







STM32 单片机启动流程
刚接触ARM的cortex-m系列单片机时,被告知一切都从main() 函数开始,要将程序写在main()函数中。而仿真时也貌似是从main() 函数开始的,以STM32F103为例。
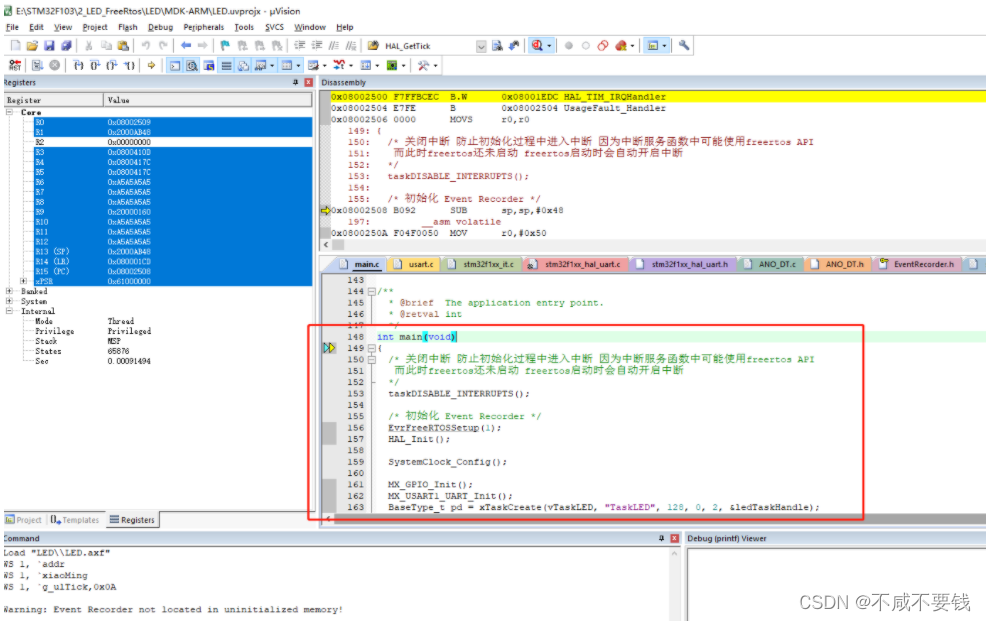
后来了解到全局变量是在main()函数之前初始化的。MDK默认情况下勾选下面选项,跳过了启动的汇编部分代码,直接进入了main() 函数.
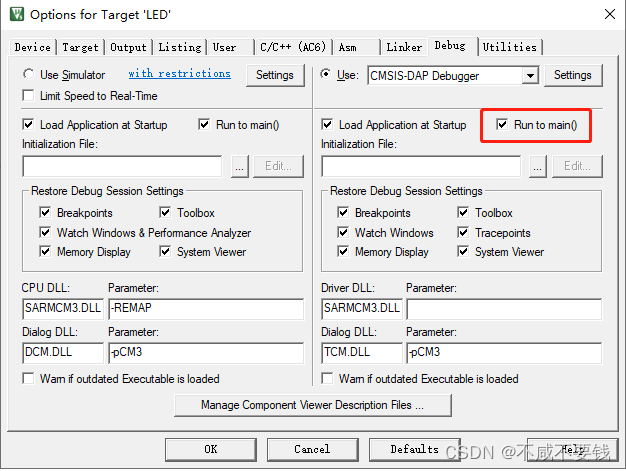
实际起始位置
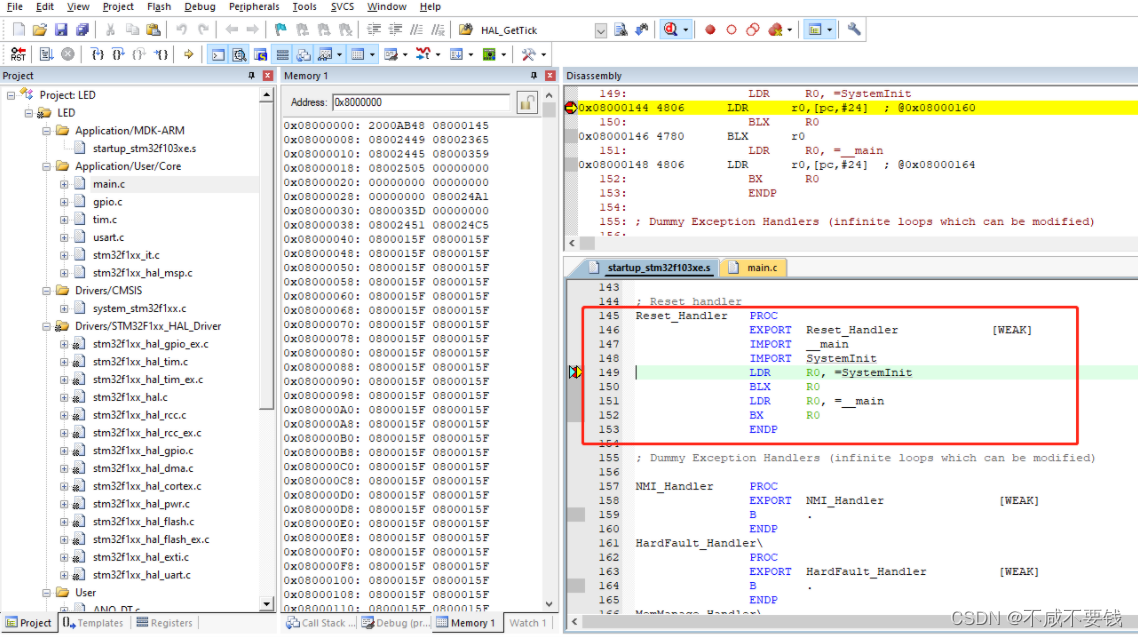
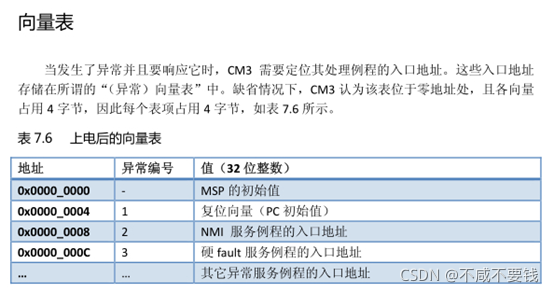
