一个三角,上三角矩阵
corpus = [x[i], y[j]]
# print(corpus)
vectoerizer = tfidf_vec.fit_transform(corpus)
# print(vectoerizer)
cos1 = cosine_similarity(vectoerizer)[0]
# print(cos1)
coss[i][j] = cos1[1]
return coss
print(query, lists)
itemScoreDict = { num:i for num,i in enumerate(count_sim(query, lists)[0])} ##query与docs tfidf相关度
similarityMatrix = count_sim(lists, lists) ## docs内容间tfidf相似度
print(itemScoreDict)
# print(count_sim(query, lists))
print(similarityMatrix)
# assert similarityMatrix[2][3]==similarityMatrix[3][2]
def MMR(itemScoreDict, similarityMatrix, lambdaConstant=0.5, topN=20):
s, r = [], list(itemScoreDict.keys())
while len(r) > 0:
score = 0
selectOne = None
for i in r:
firstPart = itemScoreDict[i]
secondPart = 0
for j in s:
### 三角矩阵,对称矩阵的最大特点就是a[m][n] = a[n][m]
if j<i:
sim2 = similarityMatrix[j][i]
else:
sim2 = similarityMatrix[i][j]
if sim2 > secondPart:
secondPart = sim2
equationScore = lambdaConstant * (firstPart - (1 - lambdaConstant) * secondPart)
if equationScore > score:
score = equationScore
selectOne = i
if selectOne == None:
selectOne = i
r.remove(selectOne)
s.append(selectOne)
return (s, s[:topN])[topN > len(s)]
print(MMR(itemScoreDict, similarityMatrix))


















 3685
3685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











