







文章目录
0. 获取数据集
关注公众号:『AI学习星球』
回复:贷款预言 即可获取数据下载。
论文辅导或算法学习可以通过公众号滴滴我

这是一个在Analytics Vidhya上的贷款预测问题,有两个数据集,训练集给出了一些贷款申请人的信息及其申请贷款的结果(被允许或者拒绝),测试集给出了一些贷款申请人的信息但没有其申请贷款的结果,需要对这些数据训练出一个分类模型并对测试集的数据进行预测。
这里对于放贷的理解,作出几点假设:
- 工资:工资越高,贷款更容易通过;
- 贷款期限和金额:贷款期限越短、金额越少的越容易通过;
- EMI:monthly incom 还贷额占月收入比例,占比越低越容易通过;
- 贷款历史:已偿清之前贷款的申请人,贷款通过的机率更大。
对于数据中的各变量描述如下:
- Loan_ID:唯一的贷款编码
- Gender:性别(Male/Female)
- Married:是否结婚(Y/N)
- Dependents:家属人数
- Education:教育水平 (Graduate/ UnderGraduate)
- Self_Employed:是否自雇(Y/N)
- ApplicantIncome:申请人收入
- CoapplicantIncome:共同申请人收入
- LoanAmount:贷款金额
- Loan_Amount_Term:贷款期限(单位为月)
- Credit_History:信用历史
- Property_Area:Urban/ Semi Urban/ Rural
- Loan_Status:贷款是否被允许 (Y/N)
1. 数据准备
1.1 导入数据
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
%matplotlib inline
# 导入数据
full_data = pd.read_csv('train_ctrUa4K.csv')
full_data.shape
(614, 13)
数据有614行,13列。
1.2 查看前五行数据
full_data.head()

数据字段说明已经在题目中给出
1.3 查看描述统计数据
full_data.describe()
