







 本文详细介绍了使用Python对givemesomecredit数据集进行数据清洗,包括选择子集、列名重命名、缺失值和异常值处理。通过分析借款人的逾期情况、月收入分布和年龄对违约率的影响,展示了信用风险管理在互联网金融中的应用。
本文详细介绍了使用Python对givemesomecredit数据集进行数据清洗,包括选择子集、列名重命名、缺失值和异常值处理。通过分析借款人的逾期情况、月收入分布和年龄对违约率的影响,展示了信用风险管理在互联网金融中的应用。
文章目录
互联网金融飞速发展,使得个人金融理财变得越来越容易。根据《消费金融创新报告》,中国消费信贷的规模到2020会超过12万亿,以至于网络环境下信用风险管理变得越来越重要。
但本篇的重点为利用python对数据进行清洗及简单的分析,熟悉数据清洗的步骤和思路,数据建模部分放在机器学习中。
0. 数据代码下载
算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
1. 分析思路
数据分析的步骤如下
提出问题 -> 理解数据 -> 数据清洗 -> 构建模型 -> 数据可视化
提出问题:提供后续分析的目标和方向
- 借款人数逾期超过90天数目,即借款客户的整体质量情况?
- 借款人月收入分布情况?
- 年龄对违约率的影响?
2. 理解数据
give me some credit 数据集分为训练集和测试集,目的是开发一个申请的评分卡模型,对未来一段时间内借贷人出现违约的概率进行预测,对客户信用进行评估打分。在前文已说,本篇重点放在数据清洗及简单分析上,评分卡构建后期会写一篇文章。
训练集样本数据一共150000条,10个自变量,1个因变量(SeriousDlqin2yrs)。具体情况如下:
| 变量名称 | 描述 | 数据类型 |
|---|---|---|
| SeriousDlqin2yrs | 是否有超过90天或更长时间逾期未还的不良行为 | Y/N |
| RevolvingUtilizationOfUnsecuredLines | 贷款以及信用卡可用额度与总额度比例。信用卡总余额和个人信用额度(除了房地产和分期付款给债务,比如汽车贷款)除以总信用限制 | percentage |
