







算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
一、项目背景
通过分析口味、环境、服务评分以及人均消费等数据,来深入了解上海餐饮业的顾客满意度情况。
二、数据说明
该数据共96398条,字段共10个。字段分别是:
| 列名 | 说明 |
|---|---|
| 类别 | 餐饮店的类型,如烧烤、美食、粤菜、海鲜等 |
| 行政区 | 餐饮店所在的行政区,如浦东新区、闵行区等 |
| 点评数 | 该餐饮店的点评数量 |
| 口味 | 顾客对餐饮店口味评分的平均值 |
| 环境 | 顾客对餐饮店环境评分的平均值 |
| 服务 | 顾客对餐饮店服务评分的平均值 |
| 人均消费 | 顾客在该餐饮店的平均消费金额 |
| 城市 | 餐饮店所在的城市 |
| Lng | 餐饮店的经度位置 |
| Lat | 餐饮店的纬度位置 |
以下是表的部分数据:
三、数据分析
1、导入包及其加载数据
导入包
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
关闭warn及其Matplotlib的中文设置
import warnings
warnings.filterwarnings('ignore')
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"] # 设置显示中文字体 宋体
mpl.rcParams["axes.unicode_minus"] = False #字体更改后,会导致坐标轴中的部分字符无法正常显示,此时需要设置正常显示负号
file_path = '上海餐饮数据.csv'
df = pd.read_csv(file_path)
df.head()
2、总体评分分析
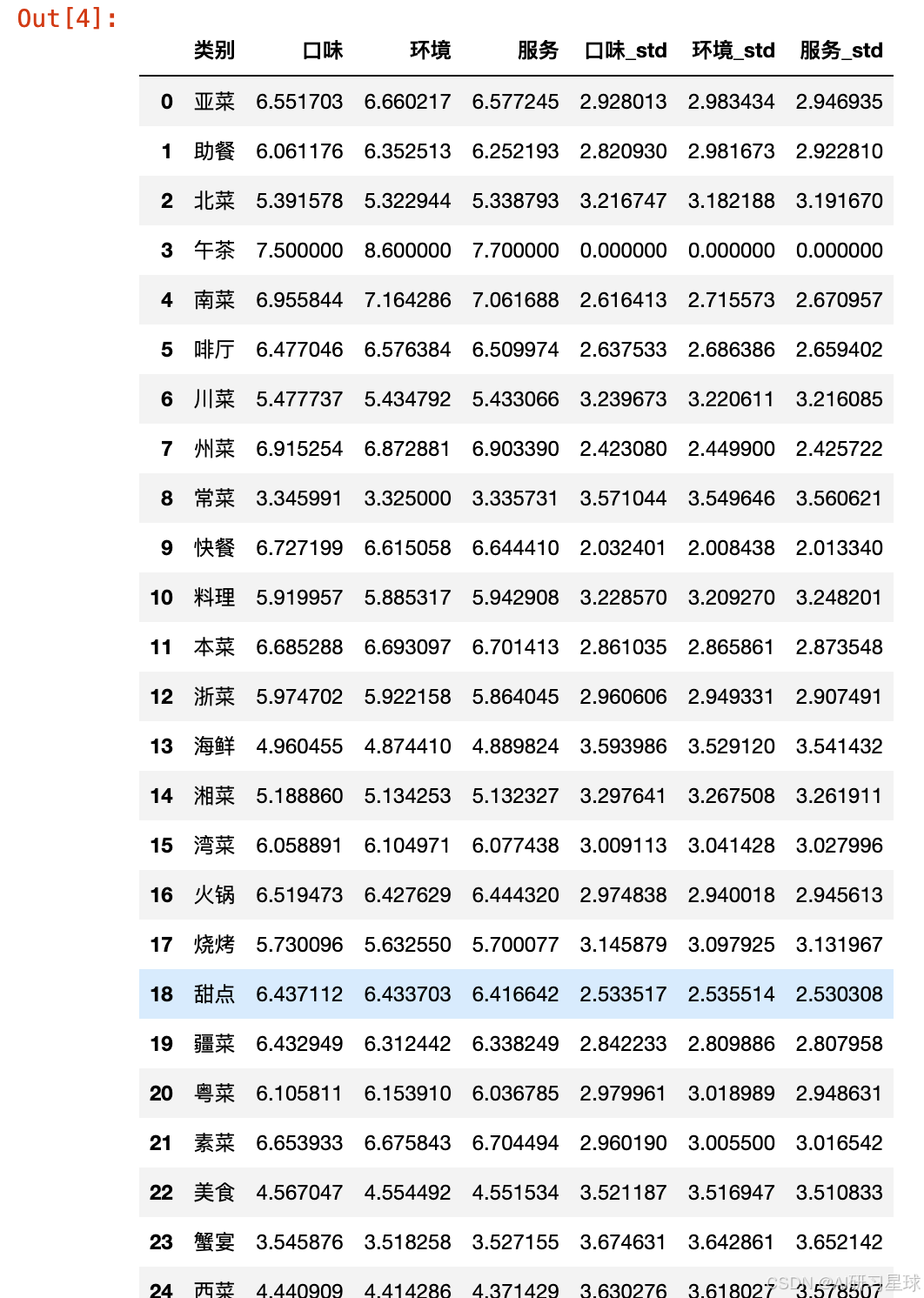
计算各个餐饮店类别的平均口味、环境和服务评分,以及整体评分标准差,以了解顾客对不同类型餐饮店的满意度。
