









 文章介绍了如何使用prompt提示让大模型如Mermaid生成流程图,同时展示了如何通过三元组结构表示西红柿炒鸡蛋的烹饪步骤,并提到了中英文翻译的功能实现,包括API调用和在线编辑器的使用。
文章介绍了如何使用prompt提示让大模型如Mermaid生成流程图,同时展示了如何通过三元组结构表示西红柿炒鸡蛋的烹饪步骤,并提到了中英文翻译的功能实现,包括API调用和在线编辑器的使用。
1、prompt提示让大模型总结生成Mermaid流程图
生成内容、总结文章让大模型Mermaid流程图展示:
mermaid 美人鱼, 是一个类似 markdown,用文本语法来描述文档图形(流程图、 时序图、甘特图)的工具,您可以在文档中嵌入一段 mermaid 文本来生成 SVG 形式的图形
Prompt 示例:用横向的 Mermaid 图表来 xxx。
kimi效果示例:
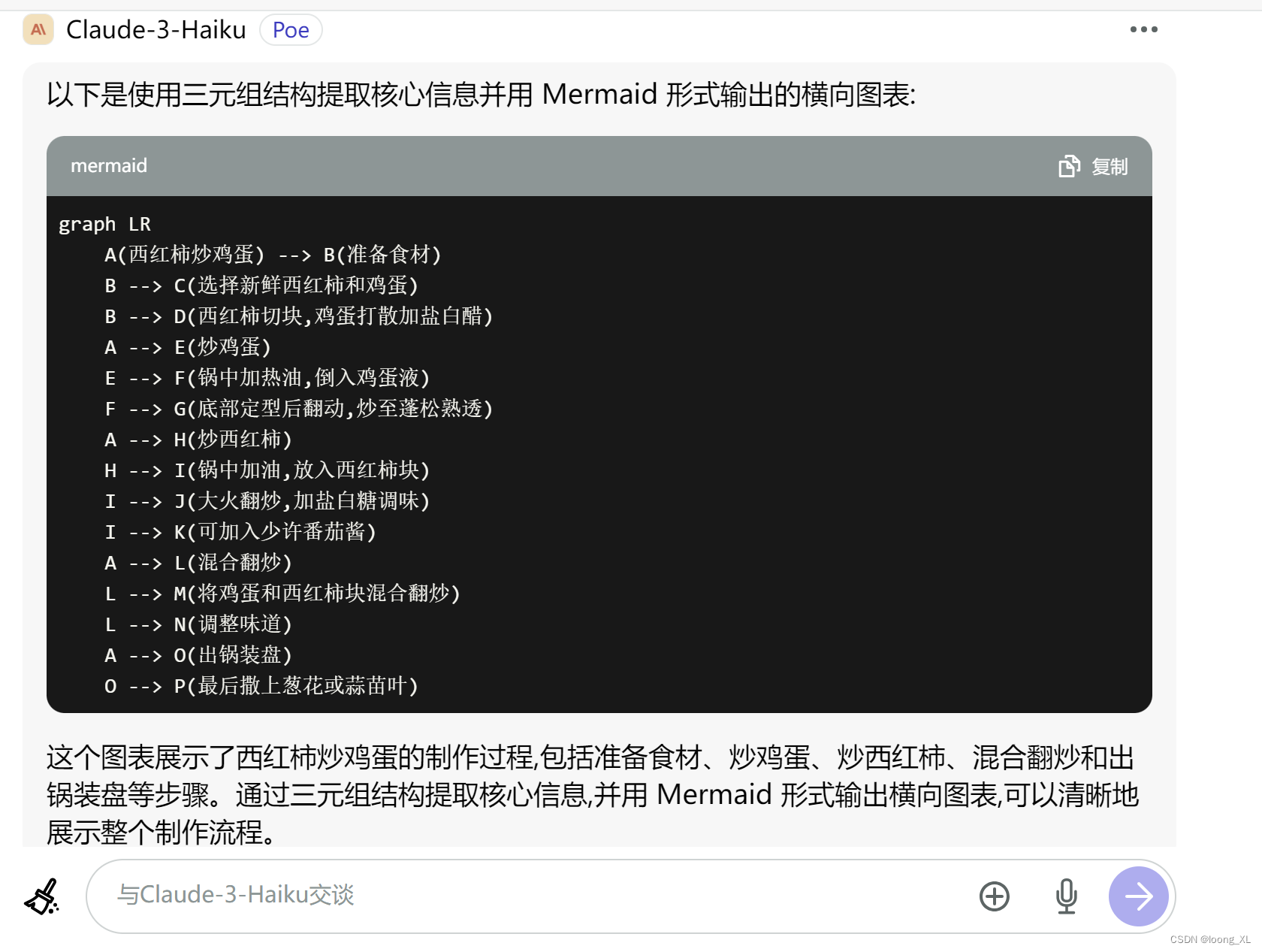
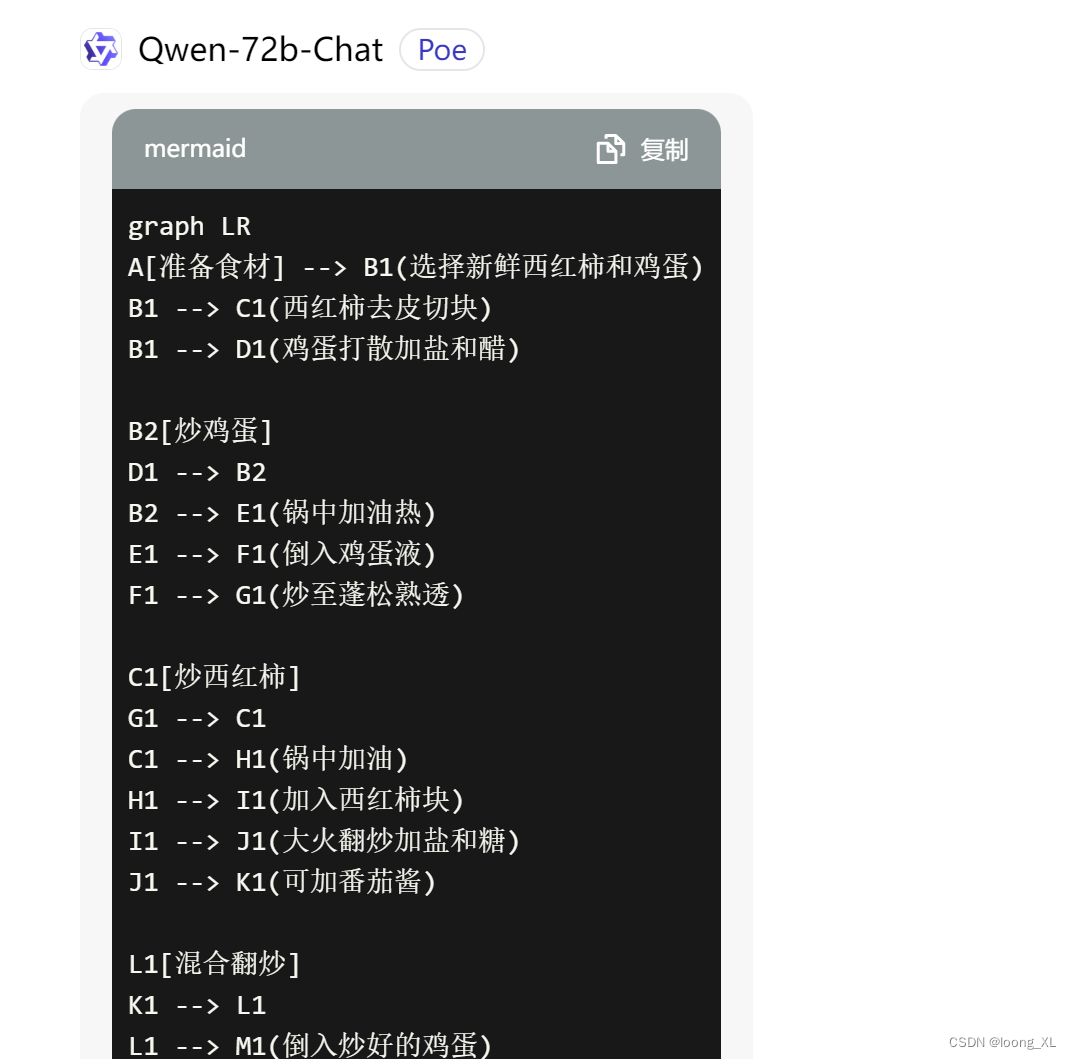
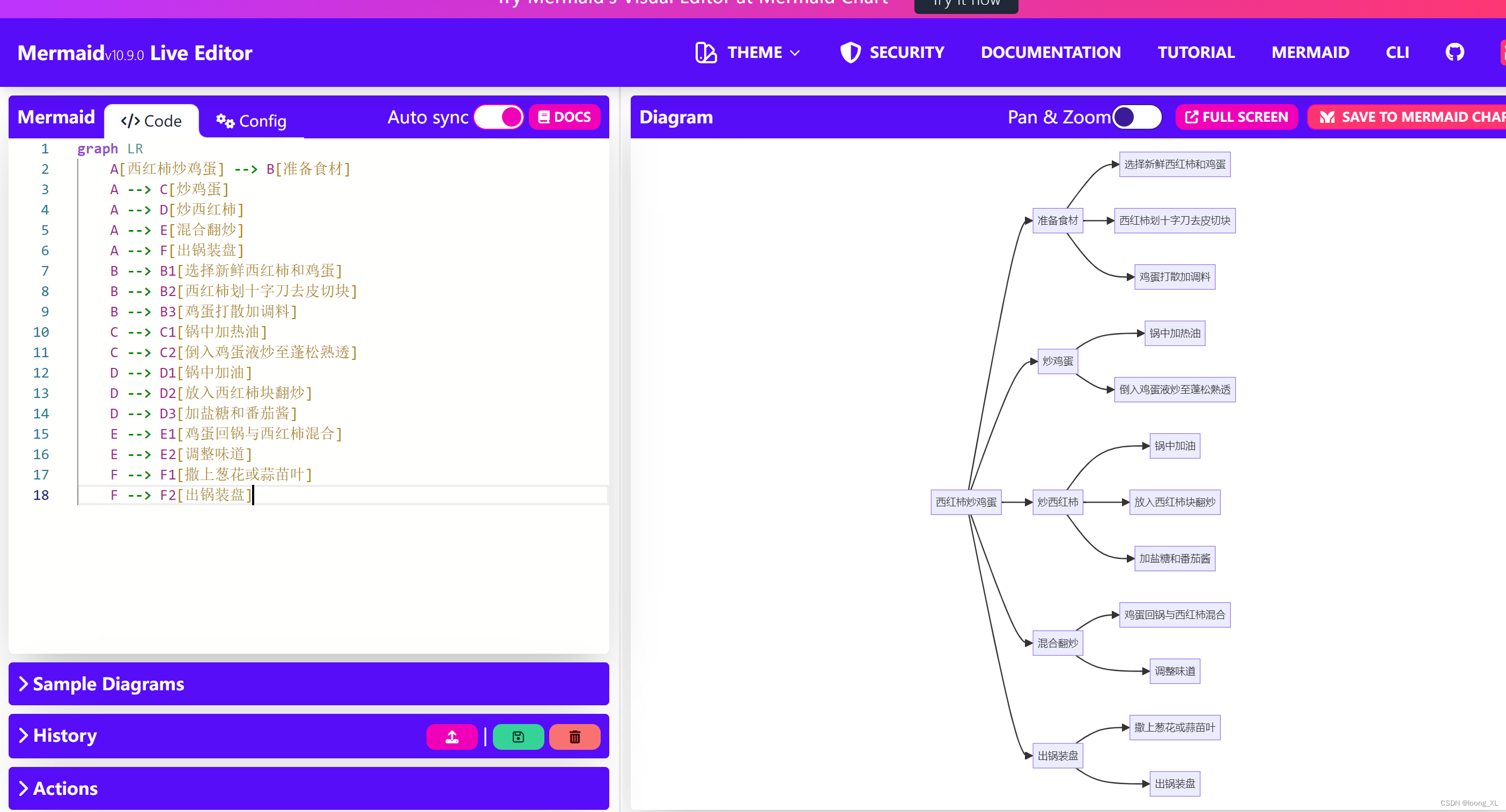