| age | 借款人年龄 | integer |
| NumberOfTime30-59DaysPastDueNotWorse | 逾期天数在35~59内,但不糟糕次数 | integer |
| DebtRatio | 负债比率:月债务支出、赡养费、生活费除以总收入(毛收入) | percentage |
| MonthlyIncome | 月收入 | integer |
| NumberOfOpenCreditLinesAndLoans | 开放式贷款(分期付款如汽车贷款或抵押贷款)和信贷(如信用卡)的数量 | integer |
| NumberOfTimes90DaysLate | 90天逾期次数:借款者有90天或更高逾期的次数 | integer |
| NumberRealEstateLoansOrLines | 不动产贷款或额度数量:抵押和房地产数量(包括房屋净值信用额度) | integer |
| NumberOfTime60-89DaysPastDueNotWorse | 60-89天逾期但不糟糕次数:借款人在在过去两年内有60-89天逾期还款但不糟糕的次数 | integer |
| NumberOfDependents | 家属数量(不包括借款人自己) | integer |
根据数据集中的变量,可将这些变量进行分类,有助于加深对变量的理解。大致可以分为以下几个维度:
- 人口统计信息:借款人年龄、家庭成员数量
- 信用历史纪录:两年内35-59天逾期次数、两年内60-89天逾期次数、两年内90天或高于90天逾期次数
- 偿债能力:负债比率、月收入、贷款数量、不安全额度循环利用、不动产贷款或额度数量
3. 数据清洗
原始数据信息一般比较冗杂,我们需要把脏东西清洗掉,才能从数据集中挖掘出有用的信息。而数据清洗过程比较繁琐,一般占据了我们整个工作量的60%,所以,需要我们仔细认真的完成这一步骤。
数据清洗过程大致包含:选择子集、列名重命名、缺失数据处理、数据类型转换、数据排序、异常值处理。可以根据你所分析的问题,进行相应的调整。
3.1 选择子集