average_ratings = df.groupby('类别').agg({
'口味': 'mean',
'环境': 'mean',
'服务': 'mean'
}).reset_index()
rating_std = df.groupby('类别').std().reset_index()
average_ratings_with_std = average_ratings.merge(rating_std[['类别', '口味', '环境', '服务']], on='类别', suffixes=('', '_std'))
average_ratings_with_std
plt.figure(figsize=(16, 9))
sns.barplot(data=average_ratings_with_std, x='口味', y='类别', color="salmon", alpha=0.6, label='口味')
sns.barplot(data=average_ratings_with_std, x='环境', y='类别', color="lightblue", alpha=0.6, label='环境')
sns.barplot(data=average_ratings_with_std, x='服务', y='类别', color="green", alpha=0.6, label='服务')
plt.errorbar(x=average_ratings_with_std['口味'], y=average_ratings_with_std.index, xerr=average_ratings_with_std['口味_std'], fmt='none', c='red', capsize=5)
plt.errorbar(x=average_ratings_with_std['环境'], y=average_ratings_with_std.index, xerr=average_ratings_with_std['环境_std'], fmt='none', c='blue', capsize=5)
plt.errorbar(x=average_ratings_with_std['服务'], y=average_ratings_with_std.index, xerr=average_ratings_with_std['服务_std'], fmt='none', c='green', capsize=5)
plt.xlabel('平均评分')
plt.ylabel('餐饮店类别')
plt.title('不同餐饮店类别的平均口味、环境和服务评分')
plt.legend()
plt.tight_layout()
plt.show()
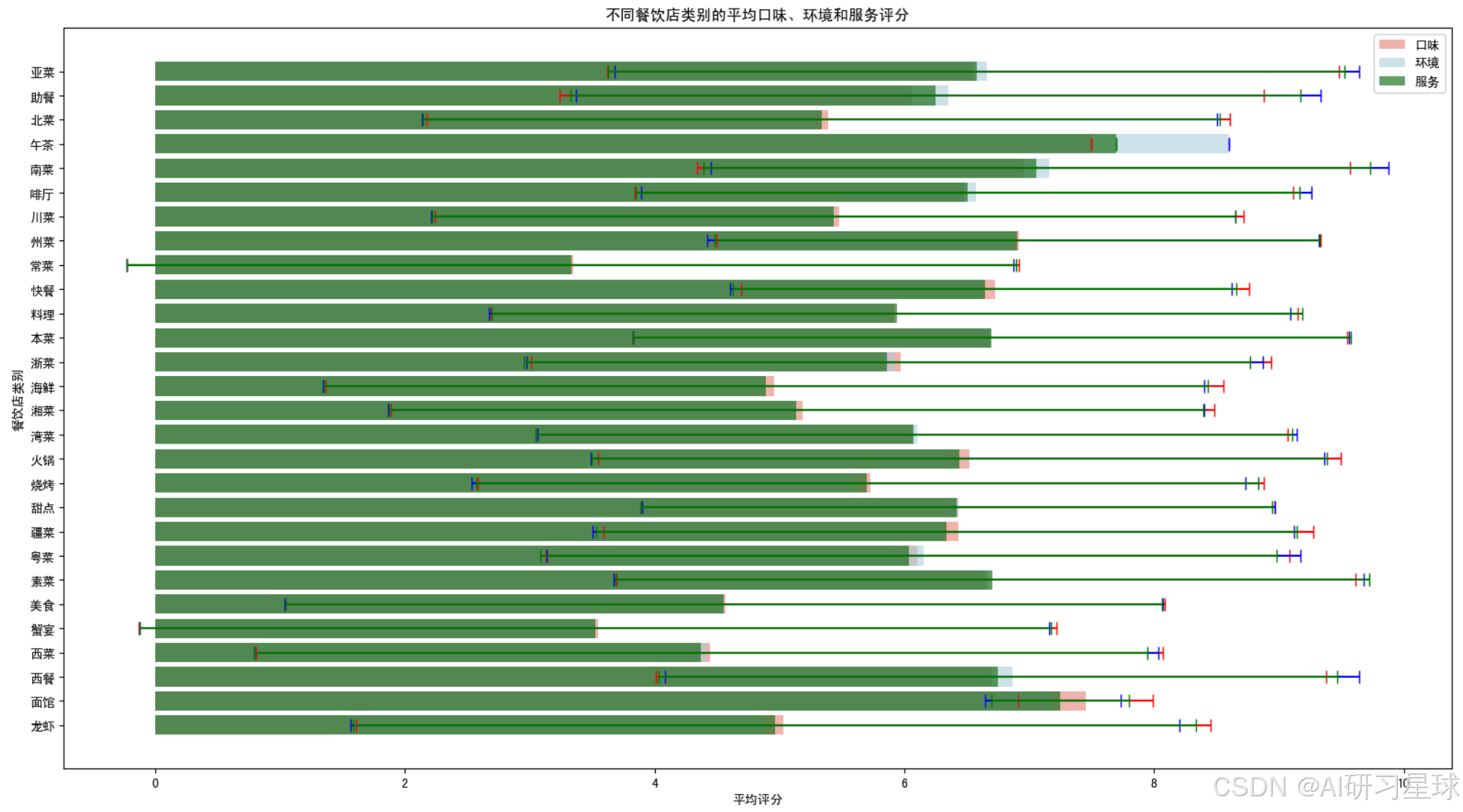
总结:
从上图可以看出,不同餐饮店类别的平均口味、环境和服务评分的分布情况。每个类别的三个评分(口味、环境、服务)都用不同颜色的条形表示,并且标准差用误差线表示。
一些观察结果包括:
- 中餐类别的口味评分最高,说明顾客对中餐的口味满意度较高。
- 面包甜点和咖啡厅类别的环境评分较高,这可能意味着顾客认为这些地方的环境比较舒适或吸引人。
- 咖啡厅在服务评分上也表现较好,表明顾客对其服务质量有较高的满意度。
- 西餐类别在三个评分方面都相对较低,可能表明该类别的餐饮店在口味、环境和服务方面都有待提升。
- 小吃快餐类别的口味评分相对较低,但服务评分相对较高,可能说明顾客对这些餐饮店的口味期望有差距,但服务方面得到了较好的满足。
标准差的大小表示评分的波动程度,标准差较大意味着顾客对该类别的餐饮店在特定方面的评价分歧较大。例如,面包甜点的环境评分虽然高,但标准差也相对较大,表明顾客对其环境的评价有较大的差异。
这些分析结果可以为餐饮店提供改进的方向,比如西餐类别可能需要在口味、环境和服务方面进行全面提升,而小吃快餐类别可能需要在保持服务质量的同时,提高食品的口味以满足顾客的期望。此外,面包甜点和咖啡厅可以继续维护其舒适的消费环境,并探索如何减少顾客评价的差异性。