使用三元组结构提取以下材料的核心信息,用Mermaid的形式输出横向图表。
西红柿炒鸡蛋是一道经典的中式家常菜,做法相对简单。以下是详细步骤:准备食材。选择新鲜的西红柿和鸡蛋,西红柿可以在顶部划十字刀,用开水烫后去皮,切成块状。鸡蛋打散,加入适量的盐和白醋,搅拌均匀。\
炒鸡蛋。在锅中加热适量油,将鸡蛋液倒入锅中,待底部定型后,用铲子翻动,炒至蓬松熟透,然后盛出备用。\
炒西红柿。在锅中加油,放入切好的西红柿块,大火翻炒,加入适量的盐和白糖,以中和西红柿的酸味,也可以加入少许番茄酱增加酸味。\
混合翻炒。将炒好的鸡蛋重新倒入锅中与西红柿块混合翻炒,调整味道。出锅装盘。最后撒上葱花或蒜苗叶,炒匀后即可出锅装盘。\
可以根据个人口味调整盐和糖的用量,以及是否加入番茄酱。这道菜的关键在于炒鸡蛋时要控制好火候和油温,以及西红柿炒制时要炒出汁水,使得整道菜口感更加丰富。
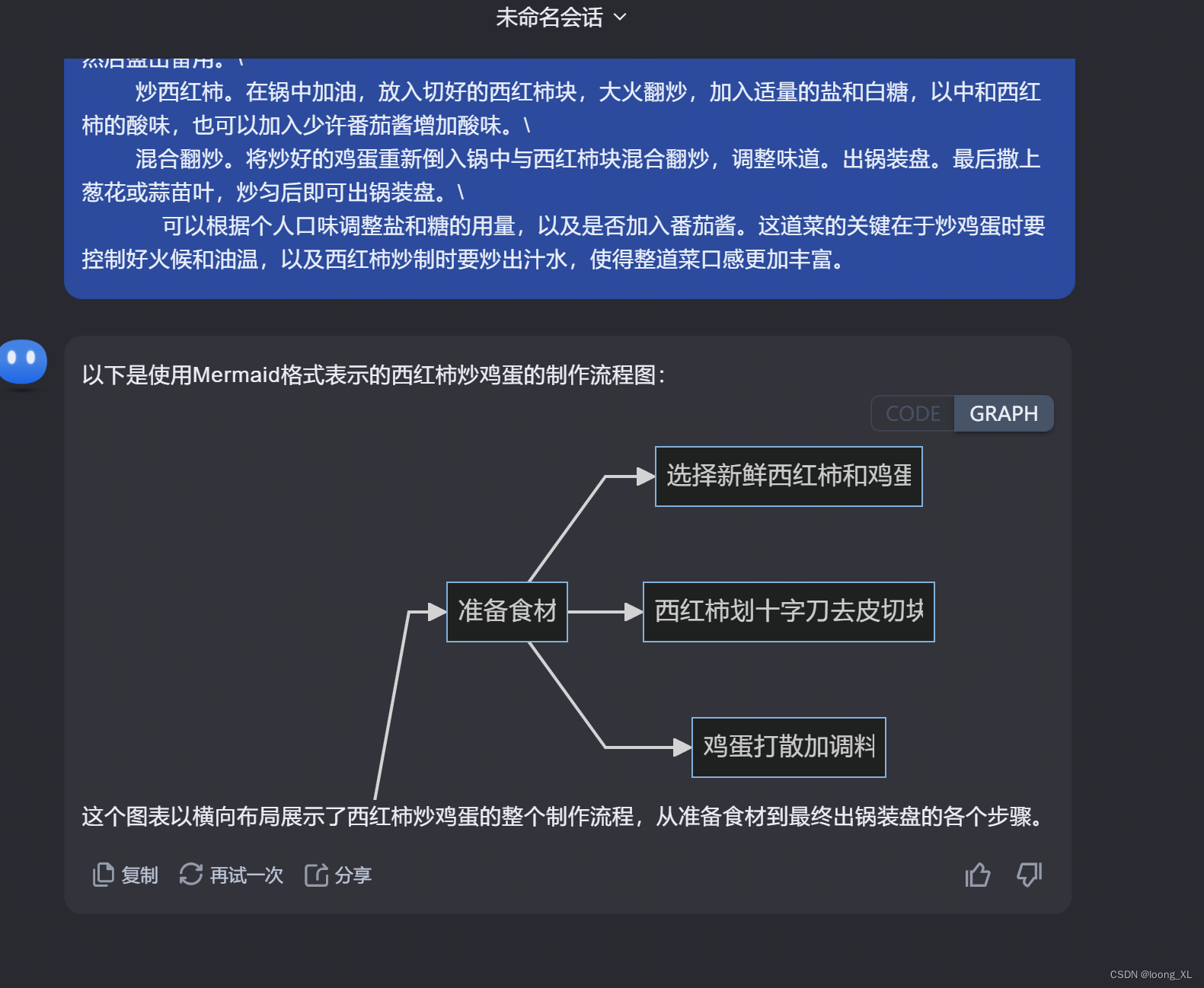
gpt3.5
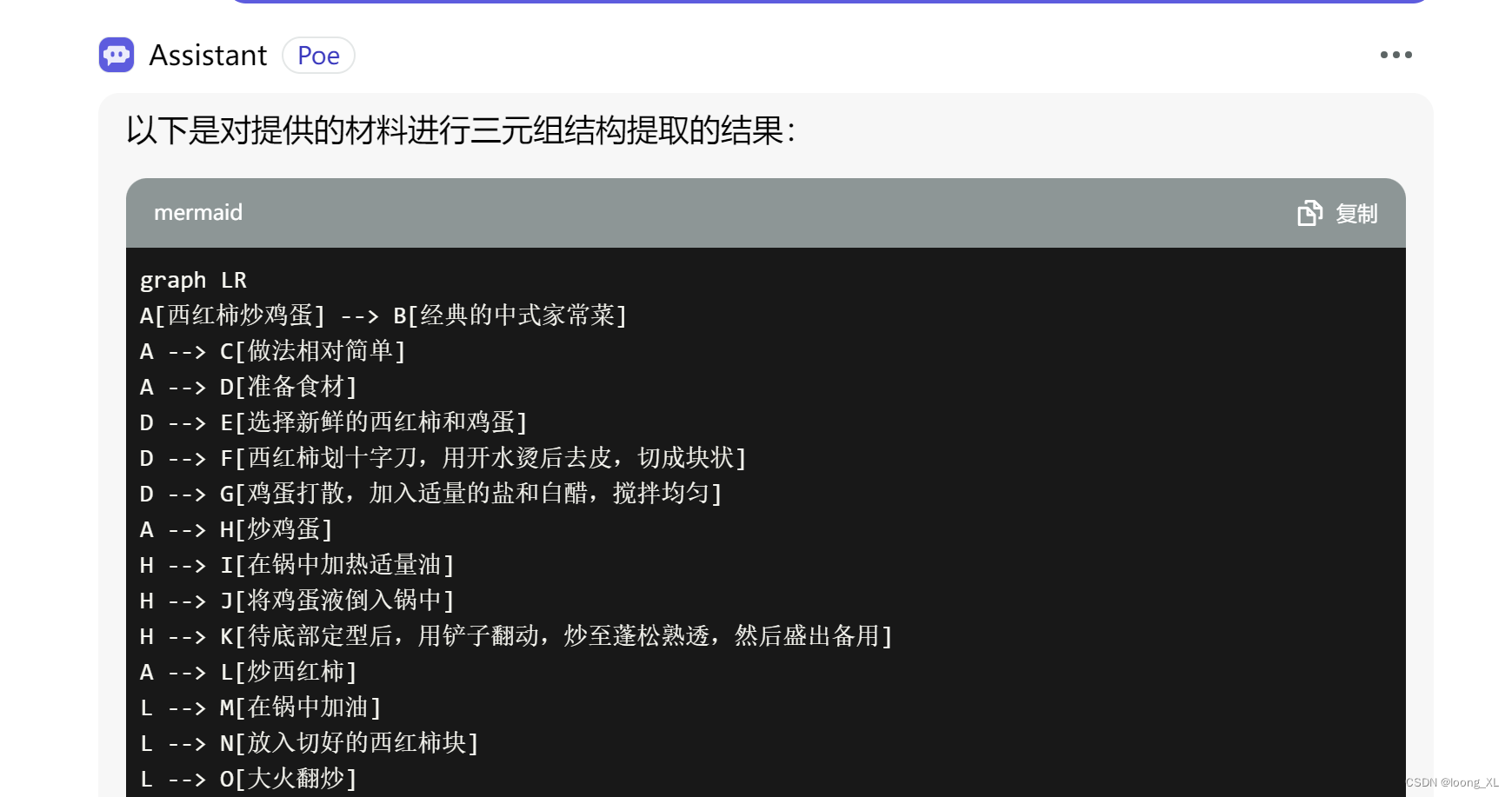
claude3
qwen
或把code在在线mermaid网站:
https://mermaid-js.github.io/mermaid-live-editor/edit
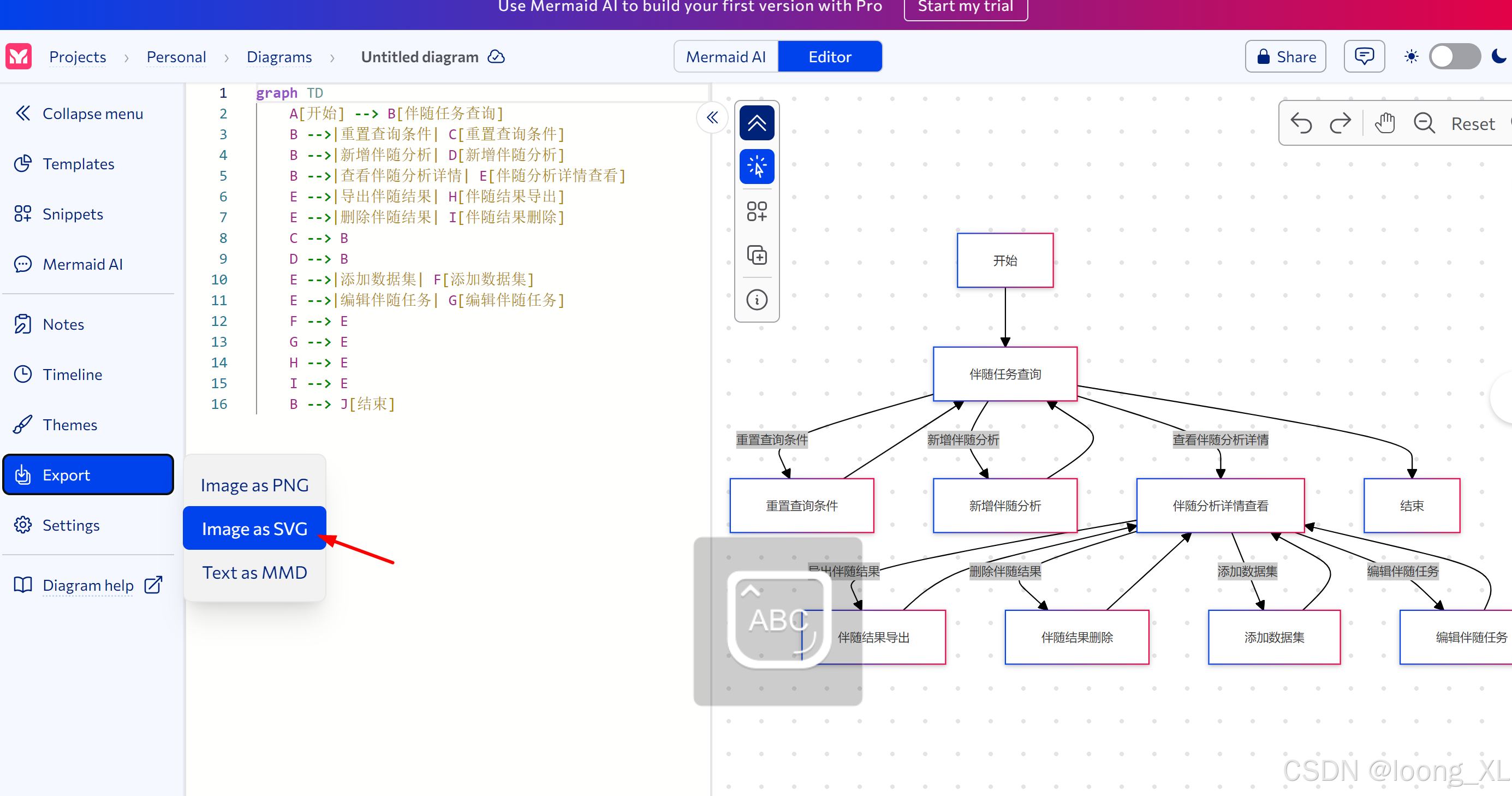
2、充当角色中英文翻译输出
import json,requests
def translate(content):
url = 'http://192***:11434/api/chat'
headers = {'Content-Type': 'application/json'}
pload = {