有时原始数据太大,里面包含很多我们不需要的信息,这时我们可以通过选择子集操作(比如切片)选择其中一部分数据作为分析的对象。本篇数据只有一列为无关数据,删除即可。
import pandas as pd
dat=pd.read_csv("cs-training.csv")
dat.drop(dat.iloc[:,:1],inplace=True,axis=1)
3.2 列名重命名
可以根据自己对数据的理解,对列名重命名。本篇所用数据的变量名就较长,不便分析。
colNameDict=({'SeriousDlqin2yrs':'bad_debt',
'RevolvingUtilizationOfUnsecuredLines':'bad_cycle_rate',
'NumberOfTime30-59DaysPastDueNotWorse':'30_59',
'MonthlyIncome':'m_income',
'NumberOfOpenCreditLinesAndLoans':'num_open',
'NumberOfTimes90DaysLate':'90_',
'NumberRealEstateLoansOrLines':'num_estate',
'NumberOfTime60-89DaysPastDueNotWorse':'60_89',
'NumberOfDependents':'dependents'})
dat.rename(columns=colNameDict,inplace=True)
3.3 缺失数据处理
可以查看数据集的基本情况,对缺失值有个初步的判断。
dat.info()
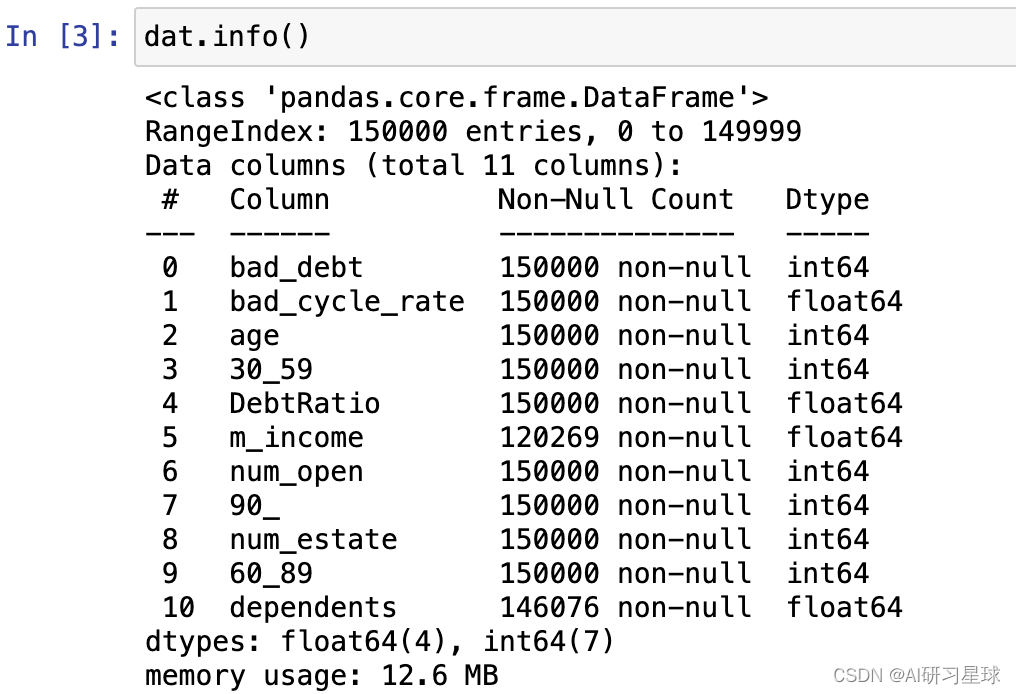
初步判断,m_income和dependents存在缺失值。
处理缺失值的方法:
- 删除缺失值(缺失值较少);
- 插值,插值可以用均值、中位数等直接替换或建立模型(缺失值较多);
m_income缺失值处理
m_income这一变量,缺失值较多且对目标变量影响较大,不能暴力删除,故采用插值法填充缺失值。由于月收入这一变量呈正态分布,因此用中位数去填充他的缺失值。