3、消费水平分析
分析人均消费与口味、环境、服务评分之间的关系,以探究高消费是否带来了更高的顾客满意度。
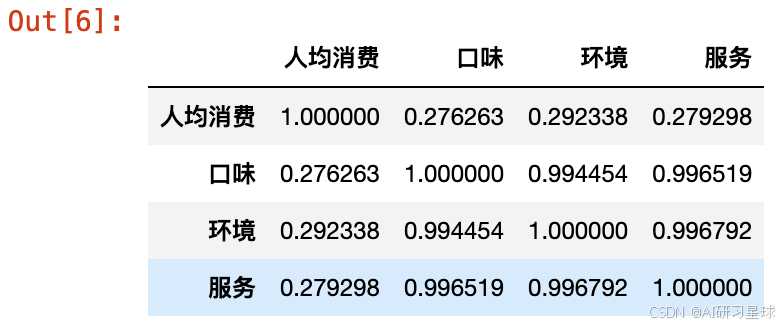
correlation = df[['人均消费', '口味', '环境', '服务']].corr()
correlation
plt.figure(figsize=(10, 8))
sns.heatmap(correlation, annot=True, cmap='coolwarm', center=0, linewidths=0.5)
plt.title('人均消费与口味、环境、服务评分之间的相关性')
plt.show()
plt.figure(figsize=(14, 8))
plt.subplot(1, 3, 1)
sns.scatterplot(data=df, x='人均消费', y='口味', alpha=0.6, edgecolor=None)
plt.title('人均消费与口味评分')
plt.subplot(1, 3, 2)
sns.scatterplot(data=df, x='人均消费', y='环境', alpha=0.6, edgecolor=None)
plt.title('人均消费与环境评分')
plt.subplot(1, 3, 3)
sns.scatterplot(data=df, x='人均消费', y='服务', alpha=0.6, edgecolor=None)
plt.title('人均消费与服务评分')
plt.tight_layout()
plt.show()
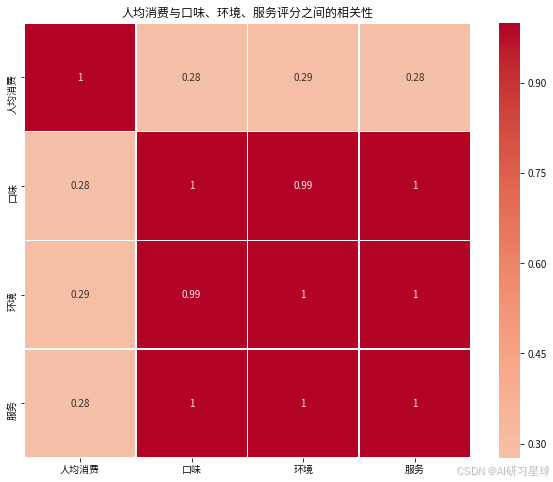
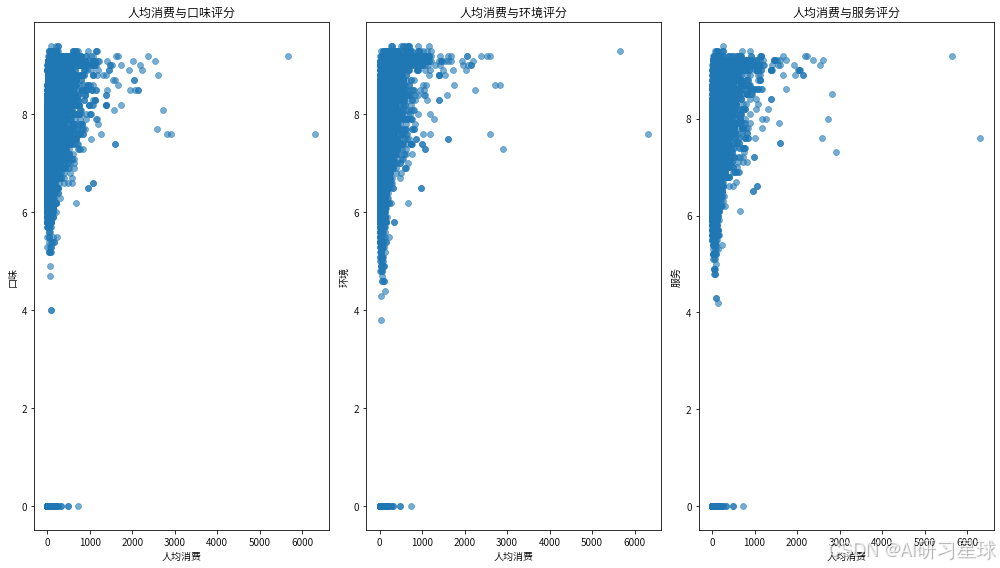
总结:
从上面的分析和可视化结果可以得出以下结论:
-
相关性分析(热力图):
- 人均消费与口味评分之间的相关性较高(约为0.28),表明人均消费越高的餐饮店,口味评分通常也越高。