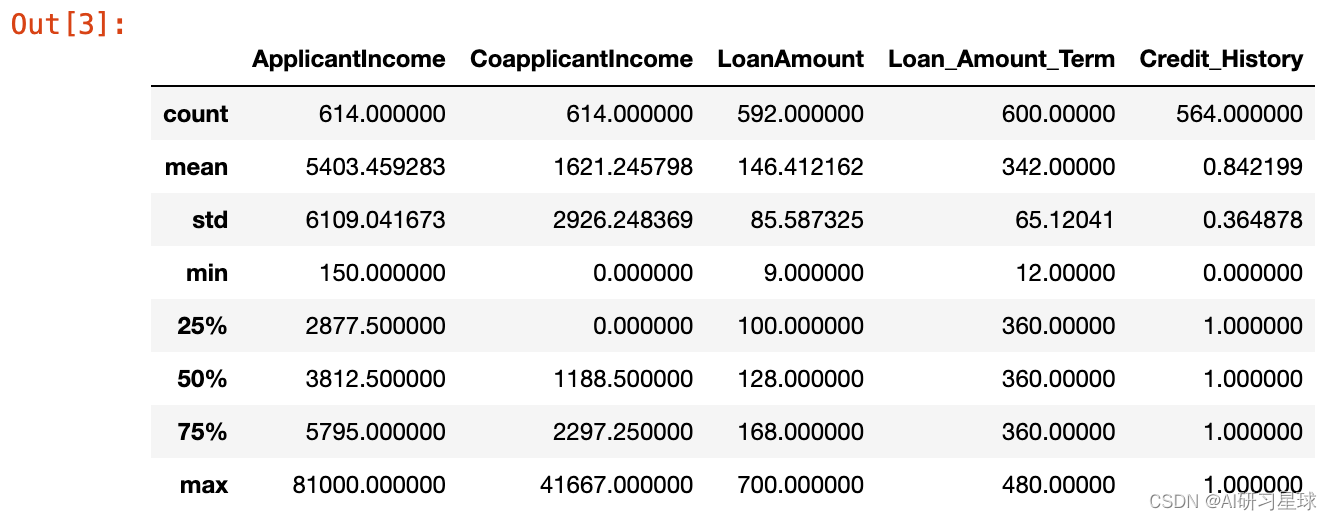
1.4 查看数据
full_data.describe()
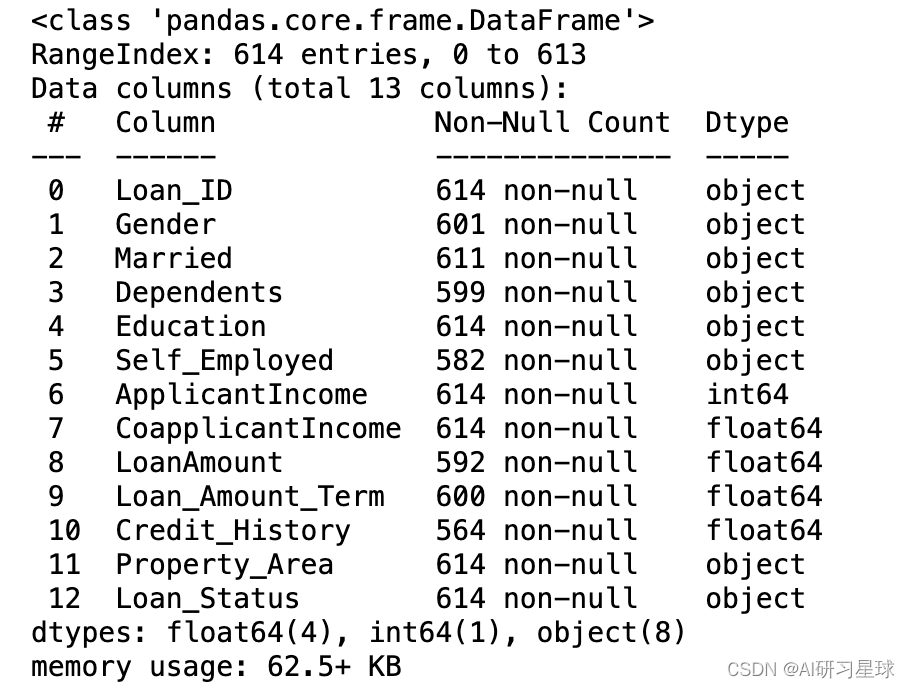
结论:有缺失植,需要进一步处理。
2. 开始分析
2.1 分析目标变量Loan_Status贷款状态
# 目标变量统计
full_data['Loan_Status'].value_counts()

# 统计百分比
full_data['Loan_Status'].value_counts(normalize=True)

sns.countplot(x='Loan_Status', data=full_data, palette = 'Set1')
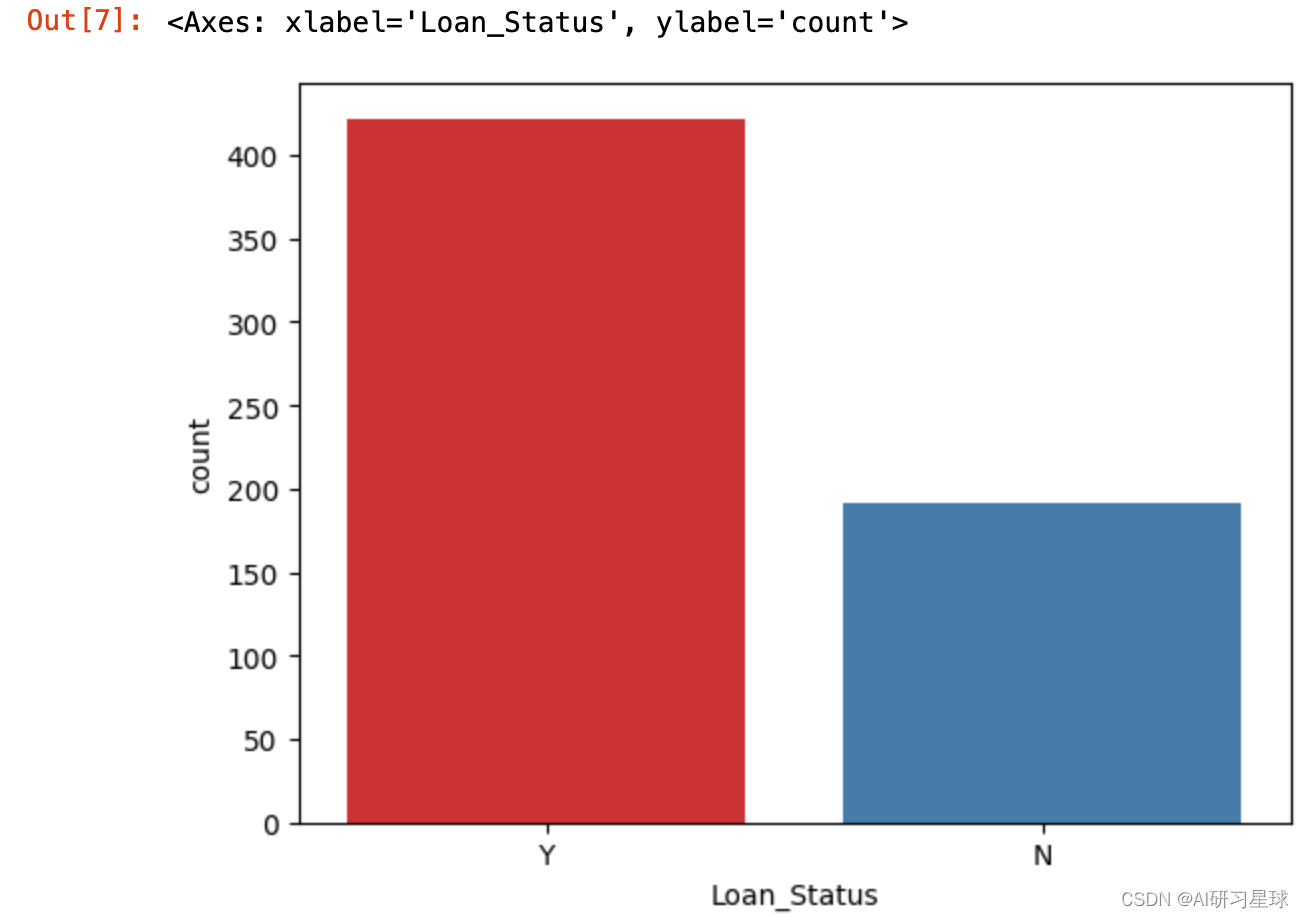
结论:614个人中有422人,约69%获得贷款机会
2.2 Gender性别特征
full_data['Gender'].value_counts(normalize=True)

sns.countplot(x='Gender', data=full_data, palette = 'Set1')
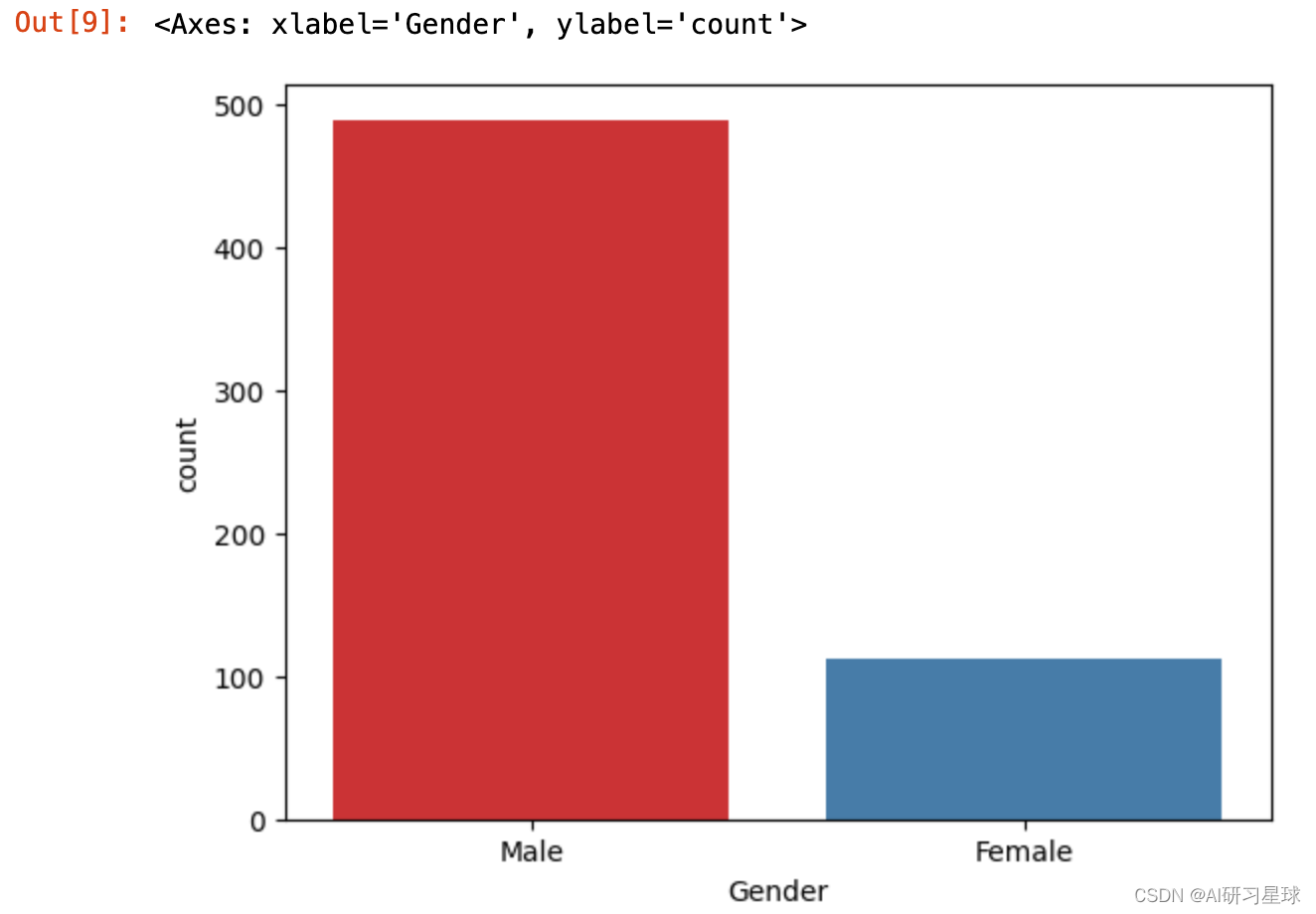
结论:数据集中80%的申请人是男性。
2.3 Married婚姻特征
full_data['Married'].value_counts(normalize=True).plot.bar(title= 'Married')
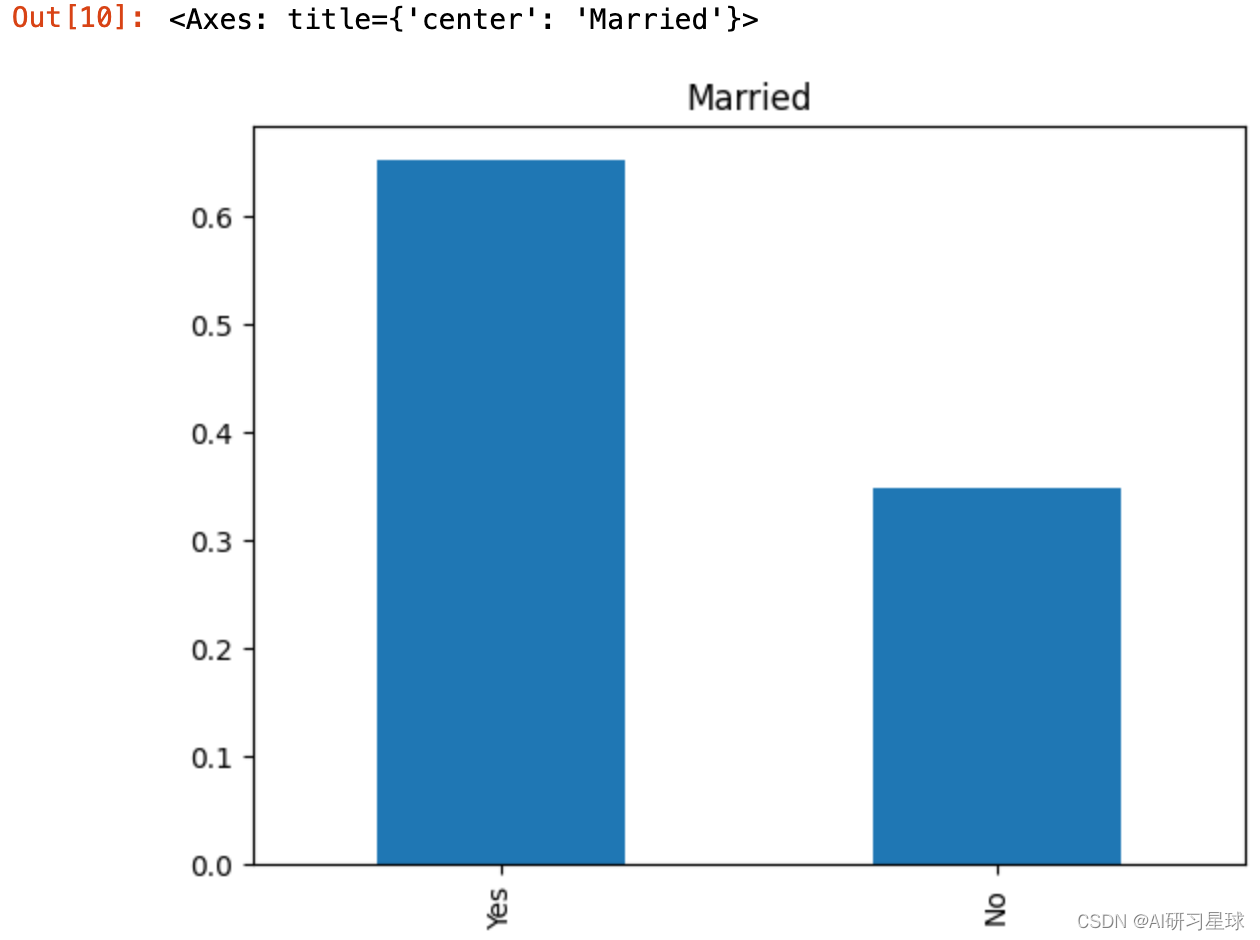
结论:有65%的申请贷款的人是已经结婚。
2.4 Dependent 亲属特征
Dependents=full_data['Dependents'].value_counts(normalize=True)
Dependents

Dependents.plot.bar(title= 'Dependents')
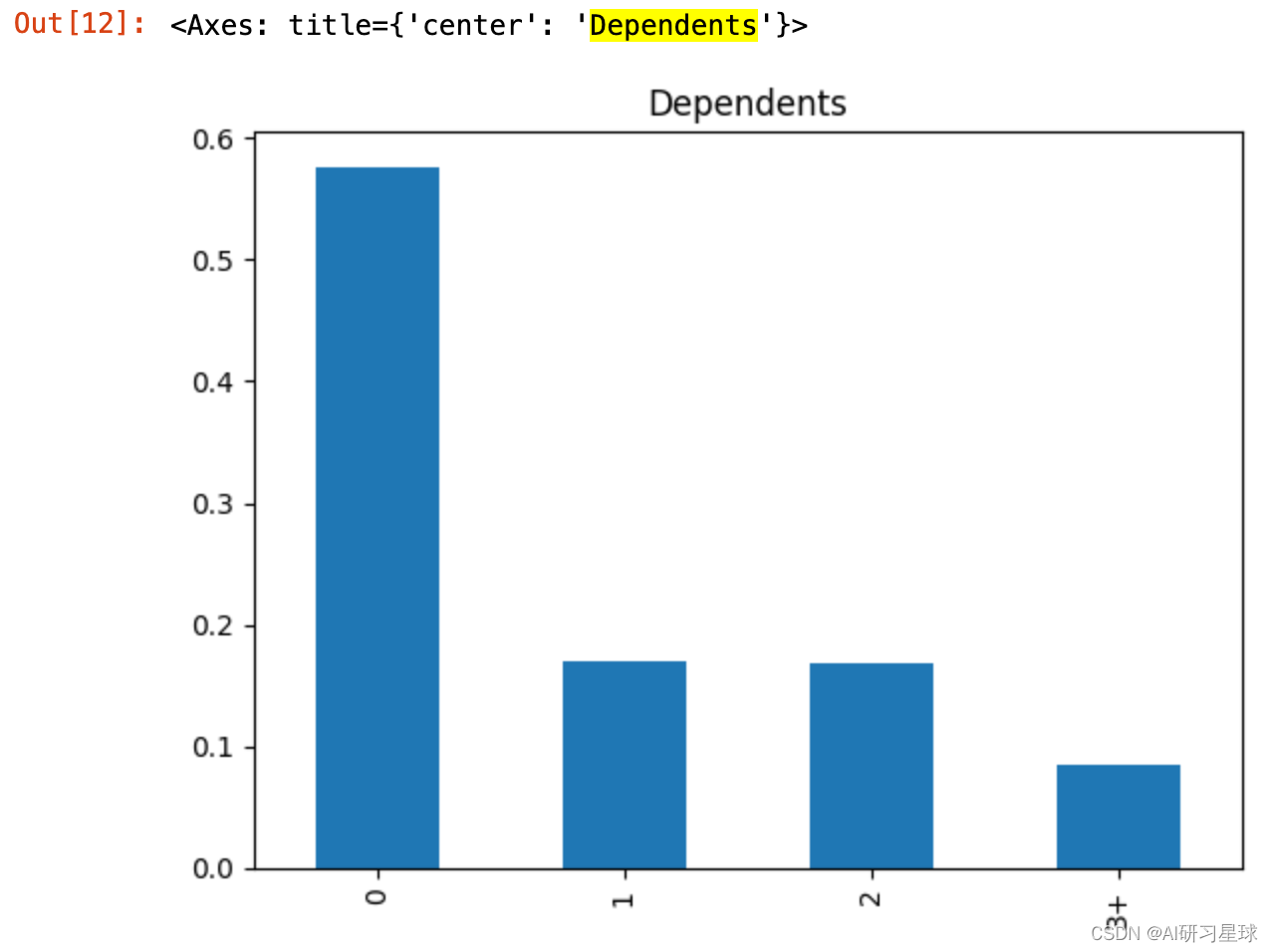
结论:贷款客户主要集中在没有亲属关系中,占到57%.