m_median=dat.m_income.median()
dat.m_income.fillna(m_median,inplace=True)
dependents缺失值处理
dependents缺失值较少,删除后对目标变量影响不大,因此采用删除缺失值的办法。缺失值处理后,用drop_duplicates()删除重复项。
dat=dat.dropna()
dat.info()
dat=dat.drop_duplicates()
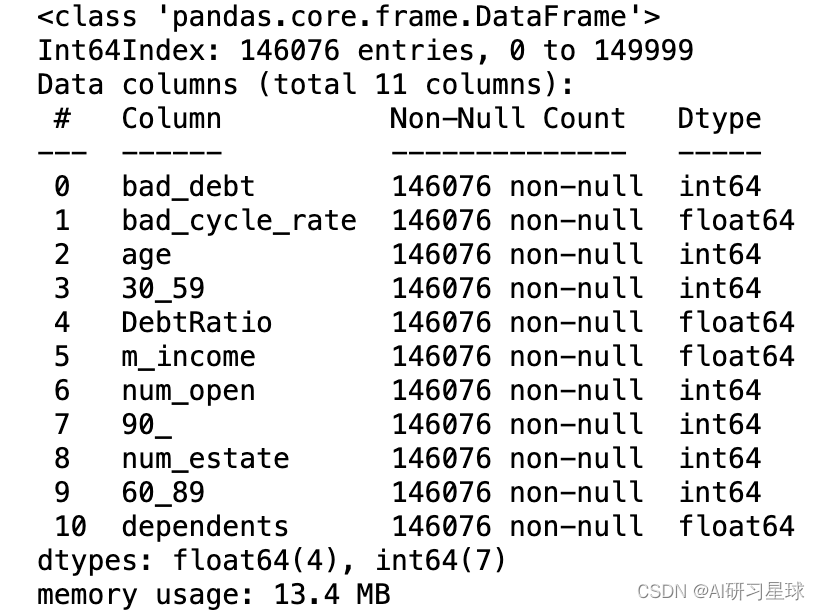
3.4 异常值处理
异常值是指明显偏离大多数抽样数据的数值。一般的检测方法有单变量异常值检测,可以通过箱线图来查看;局部异常因子检测;基于聚类方法的异常值检测,通过把数据聚成类,将那些不属于任务一类的数据作为异常值。比如,使用k-means算法来检测异常。
首先我们可以通过describe()获取数据框中每列描述统计信息,从整体上了解到数据集的情况。
dat.describe()
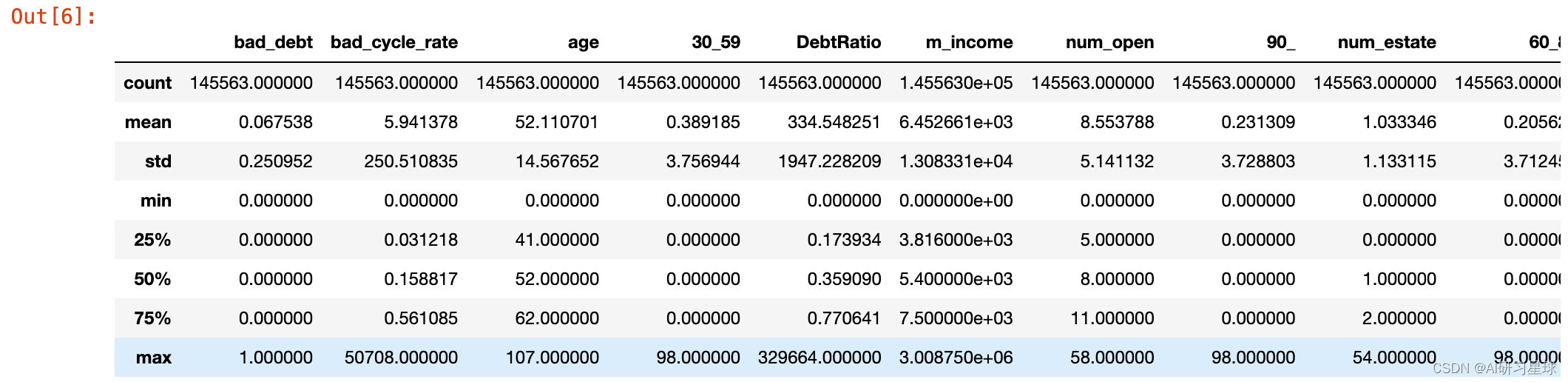
从上图我们可以看出,age的最小值为0,不符合实情,存在异常值;
age异常值处理
dat=dat[(dat['age']>0]
30_59、90_、60_89 异常值处理
这里我们使用箱线图来查看三个时间值是否存在异常值,
import matplotlib.pyplot as plt
dat_list=dat[['30_59','90_','60_89']]
dat_list.boxplot()
plt.show()
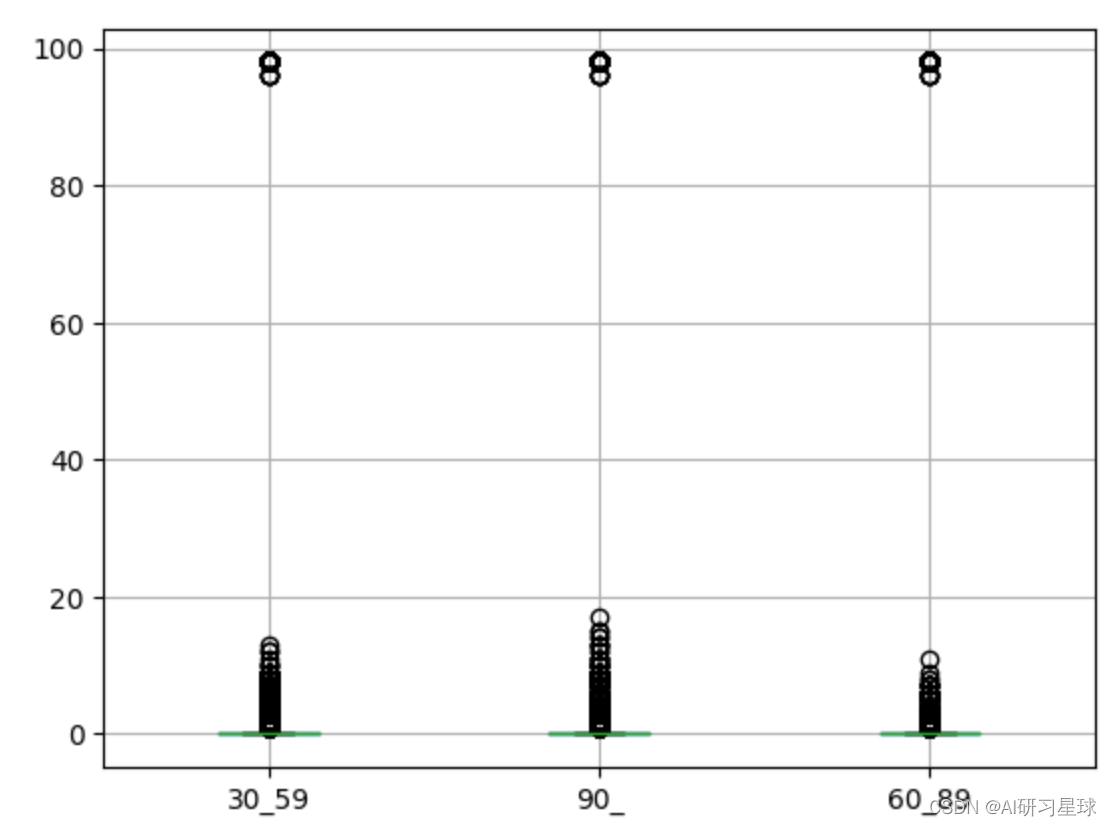
可以看到这三个变量均有异常值,将高于90的记录删除即可;
dat=dat[dat['30_59']<90]
dat=dat[dat['60_89']<90]
dat=dat[dat['90_']<90]
4. 建立模型
通过数据清洗后,得到了有用的数据。接下来,针对提出的问题,即分析的目的来构建模型。
4.1 借款逾期超过90天的人数,即借款客户的整体质量情况?