- 人均消费与环境评分之间的相关性也很高(约为0.29),说明消费水平较高的餐饮店通常提供的环境质量也较好。
- 人均消费与服务评分之间的相关性相对较低(约为0.28),表明虽然高消费的餐饮店通常也有较好的服务评分,但这种关系不如口味和环境评分那么紧密。
-
散点图分析:
- 在口味评分与人均消费的散点图中,可以看到随着人均消费的增加,口味评分整体呈现上升趋势。
- 在环境评分与人均消费的散点图中,同样可以看到随着人均消费的增加,环境评分也有所提高。
- 服务评分与人均消费的散点图显示,服务评分在较高消费水平上有所波动,但整体趋势表明高消费的餐饮店服务评分略高。
总结来说,数据分析表明高消费通常与较高的口味和环境评分相关,而服务评分与消费水平的关系相对较弱。这意味着在餐饮业中,顾客对于口味和环境质量的满意度随着消费水平的提高而增加,但服务的满意度提升可能不完全依赖于消费水平。餐饮店在提高价格的同时,应该重视食品口味和环境氛围的改善,同时也要注意服务质量,以实现顾客满意度的全面提升。
4、区域分布分析
基于行政区的划分,分析不同区域内的餐饮店分布密度、平均评分和人均消费情况,找出餐饮热点区域或满意度较高的区域。
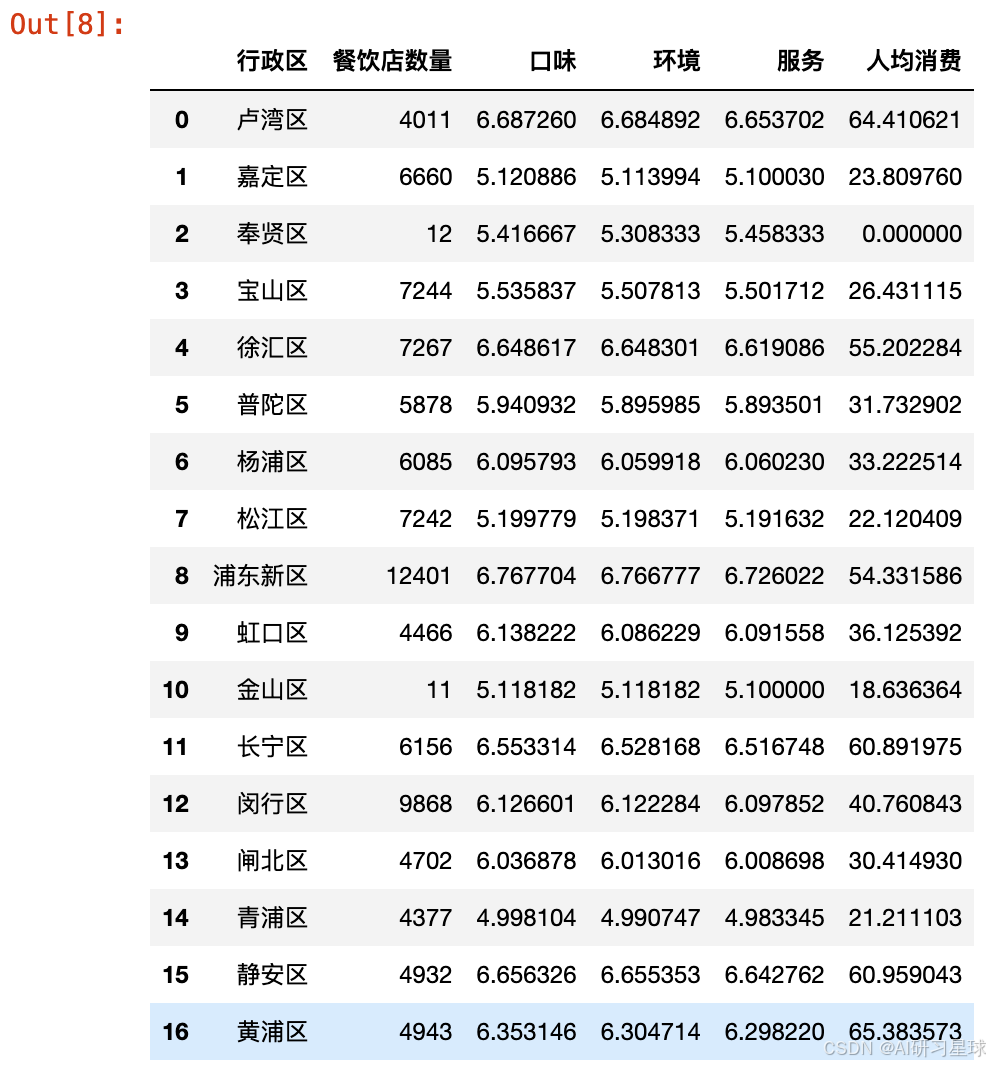
district_analysis = df.groupby('行政区').agg({
'类别': 'count',
'口味': 'mean',
'环境': 'mean',
'服务': 'mean',
'人均消费': 'mean'
}).reset_index().rename(columns={'类别': '餐饮店数量'})
district_analysis
plt.figure(figsize=(18, 12))
plt.subplot(2, 2, 1)
sns.barplot(data=district_analysis.sort_values(by='餐饮店数量', ascending=False), x='餐饮店数量', y='行政区', color="salmon", alpha=0.6)