2.5 是否自雇人士
Self_Employed=full_data['Self_Employed'].value_counts(normalize=True)
Self_Employed

Self_Employed.plot.bar(title= 'Self_Employed')
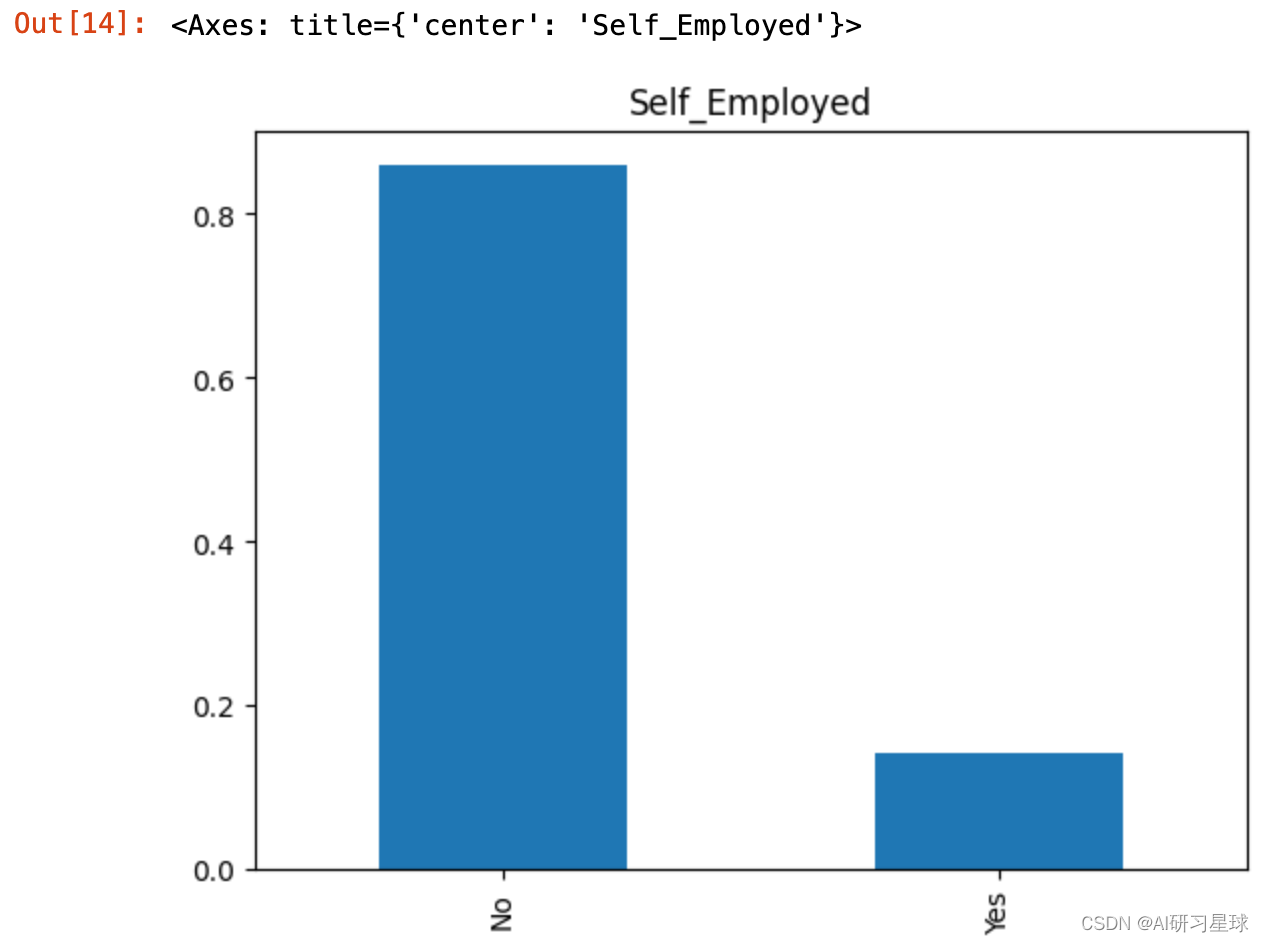
结论:大约有14%的申请人是自雇人士。
2.6 Loan_Amount_Term贷款时间
full_data['Loan_Amount_Term'].value_counts().plot.bar(title= 'Loan_Amount_Term')
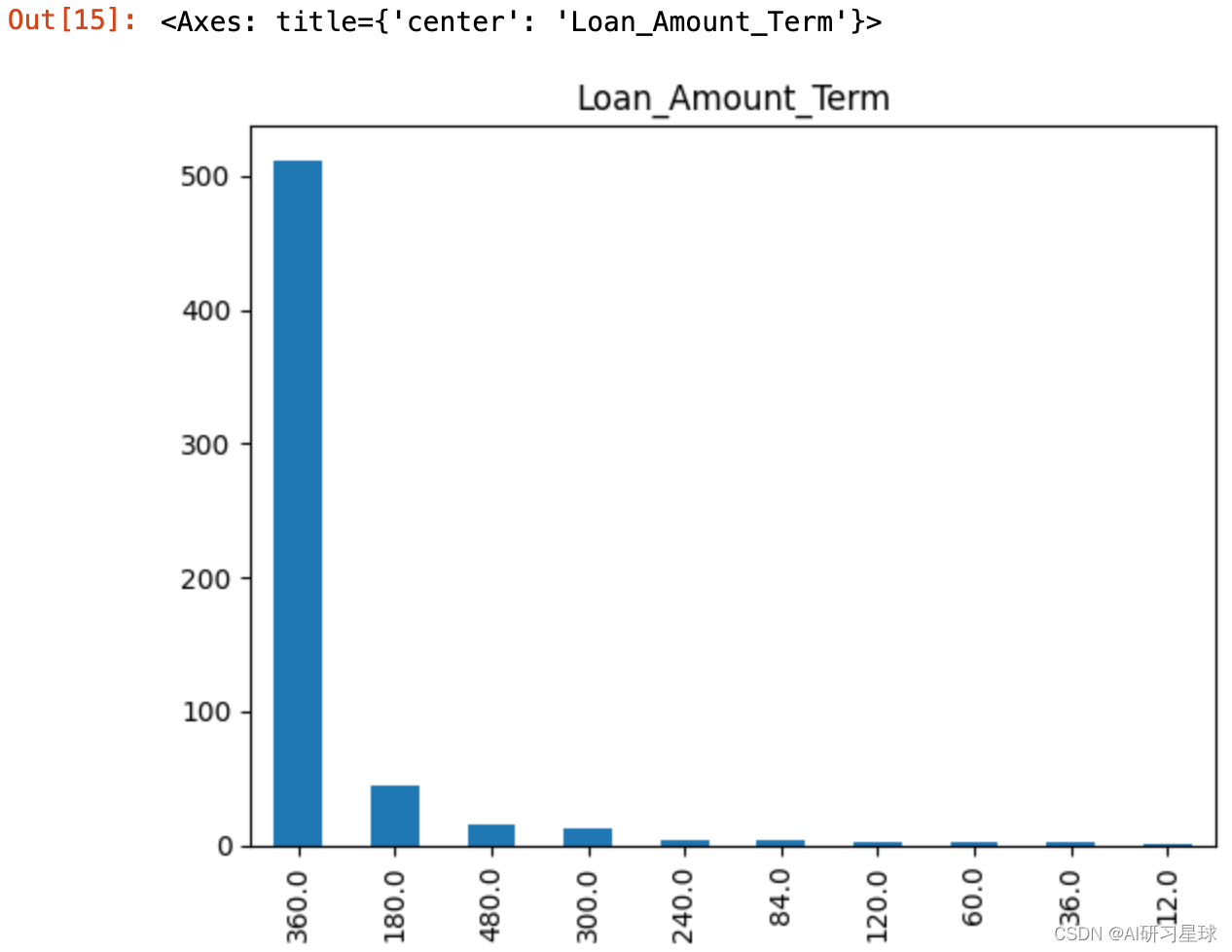
结论:贷款时间主要集中在360天
2.7 Credit_History信用记录变量
Credit_History=full_data['Credit_History'].value_counts(normalize=True)
Credit_History

Credit_History.plot.bar(title= 'Credit_History')
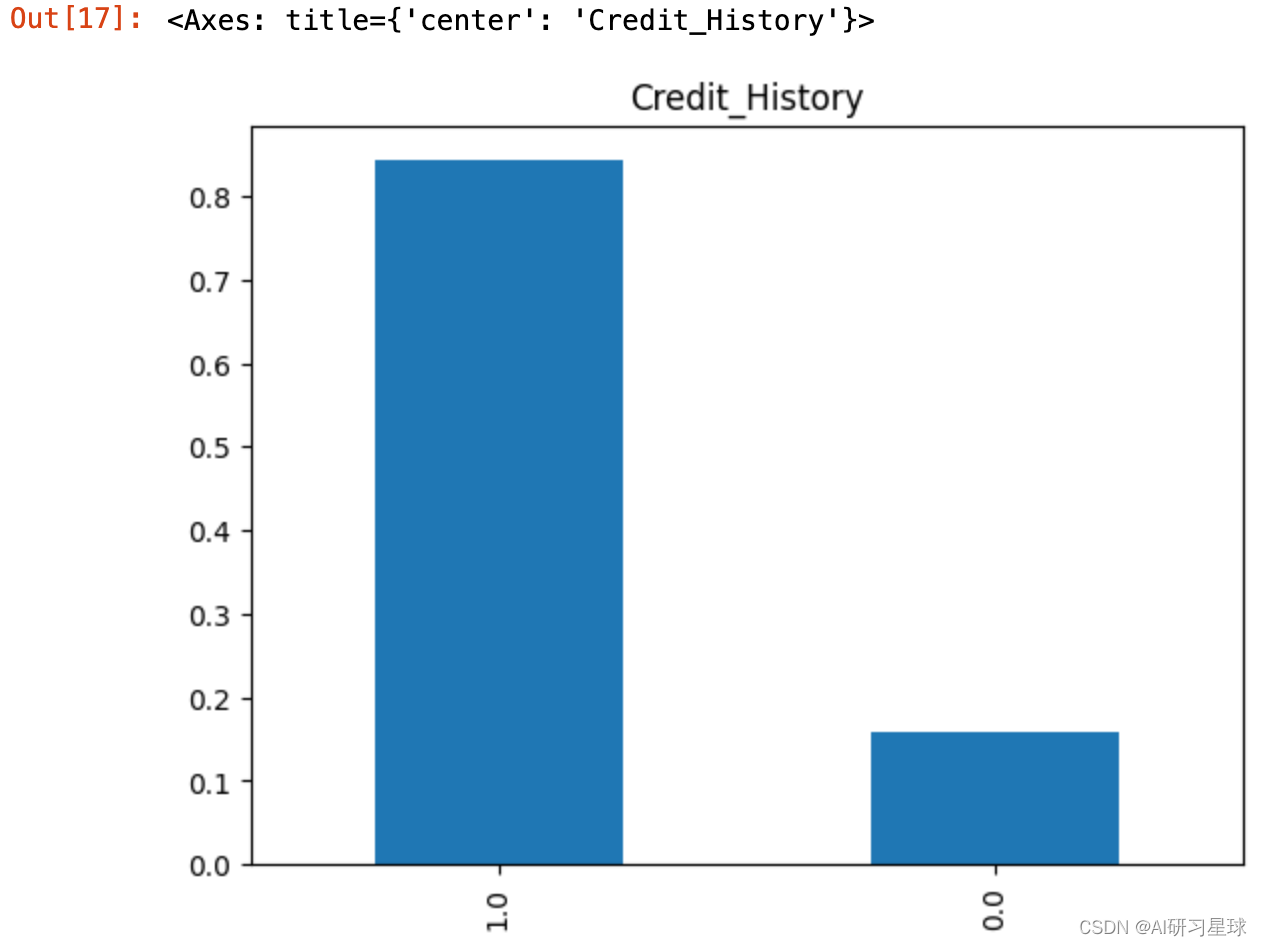
结论:大约84%的申请人已偿还债务了。
2.8 Education教育程度
Education=full_data['Education'].value_counts(normalize=True)
Education

Education.plot.bar(title= 'Education')
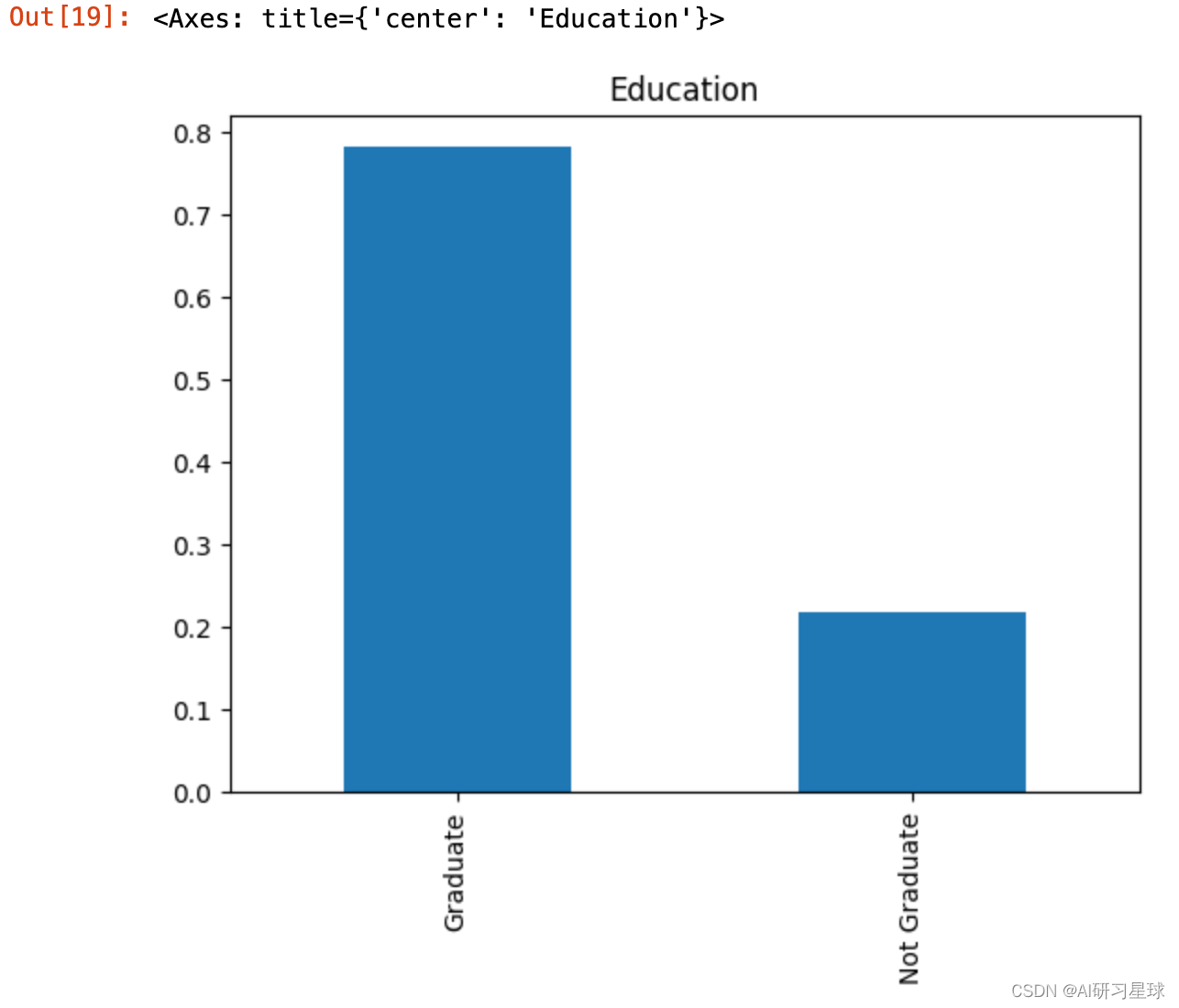
结论:贷款的客户中有接近80%的客户主要是受教育的毕业生
3. 双变量分析各自特征与目标变量(Loan_Status)的关系
3.1 性别与贷款关系
Gender=pd.crosstab(full_data['Gender'],full_data['Loan_Status'])
Gender.plot(kind="bar", stacked=True, figsize=(5,5))
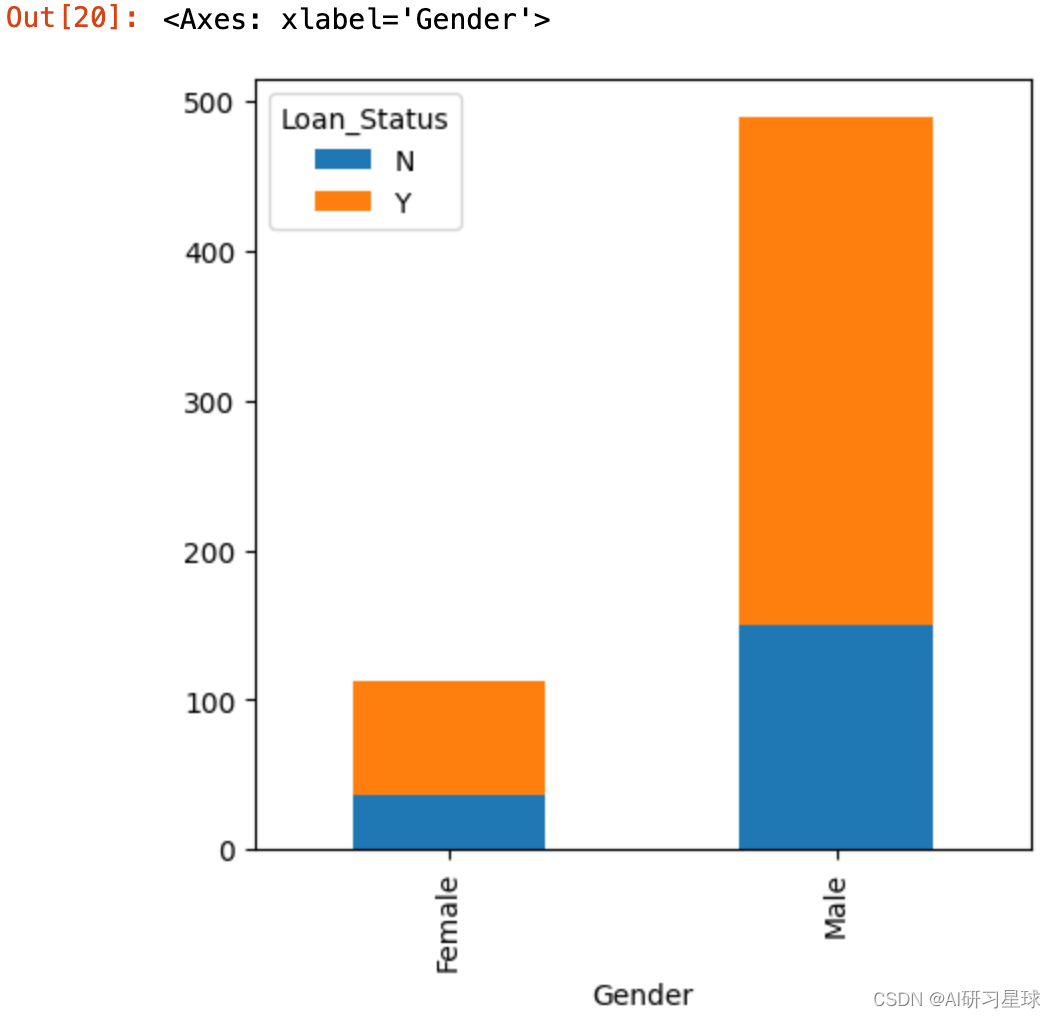
结果:男性更容易申请通过贷款
3.2 结婚与贷款关系