grouped=dat['bad_debt'].groupby(dat['bad_debt']).count()
print("坏客户占比:{:.2%}".format(grouped[1]/dat.shape[0]))
grouped.plot(kind='bar')
plt.show()
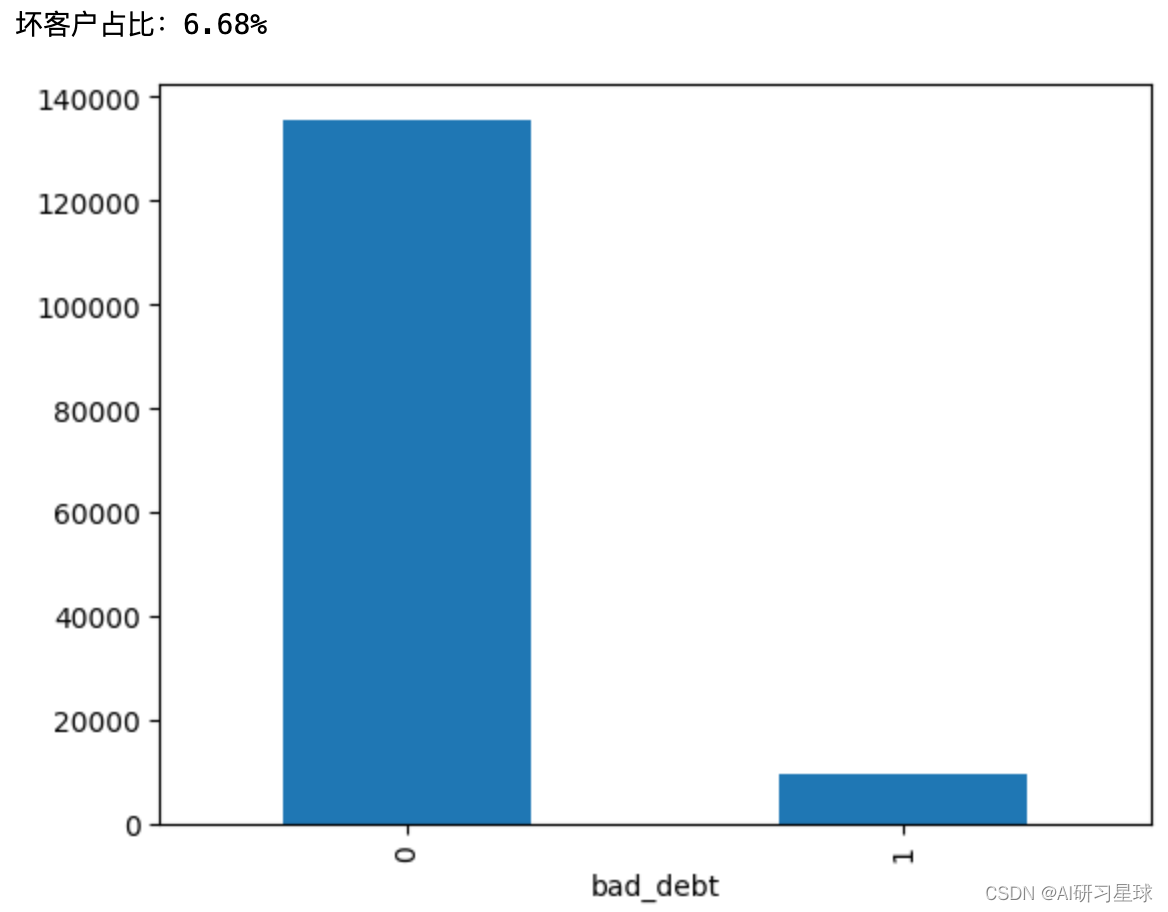
其中,1表示借款逾期超过90天,0代表逾期未超过90天。
从结果来看,逾期数目大致占6.7%,此外,该数据集是非平衡的数据集。
4.2 借款人月收入分布情况及月收入对违约客户数量的影响?