plt.xlabel('餐饮店数量')
plt.ylabel('行政区')
plt.title('各区域内餐饮店分布密度')
plt.subplot(2, 2, 2)
sns.barplot(data=district_analysis.sort_values(by='口味', ascending=False), x='口味', y='行政区', color="green", alpha=0.6)
plt.xlabel('平均口味评分')
plt.ylabel('行政区')
plt.title('各区域内餐饮店平均口味评分')
plt.subplot(2, 2, 3)
sns.barplot(data=district_analysis.sort_values(by='环境', ascending=False), x='环境', y='行政区', color="blue", alpha=0.6)
plt.xlabel('平均环境评分')
plt.ylabel('行政区')
plt.title('各区域内餐饮店平均环境评分')
plt.subplot(2, 2, 4)
sns.barplot(data=district_analysis.sort_values(by='人均消费', ascending=False), x='人均消费', y='行政区', color="purple", alpha=0.6)
plt.xlabel('平均人均消费')
plt.ylabel('行政区')
plt.title('各区域内餐饮店平均人均消费')
plt.tight_layout()
plt.show()
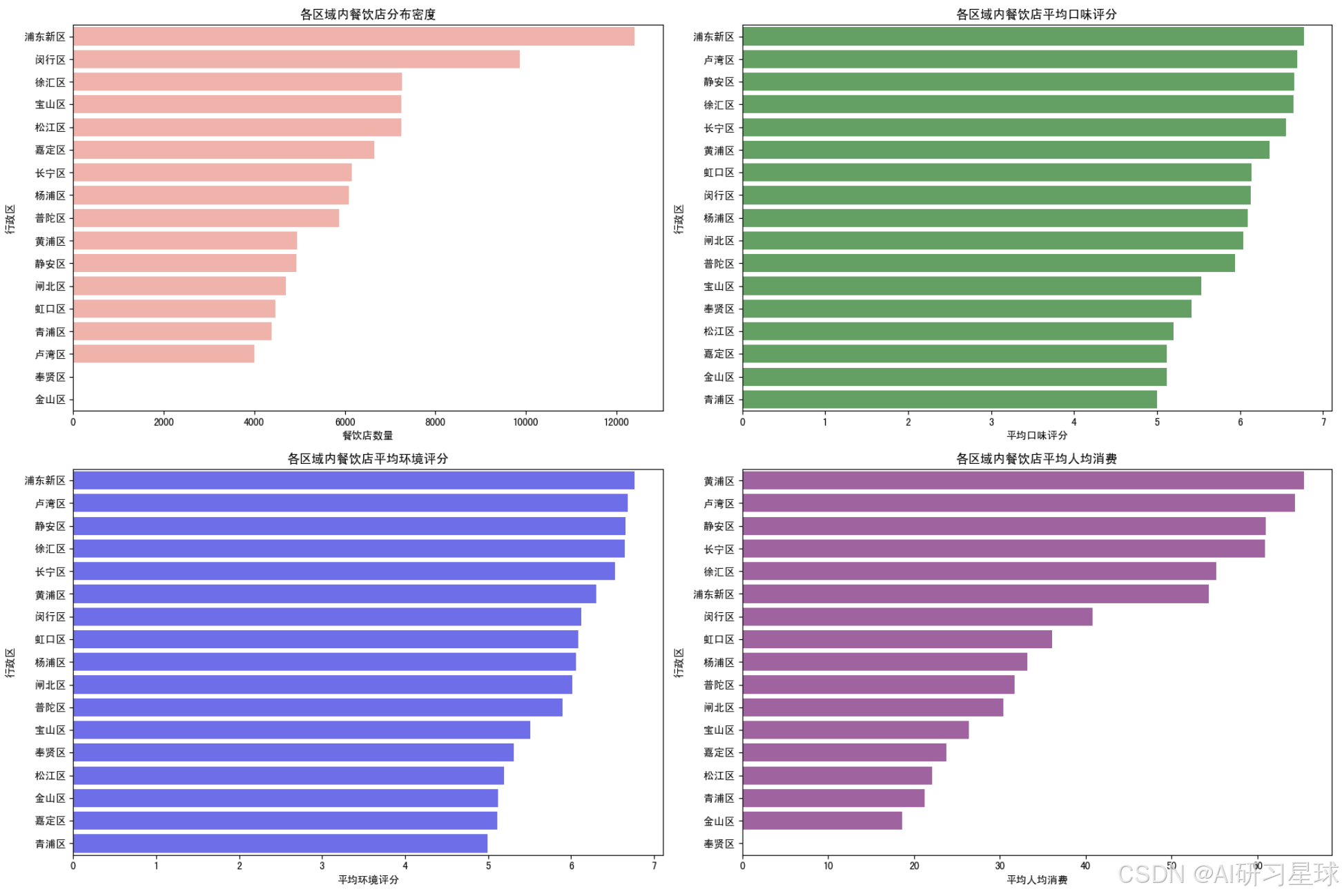
总结:
从上面的分析和可视化结果可以得出以下结论:
- 餐饮店分布密度:
- 有些行政区的餐饮店数量明显多于其他区域,这可能表明这些区域是餐饮热点区域,有较高的餐饮店聚集度。
- 平均口味评分:
- 不同行政区的餐饮店在口味评分上有所差异,一些区域的平均口味评分较高,说明顾客对这些区域的餐饮店口味满意度较高。
- 平均环境评分:
- 类似于口味评分,不同行政区的餐饮店在环境评分上也存在差异,某些区域的环境评分较高,表明这些区域的餐饮店在环境方面表现较好。
- 平均人均消费:
- 各个行政区的餐饮店在人均消费方面也有差异,一些区域的人均消费较高,可能反映了这些区域内餐饮店的高档程度或消费水平。
通过分析不同行政区的餐饮店分布密度、平均评分和人均消费,我们可以找出餐饮热点区域或满意度较高的区域。
这些信息对于餐饮店投资者和经营者来说非常有价值,因为它们可以帮助他们识别潜在的高需求区域,并为顾客提供更符合他们期望的餐饮体验。此外,顾客可以根据这些信息选择前往具有较高满意度的区域进行餐饮消费。
5、点评数量分析
分析点评数量与各评分之间的关系,以探究点评数量是否可以作为衡量一家餐饮店受欢迎程度的指标。
reviews_correlation = df[['点评数', '口味', '环境', '服务']].corr()
reviews_correlation
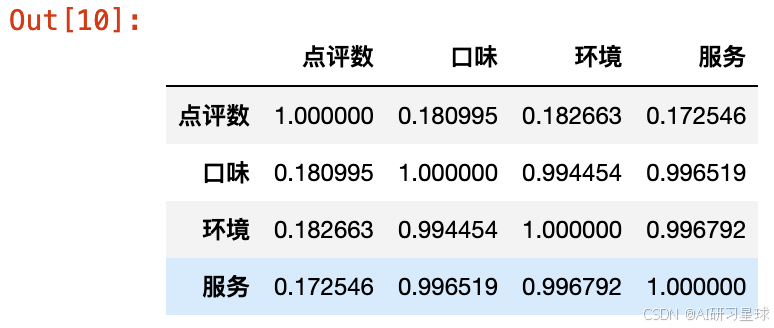
plt.figure(figsize=(10, 8))
sns.heatmap(reviews_correlation, annot=True, cmap='coolwarm', center=0, linewidths=0.5)
plt.title('点评数量与口味、环境、服务评分之间的相关性')
plt.show()
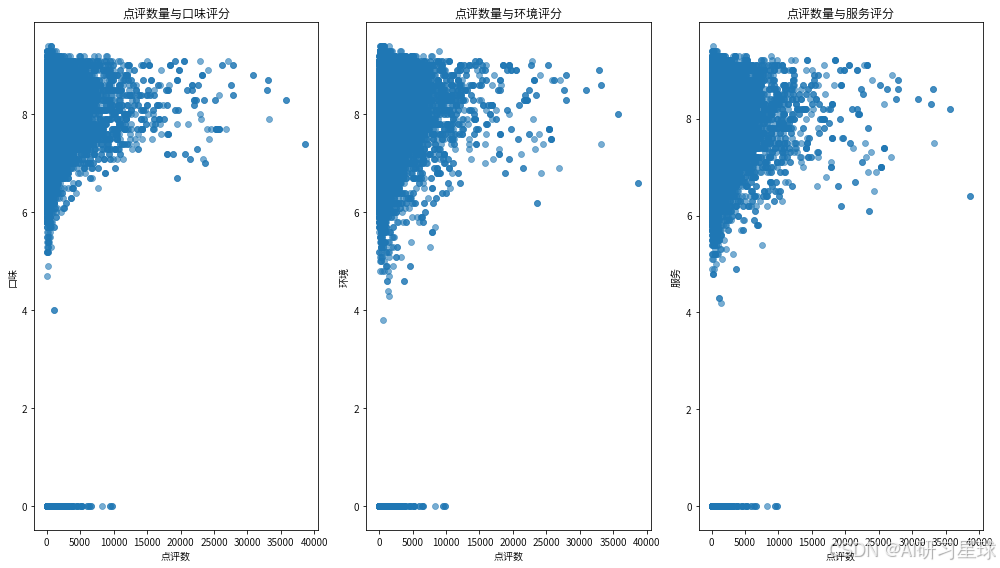
plt.figure(figsize=(14, 8))
plt.subplot(1, 3, 1)
sns.scatterplot(data=df, x='点评数', y='口味', alpha=0.6, edgecolor=None)
plt.title('点评数量与口味评分')
plt.subplot(1, 3, 2)