Married=pd.crosstab(full_data['Married'],full_data['Loan_Status'])
Married.plot(kind="bar", stacked=True, figsize=(5,5))
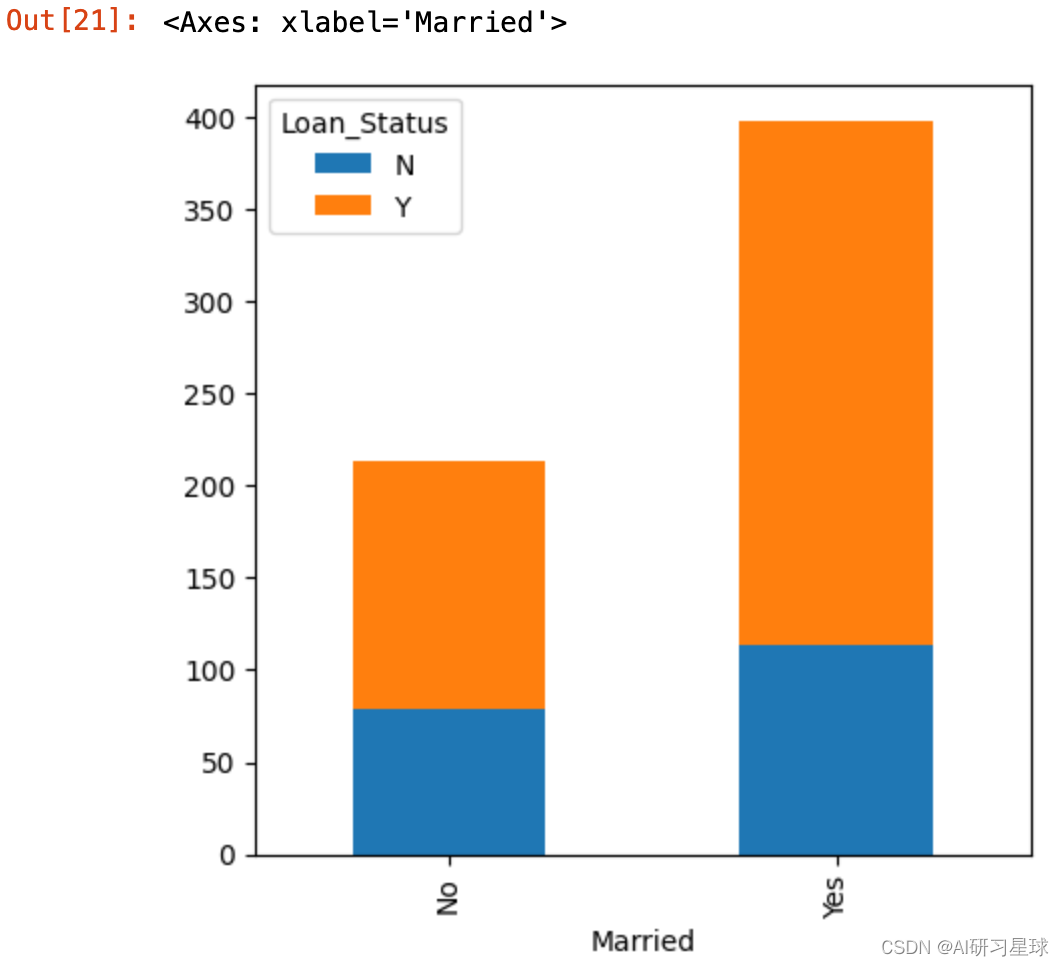
结论:已经结婚的客户申请贷款通过的最高。
3.3 亲属人数与贷款关系
Dependents=pd.crosstab(full_data['Dependents'],full_data['Loan_Status'])
Dependents.plot(kind="bar", stacked=True, figsize=(5,5))
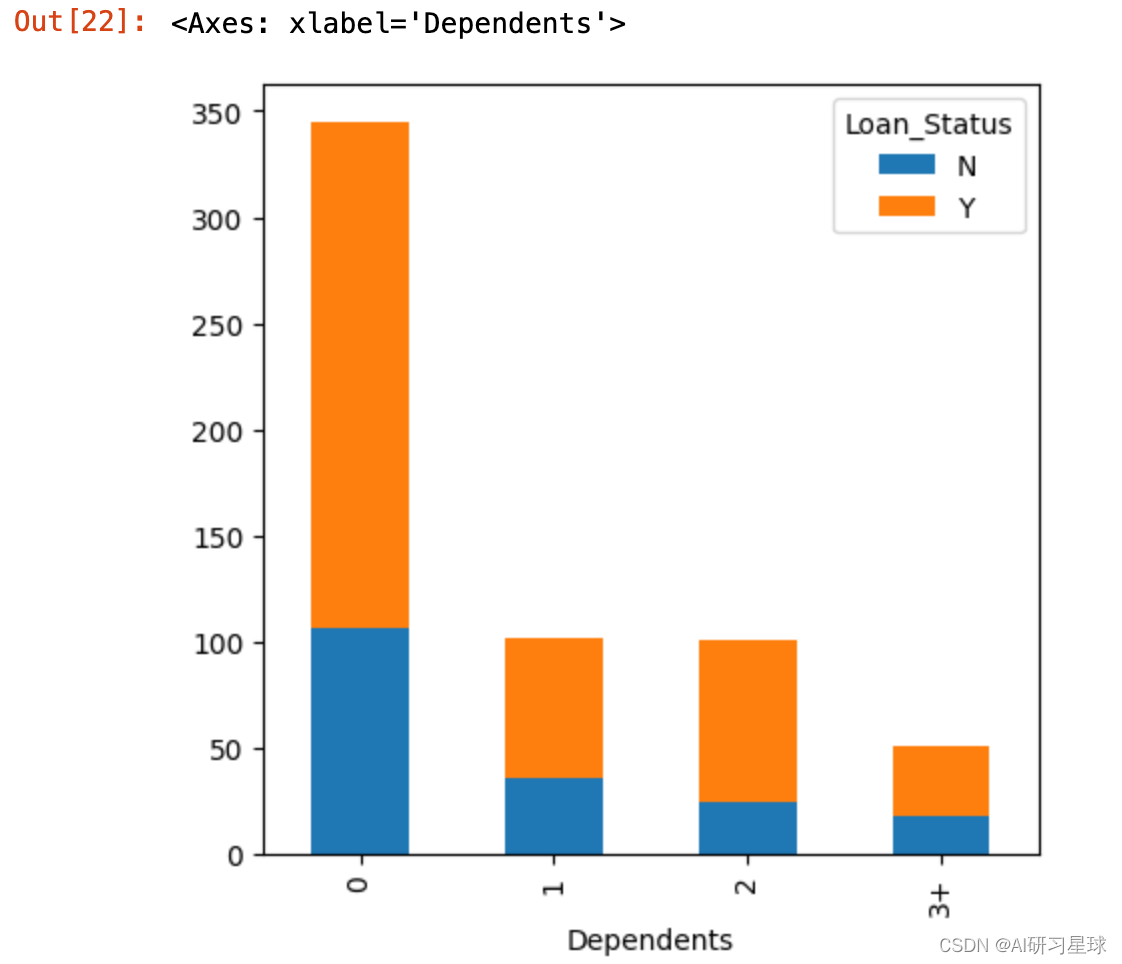
结论:没有亲属关系的客户也容易获得申请通过贷款
3.4 教育与贷款关系
Education=pd.crosstab(full_data['Education'],full_data['Loan_Status'])
Education.plot(kind="bar", stacked=True, figsize=(5,5))
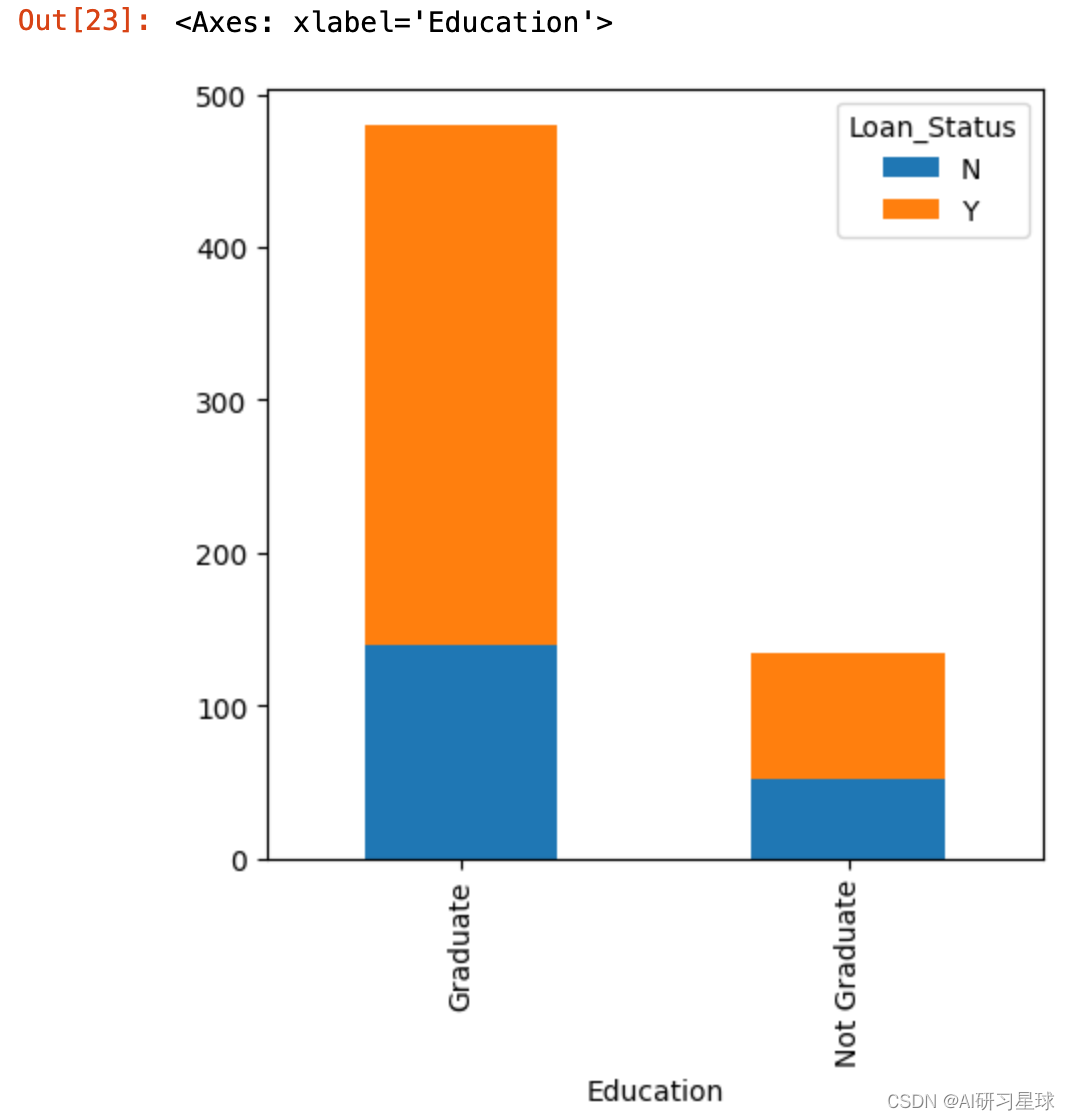
结论:已经受教育毕业的客户获得贷款更容易。
3.5 职业与贷款关系
Self_Employed=pd.crosstab(full_data['Self_Employed'],full_data['Loan_Status'])
Self_Employed.plot(kind="bar", stacked=True, figsize=(5,5))
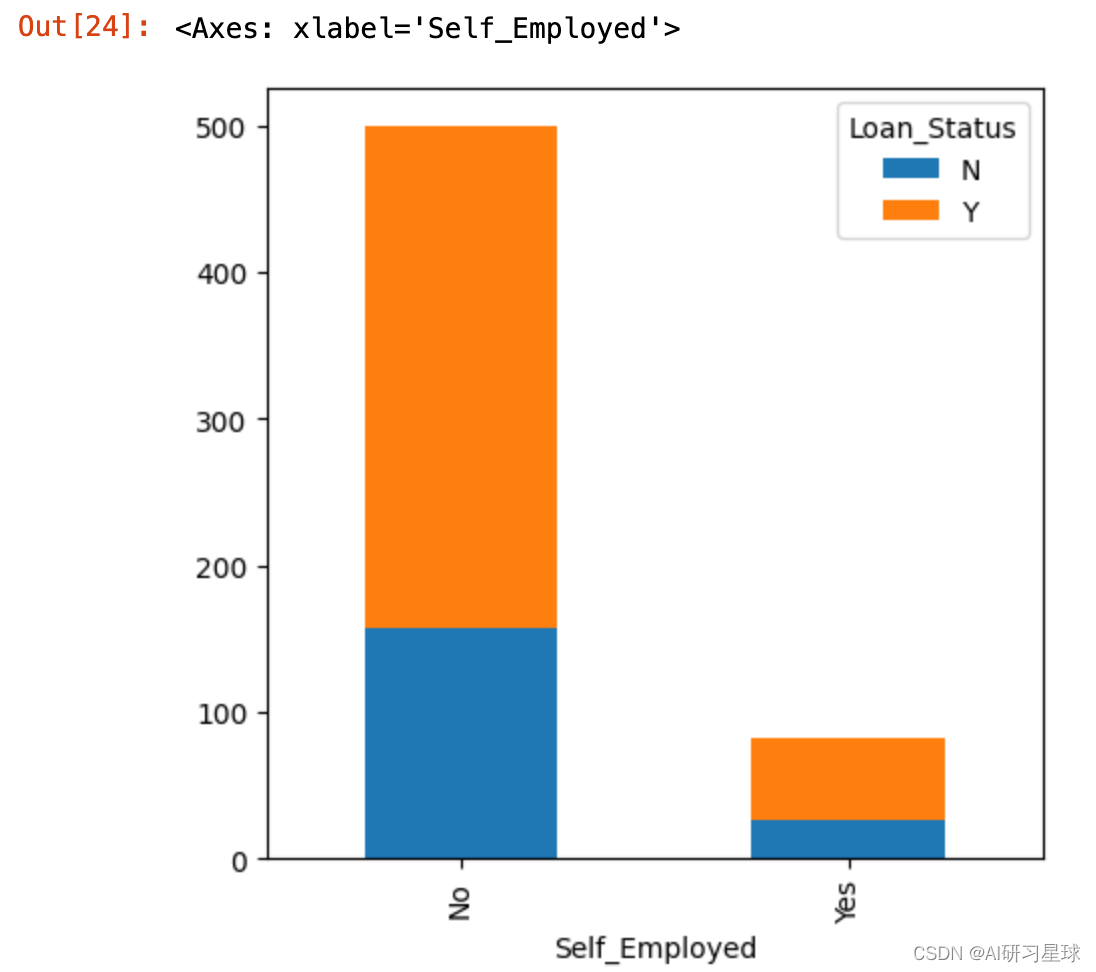
结论:不是自雇客户申请通过的最高。
3.6 信用记录与贷款之间的关系
Credit_History=pd.crosstab(full_data['Credit_History'],full_data['Loan_Status'])
Credit_History.plot(kind="bar", stacked=True, figsize=(5,5))
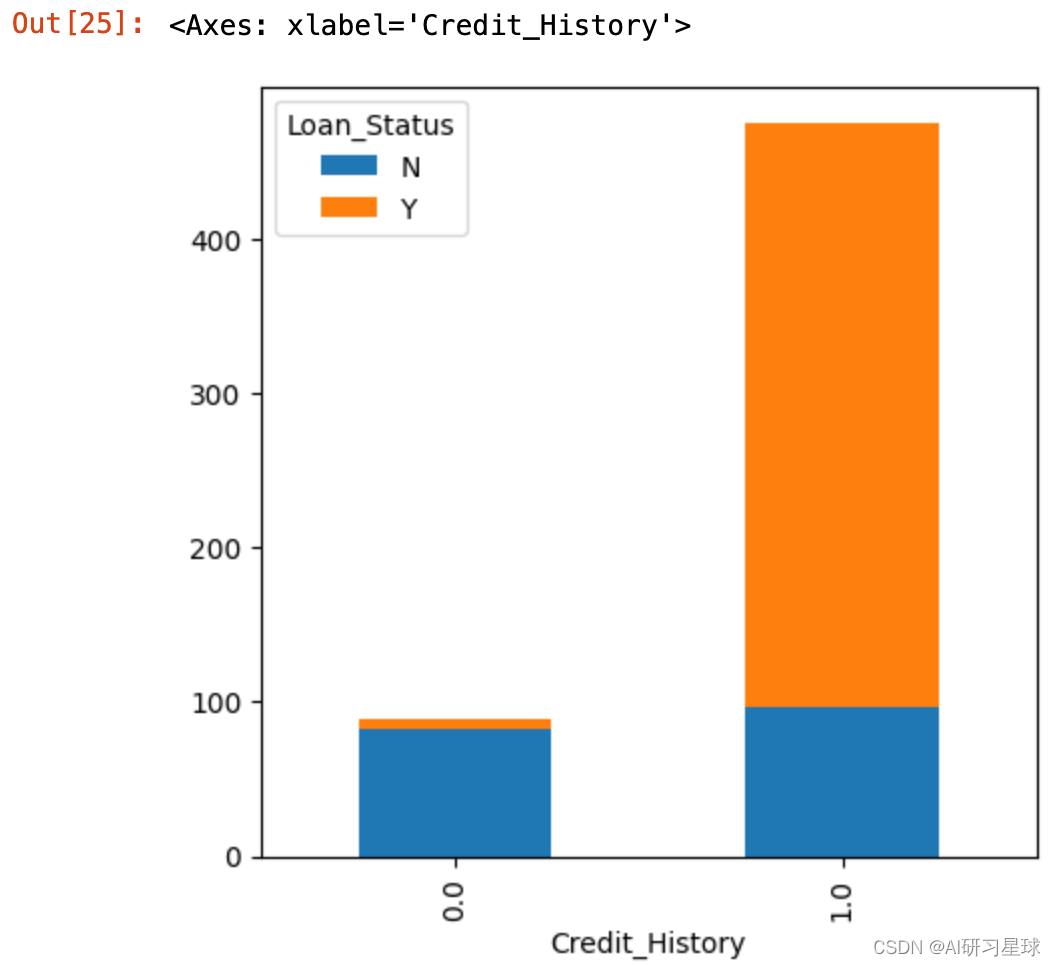
结论:信用记录为1的人更有可能获得贷款批准,说明有信用的获得贷款的机会大。