#生成频率表
dat_df=dat[['m_income','bad_debt']]
#利用cut函数,将连续变量转为分类变量
def dy_zh(col, cut_points, labels=None):
min_num = col.min()
max_num = col.max()
break_points = [min_num] + cut_points + [max_num]
if not labels:
labels = range(len(cut_points)+1)
else:
labels=[str(i+1)+":"+labels[i] for i in range(len(cut_points)+1)]
colBin = pd.cut(col,bins=break_points,
labels=labels,include_lowest=True)
return colBin
cut_points = [5000,10000,15000]
labels=['below 5000', '5000-10000','1000-15000','above 15000']
#调用函数dy_zh,增加新列
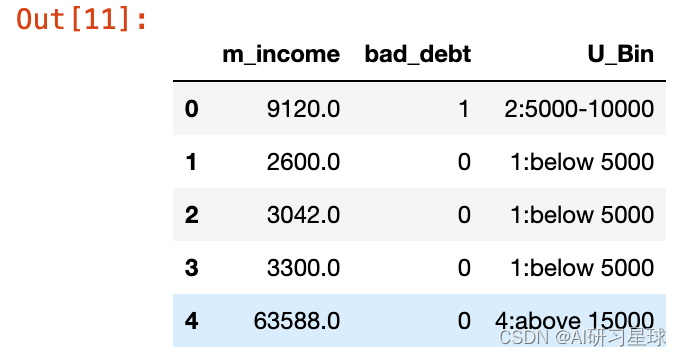
dat_df['U_Bin'] = dy_zh(dat_df['m_income'], cut_points, labels)
#查看标签列,取值范围前面加上了序号,是便于后面生成表格时按顺序排列
dat_df.head()
#计算各个区间内违约人数所占比例
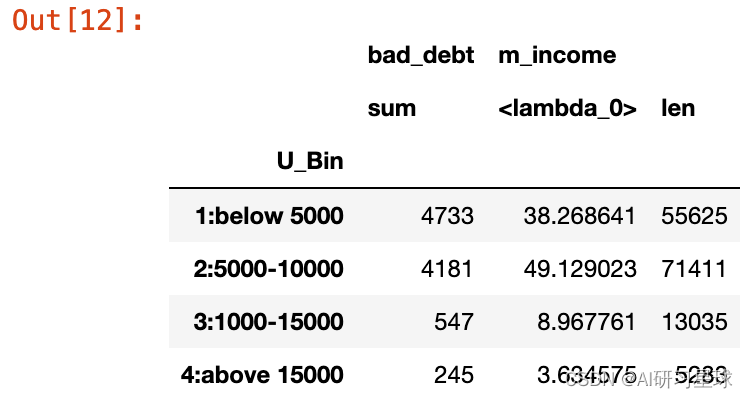
import numpy as np
total_num=dat_df.shape[0]
#使用pandas的pivot_table函数生成汇总表
per_table=pd.pivot_table(dat_df,index=['U_Bin'],
aggfunc={"m_income":[len, lambda x:len(x)/total_num *100],
"bad_debt":[np.sum] },
values=['m_income','bad_debt'])
per_table
#增加percent列,它的值来自另外两列数值之比
per_table['bad_debt','percent']=per_table['bad_debt','sum']/ per_table['m_income','len']*100
per_table
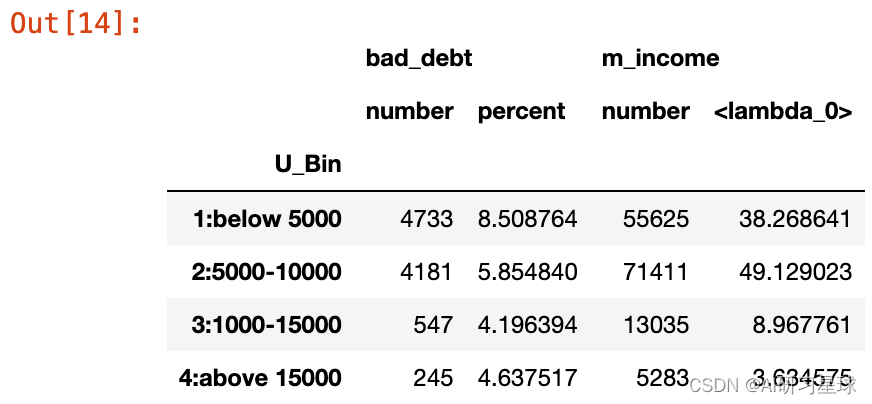
从结果,我们可以看出借款人大部分集中在月收入10000以内之间,特别是5000~10000这一区间,基数较大。说明这部分人群可支配收入不多,依靠借贷填补支出。
此外,坏账率在月收入在低于5000时最高,收入越高违约的可能性越低。
4.3 年龄对违约率的影响?