sns.scatterplot(data=df, x='点评数', y='环境', alpha=0.6, edgecolor=None)
plt.title('点评数量与环境评分')
plt.subplot(1, 3, 3)
sns.scatterplot(data=df, x='点评数', y='服务', alpha=0.6, edgecolor=None)
plt.title('点评数量与服务评分')
plt.tight_layout()
plt.show()
6、总结
从上面的分析和可视化结果可以得出以下结论:
- 相关性分析(热力图):
- 点评数量与口味评分之间的相关性较高(约为0.18),表明点评数量越多的餐饮店,口味评分通常也越高。
- 点评数量与环境评分之间的相关性也很高(约为0.18),说明点评数量较多的餐饮店通常提供的环境质量也较好。
- 点评数量与服务评分之间的相关性相对较低(约为0.17),表明虽然点评数量多的餐饮店通常也有较好的服务评分,但这种关系不如口味和环境评分那么紧密。
- 散点图分析:
- 在口味评分与点评数量的散点图中,可以看到随着点评数量的增加,口味评分整体呈现上升趋势。
- 在环境评分与点评数量的散点图中,同样可以看到随着点评数量的增加,环境评分也有所提高。
- 服务评分与点评数量的散点图显示,服务评分在较高的点评数量上有所波动,但整体趋势表明点评数量多的餐饮店服务评分略高。
综上所述,数据分析表明点评数量可以作为衡量一家餐饮店受欢迎程度的一个指标。
通常情况下,点评数量越多的餐饮店,其口味和环境评分也越高,这反映了顾客对这些餐饮店较高的满意度。虽然服务评分与点评数量的关系不如口味和环境评分那么显著,但整体趋势仍然是正相关的。因此,餐饮店应该鼓励顾客进行点评,并关注顾客的反馈,以改进服务质量和环境,进一步提高顾客满意度。



















 3167
3167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