3.7 区域与贷款关系
Property_Area=pd.crosstab(full_data['Property_Area'],full_data['Loan_Status'])
Property_Area.plot(kind="bar", stacked=True, figsize=(5,5))
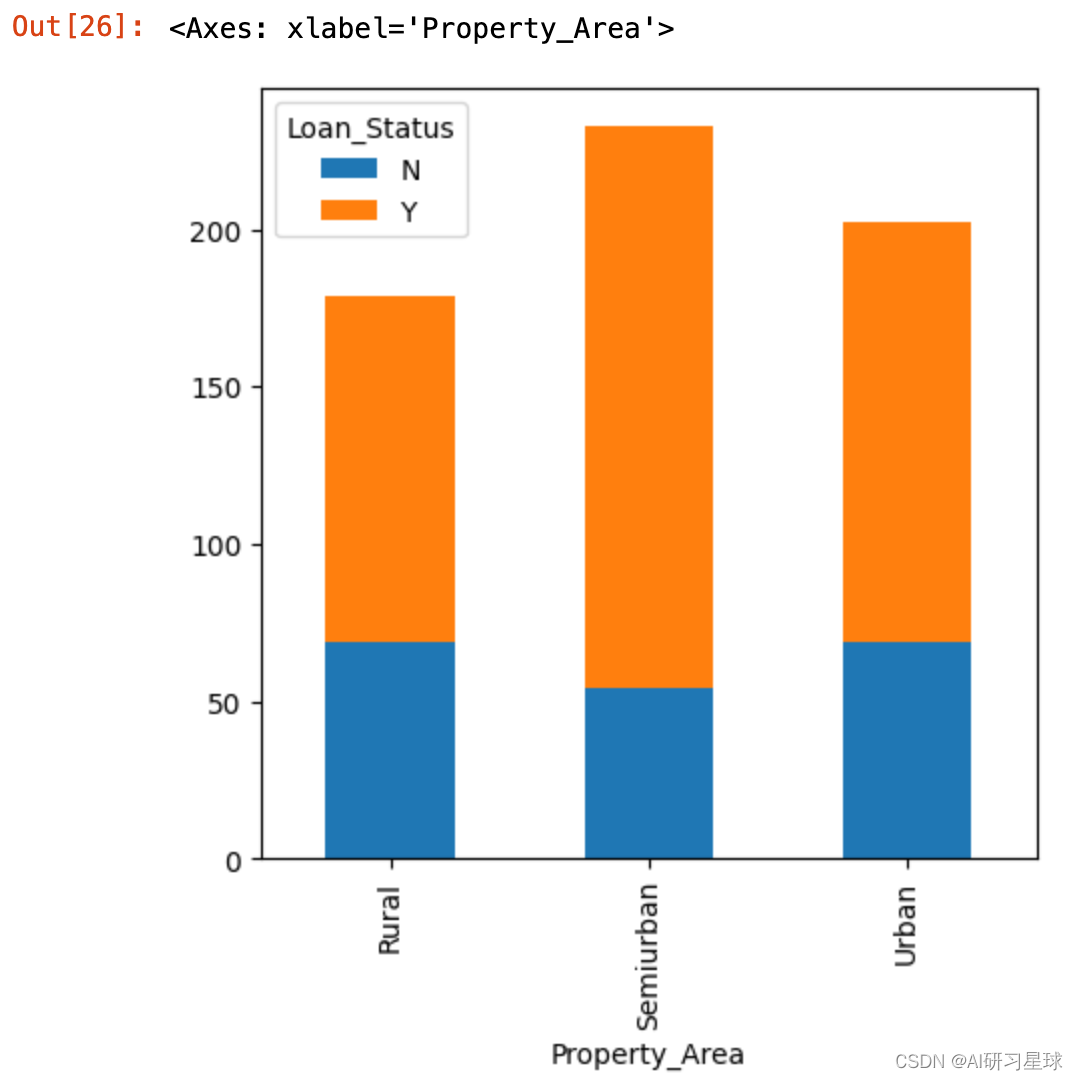
结论:在半城市区获得批准的贷款要高于农村或城市地区
4. 热图来可视化相关性
用于查看所有数值变量之间的相关性。
首先将类别特征值转为数值型,方便热图分析相关性
将dependents变量中的3+更改为3以使其成为数值变量。我们还将目标变量的类别转换为0和1,以便我们可以找到它与数值变量的相关性。
full_data['Gender'].replace(('Female','Male'),(0,1),inplace=True)
full_data['Married'].replace(('NO','Yes'),(0,1),inplace=True)
full_data['Dependents'].replace(('0', '1', '2', '3+'),(0, 1, 2, 3),inplace=True)
full_data['Education'].replace(('Not Graduate', 'Graduate'),(0, 1),inplace=True)
full_data['Self_Employed'].replace(('No','Yes'),(0,1),inplace=True)
full_data['Property_Area'].replace(('Semiurban','Urban','Rural'),(0,1,2),inplace=True)
通过着色的变化来显示数据。颜色较深的变量意味着它们的相关性更高。
matrix = full_data.corr()
f, ax = plt.subplots(figsize=(8, 8))
sns.heatmap(matrix,vmax=.8, square=True,cmap="BuPu",annot=True);
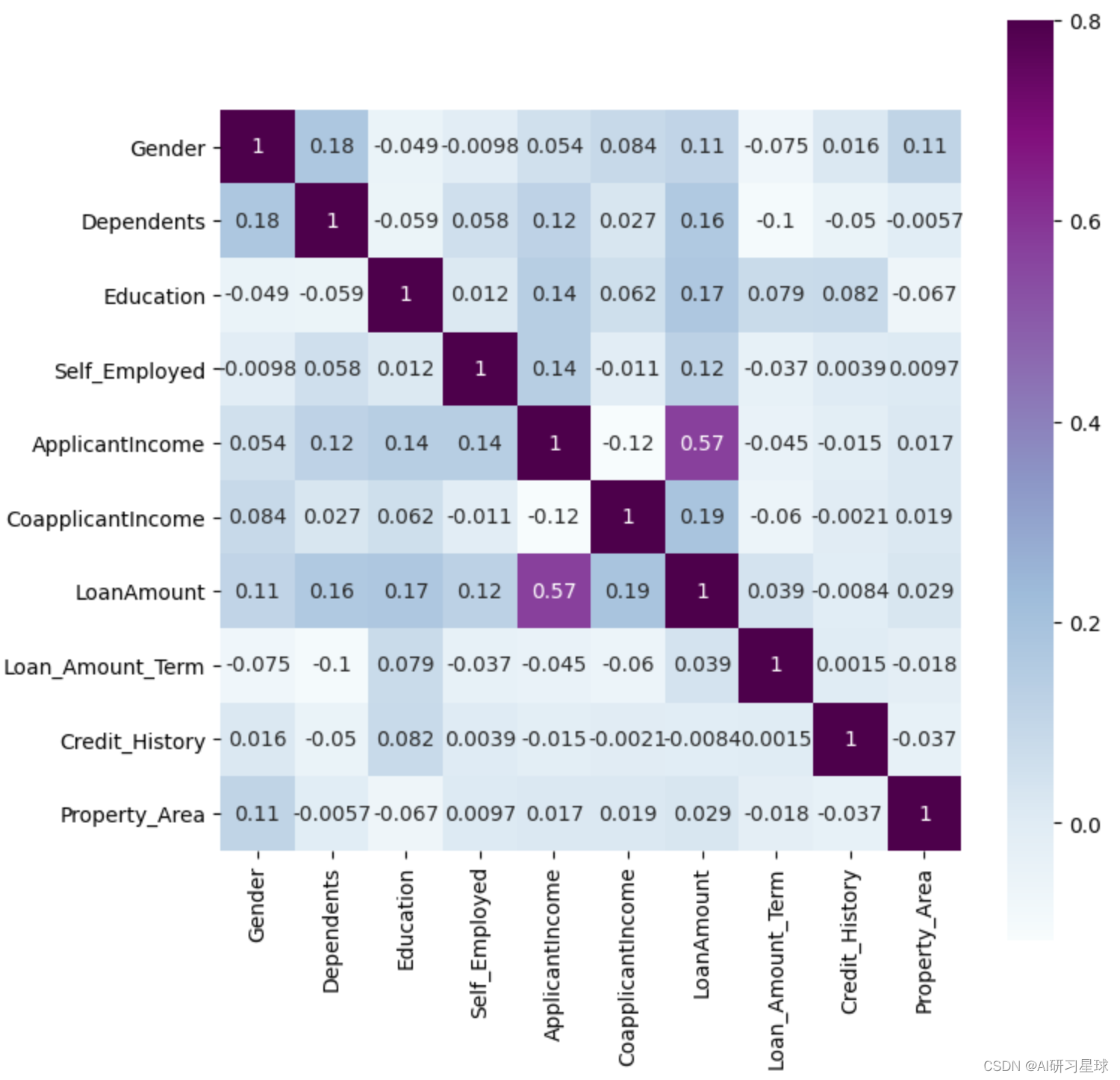