依旧跟月收入一样,生成年龄频率表。只需换几行代码就行,原理是一样的。其实,可以直接写一个频率函数,方便直接调用。
dat_df=dat[['age','bad_debt']]
cut_points=[25,35,45,55,65]
labels=['below25', '26-35', '36-45','46-55','56-65','above65']
dat_df['U_Bin'] = dy_zh(dat_df['age'], cut_points, labels)
dat_df.head()
#计算各个区间内违约人数所占比例
import numpy as np
total_num=dat_df.shape[0]
per_table=pd.pivot_table(dat_df,index=['U_Bin'],
aggfunc={"age":[len, lambda x:len(x)/total_num *100],
"bad_debt":[np.sum] },
values=['age','bad_debt'])
per_table['bad_debt','percent']=per_table['bad_debt','sum']/per_table['age','len']*100
per_table

#列名重命名
per_table=per_table.rename(columns={'<lambda>':'percent','len': 'number','sum':'number'})
per_table=per_table.reindex((per_table.columns[0],per_table.columns[1],per_table.columns[2],per_table.columns[3]),axis=1)
per_table
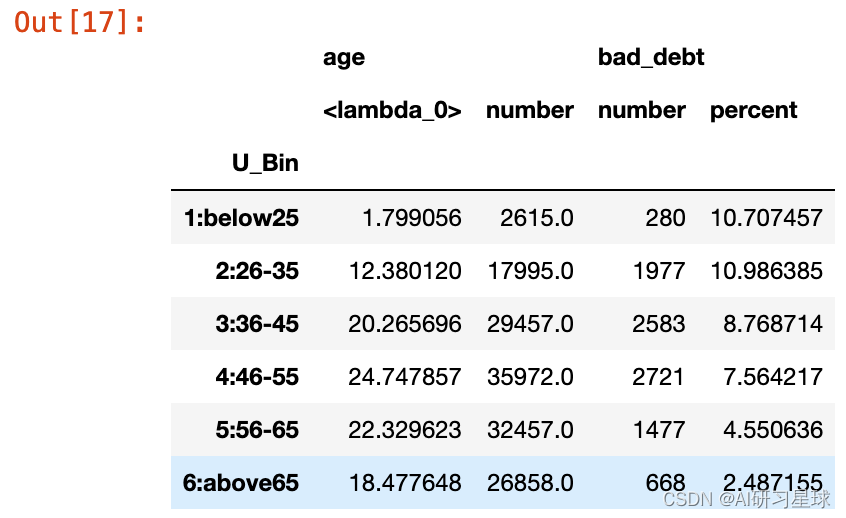
从结果来看,借款者 中年人居多。这部分人群生活压力较大,家里有老人和小孩要抚养,借款需求较大。此外,小于25岁的人群和26-35岁的人群,违约率都超过10%。随着年龄增加,违约率在下降。



















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