"model": "qwen:1.8b-chat",
"messages": [
{"role": "system", "content": ""},
{
"role": "user",
"content": f'''你是一个中英文翻译助手;
后面双引号内中文问题请翻译成英文回复,问题是"{content}"'''
}
],
"stream": False
}
response = requests.post(url, headers=headers, json=pload)
llm_text = json.loads(response.content)["message"]["content"]
print("AI:",llm_text)
return llm_text
自学
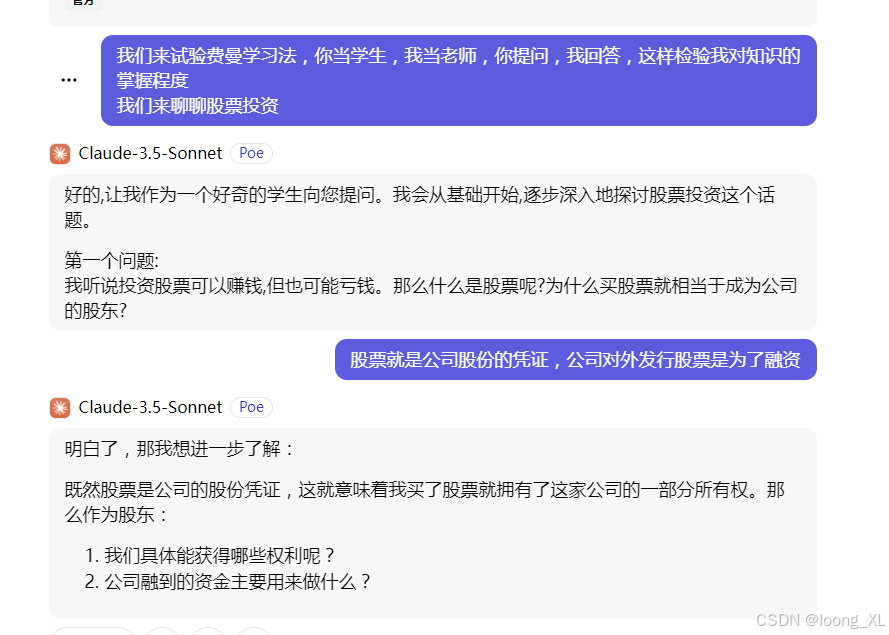
我们来试验费曼学习法,你当学生,我当老师,你提问,我回答,这样检验我对知识的掌握程度:
我们来聊聊股票投资




















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