结论:可以看到最相关的变量是(ApplicantIncome - LoanAmount)和(Credit_History - Loan_Status),这两者相关性强。
LoanAmount也与CoapplicantIncome相关。说明申请人的收入和贷款金额、信用历史记录与贷款状态有很强的关系
5. 缺失值和异常值的处理
连续变量特征分析是否有异常值
5.1 数据分析
5.1.1 申请人收入数据分析
plt.figure()
plt.subplot(121)
sns.distplot(full_data['ApplicantIncome']);
plt.subplot(122)
full_data['ApplicantIncome'].plot.box(figsize=(16,5))
plt.show()
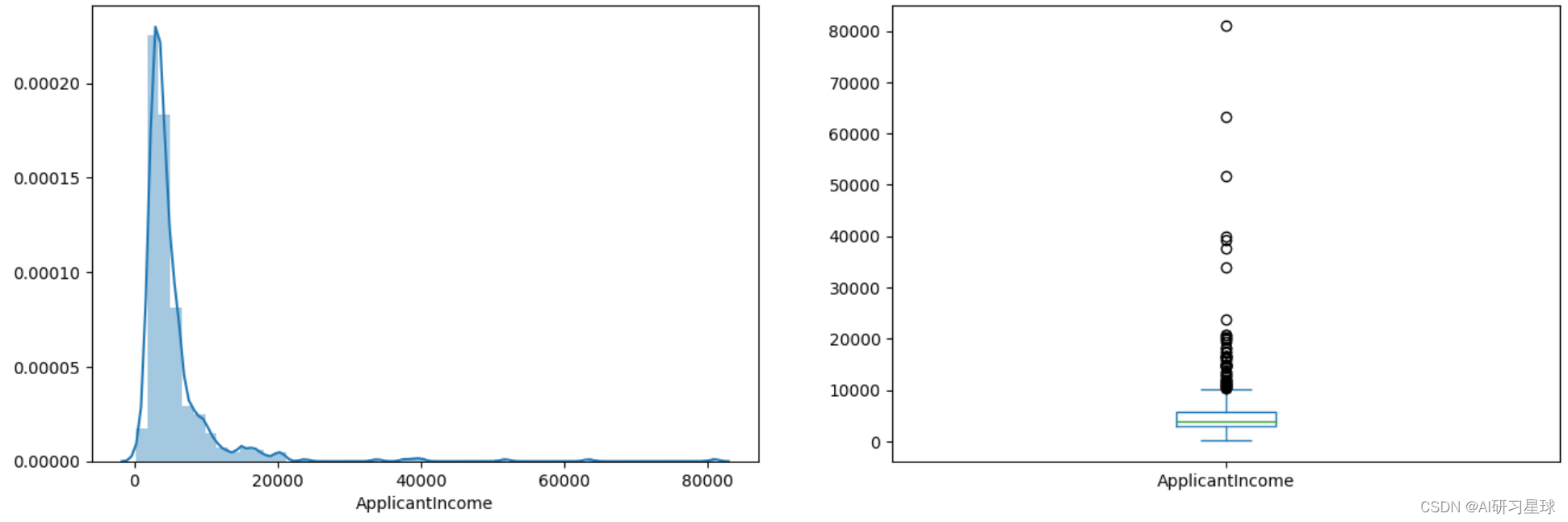
结论:收入分配的大部分数据主要偏在左边,没有呈现正态分布,箱线图确认存在大量异常值,收入差距较大,需要进行处理。
5.1.2 按教育分开绘制
full_data.boxplot(column='ApplicantIncome', by = 'Education')
plt.suptitle("")
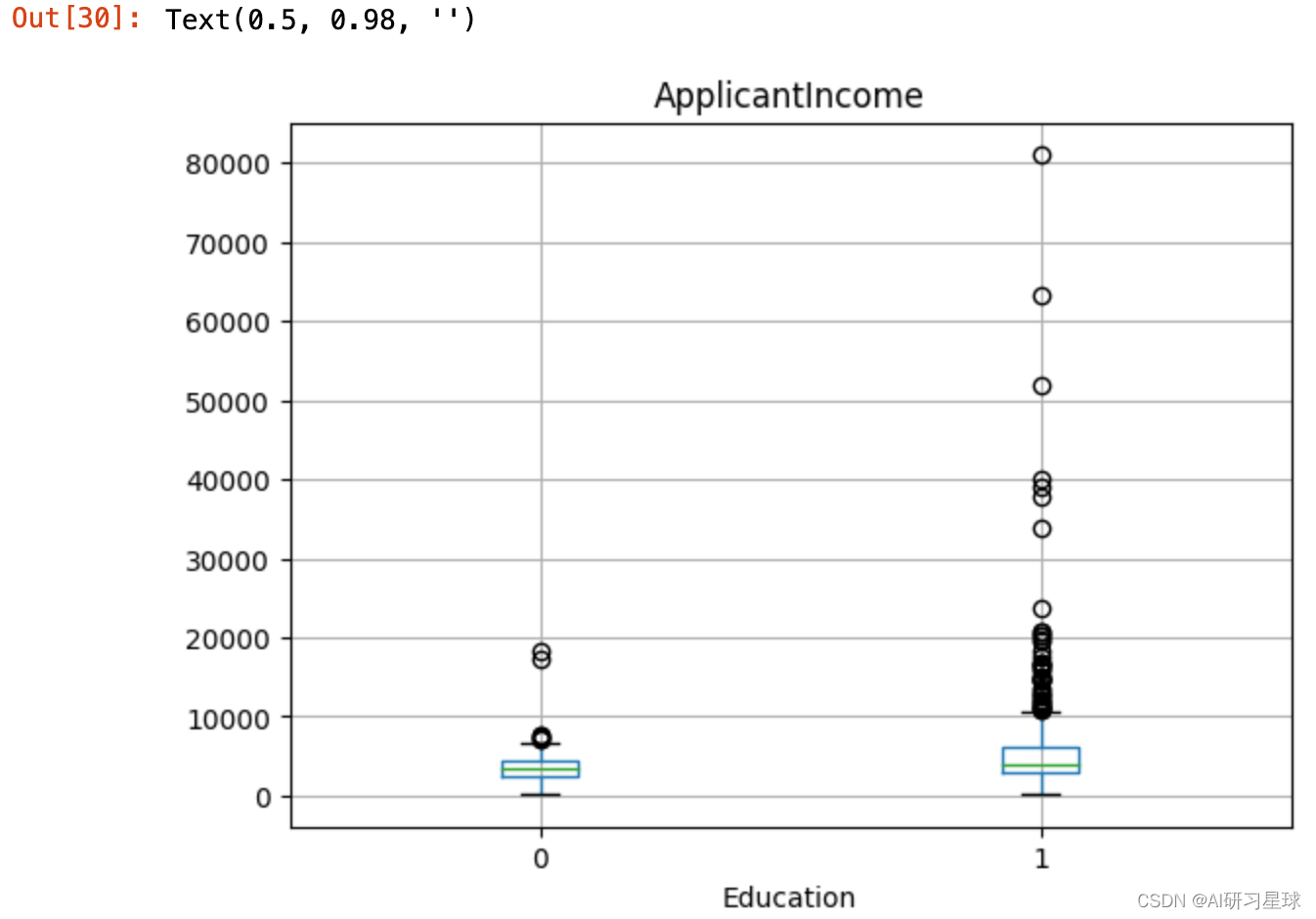
结论:可以看到受教育的人,有很多的高收入,出现异常值。
5.1.3 贷款额度关系
plt.figure(1)
plt.subplot(121)
df=full_data.dropna()
sns.distplot(df['LoanAmount']);
plt.subplot(122)
full_data['LoanAmount'].plot.box(figsize=(16,5))
plt.show()
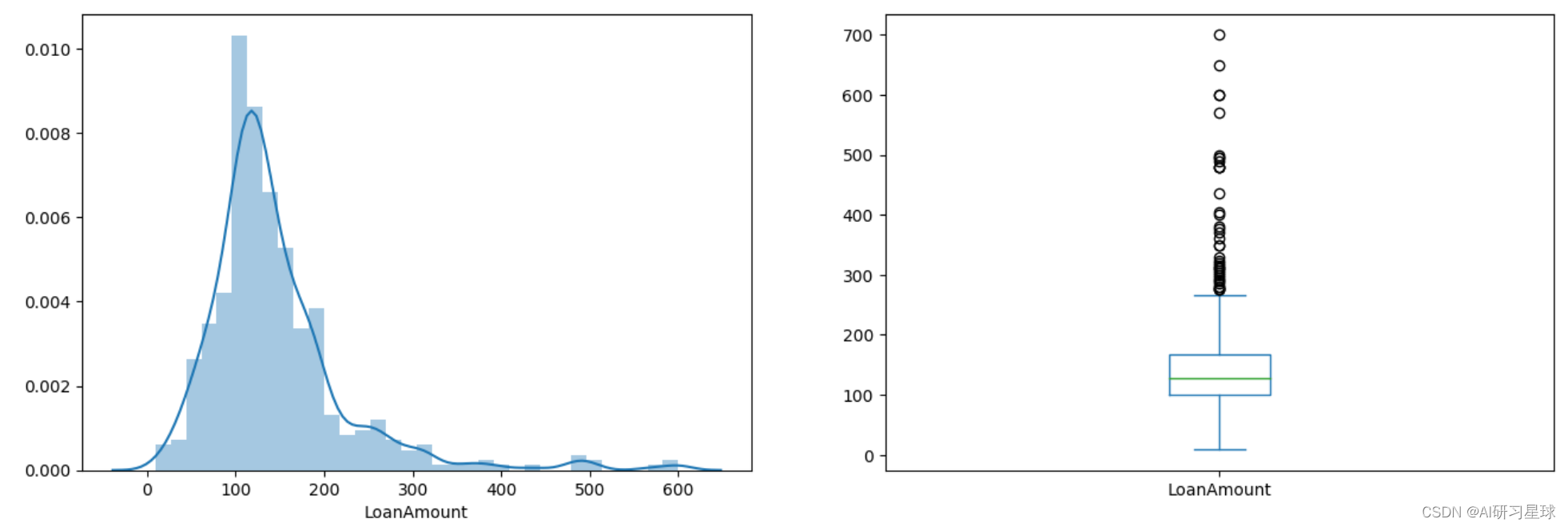
结论:贷款额度数呈现正态分布,但是从箱线图中看到出现很多的异常值,需要进行处理异常值。
5.2 处理缺失值
5.2.1 查看有多少缺失值
full_data.isnull().sum()

Gender,Married,Dependents,Self_Employed,LoanAmount,Loan_Amount_Term和Credit_History等变量特征存在缺少值。
5.2.2 填充缺失的值的方法
对于数值变量:使用均值或中位数进行插补
对于分类变量:使用常见众数进行插补,这里主要使用众数进行插补空值
full_data['Gender'].fillna(full_data['Gender'].value_counts().idxmax(), inplace=True)
full_data['Married'].fillna(full_data['Married'].value_counts().idxmax(), inplace=True)
full_data['Dependents'].fillna(full_data['Dependents'].value_counts().idxmax(), inplace=True)
full_data['Self_Employed'].fillna(full_data['Self_Employed'].value_counts().idxmax(), inplace=True)
full_data["LoanAmount"].fillna(full_data["LoanAmount"].mean(skipna=True), inplace=True)
full_data['Loan_Amount_Term'].fillna(full_data['Loan_Amount_Term'].value_counts().idxmax(), inplace=True)
full_data['Credit_History'].fillna(full_data['Credit_History'].value_counts().idxmax(), inplace=True)
再次查看是否存在缺失值
full_data.info()
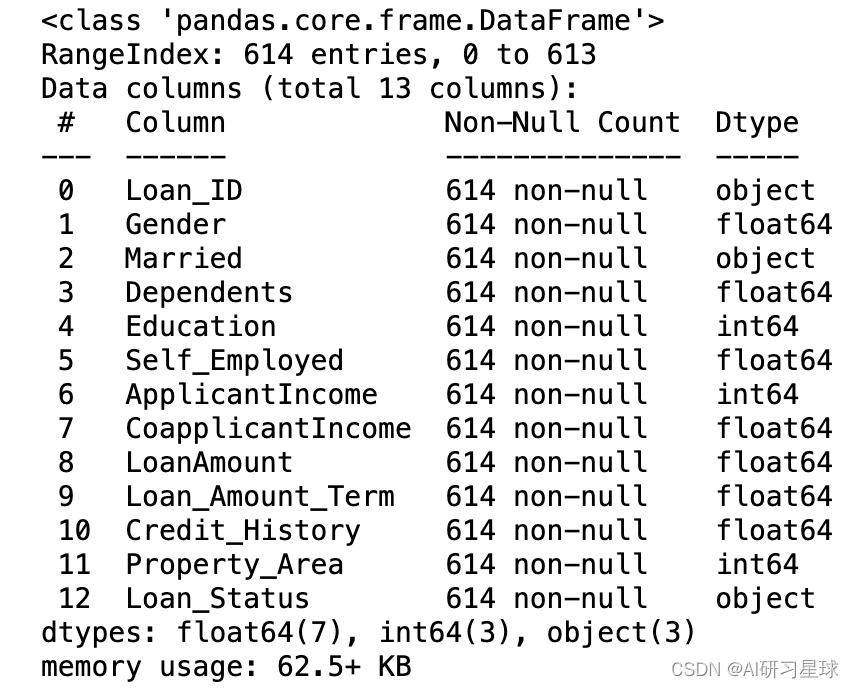
可以看到数据集中已填充所有缺失值,没有缺失值存在。
异常值处理:
对于异常值需要进行处理,这里采用对数log转化处理,消除异常值的影响,让数据回归正态分布
5.2.2.1 LoanAmount异常值处理
full_data['LoanAmount_log'] = np.log(full_data['LoanAmount'])
full_data['LoanAmount_log'].hist(bins=20)
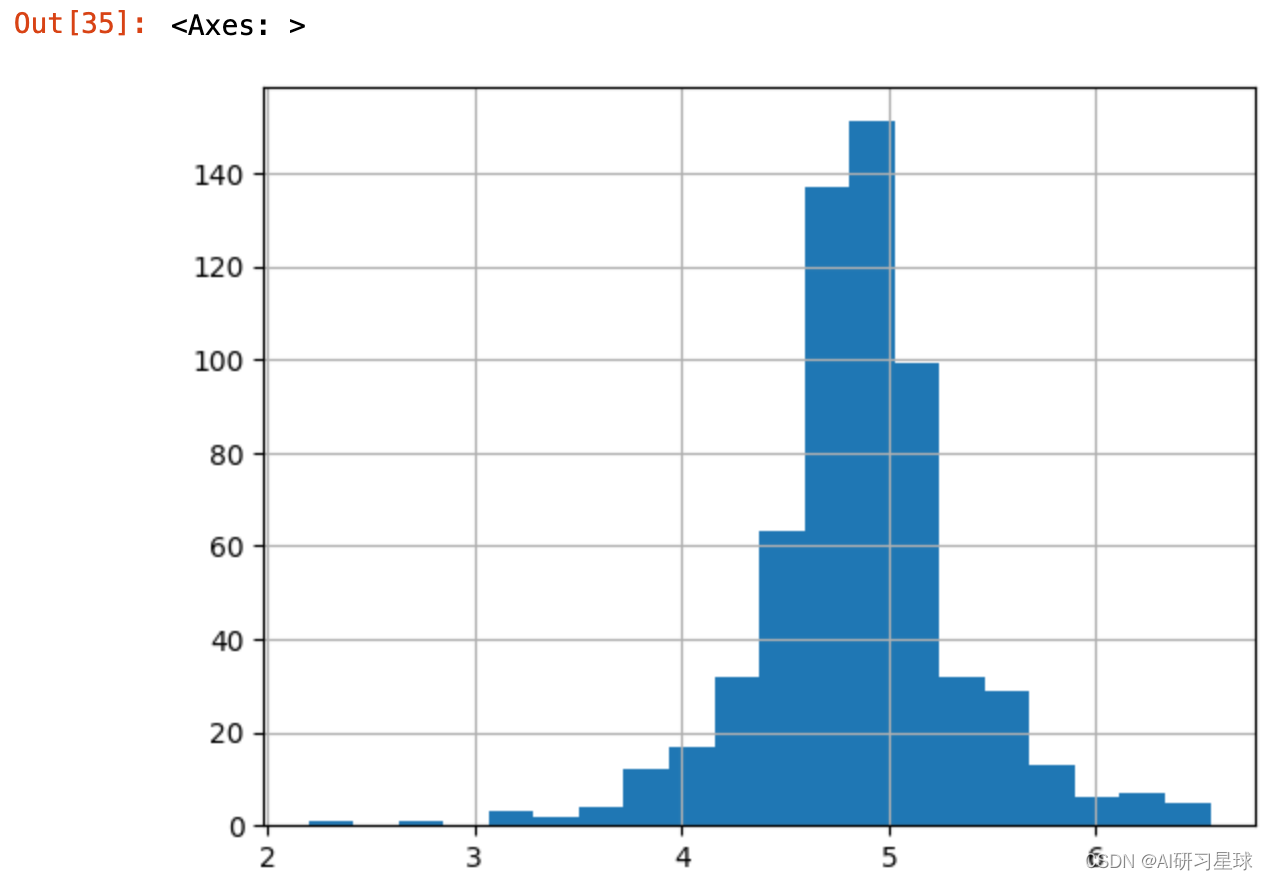
5.2.2.2 ApplicatIncome异常值处理
full_data['ApplicantIncomeLog'] = np.log(full_data['ApplicantIncome'])
full_data['ApplicantIncomeLog'].hist(bins=20)
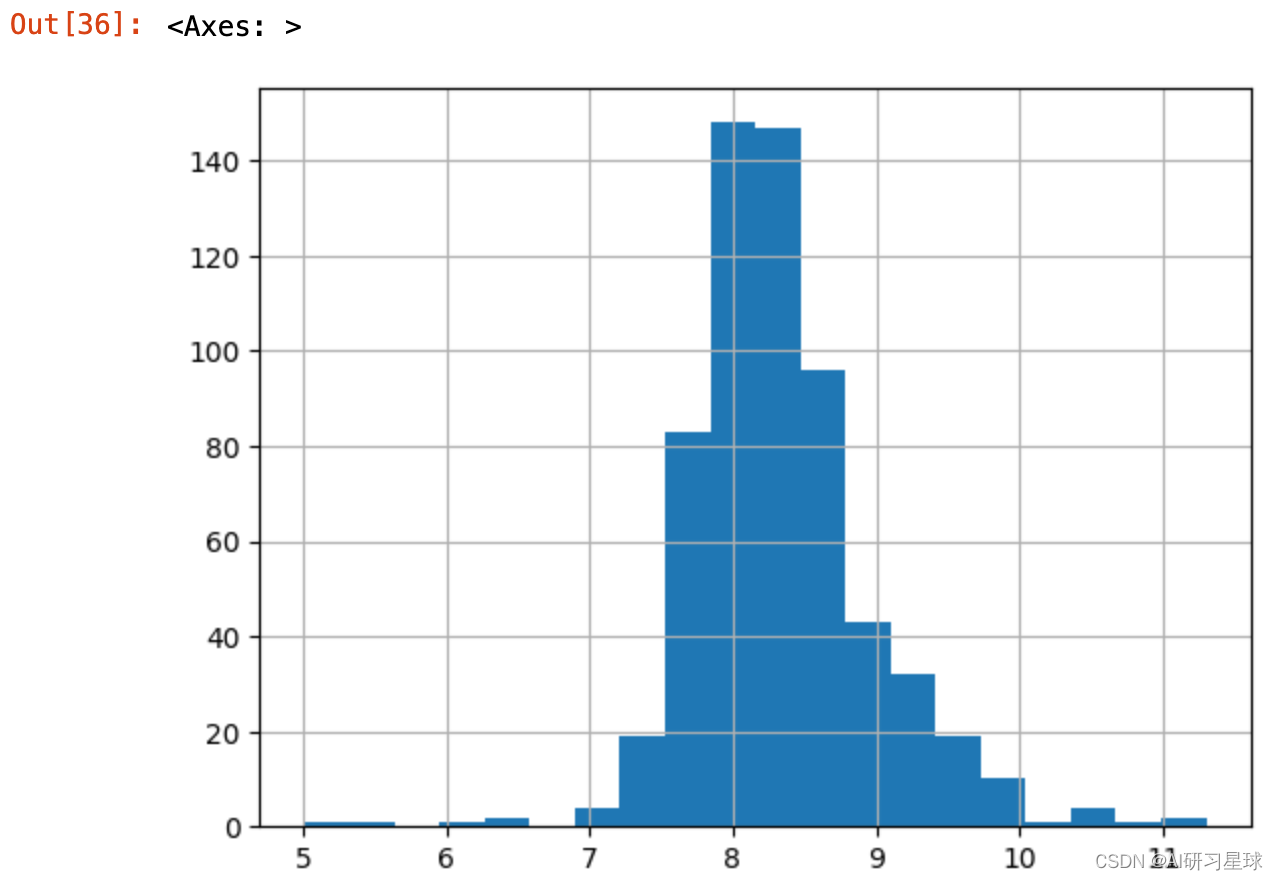
异常值处理完成,接下来构建模型预测准确率
6. 构建模型(逻辑回归模型)
6.1 Loan_ID变量对贷款状态没有影响,需要删除更改
full_data=full_data.drop('Loan_ID',axis=1)
6.2 删除目标变量Loan_Status,并将它保存在另一个数据集中
X = full_data.drop('Loan_Status',1)
y = full_data.Loan_Status
X=pd.get_dummies(X)
full_data=pd.get_dummies(full_data)
6.3 导入导入train_test_split
from sklearn.model_selection import train_test_split
#建立训练集合测试集
x_train, x_cv, y_train, y_cv = train_test_split(X,y, test_size =0.3)
从sklearn导入LogisticRegression和accuracy_score并拟合逻辑回归模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
6.4 创建模型逻辑回归和训练模型
model = LogisticRegression()
model.fit(x_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
6.5 评估预测模型
pred_cv = model.predict(x_cv)
accuracy_score(y_cv,pred_cv)
0.8216216216216217
关注公众号:『AI学习星球』
回复:贷款预言 即可获取数据下载。
论文辅导或算法学习可以通过公众号滴滴我
















 7873
7873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