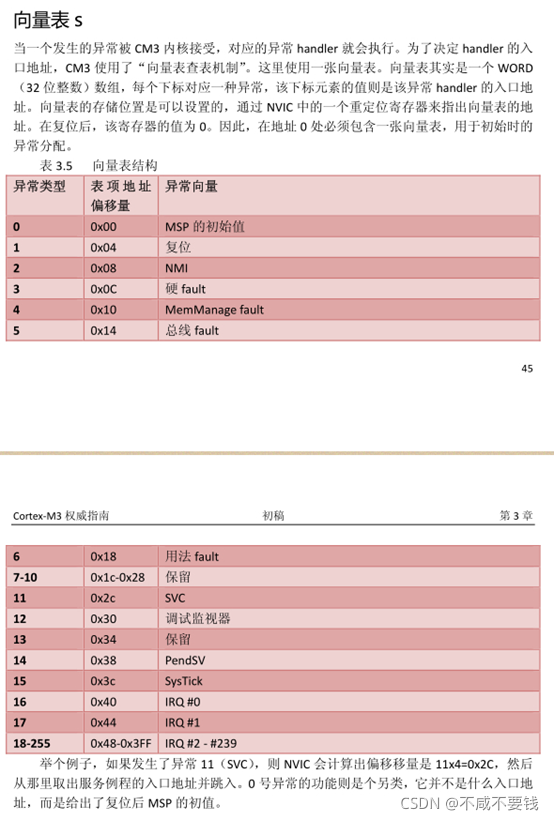
在cortex-m系列中,中断向量表存放在 Flash 开始部分,Flash中第一个字存放栈顶指针,第二个字存放复位中断服务函数入口地址,其他中断服务函数入口地址依次存放在Flash中。
MCU上电后,会将Flash中的第一个字加载到R13 MSP寄存器中,第二个字加载到R15 PC寄存器中。
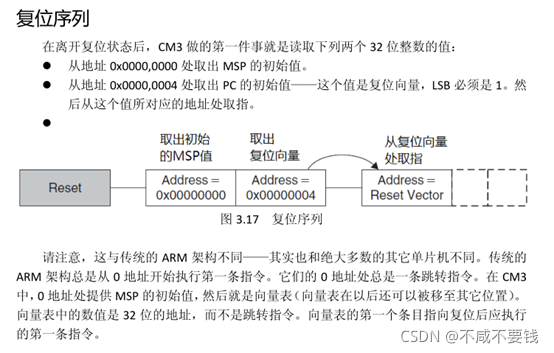
从上图可以看出ARM规定了M3,M4内核要从地址0x0000 0000读取中断向量表,而STM32设置Flash地址到0x0800 0000怎么办?
STM32将地址0x0800 0000开始的内容重映射到首地址0x0000 0000中,这样就解决了从0x0000 0000读取中断向量表的问题。
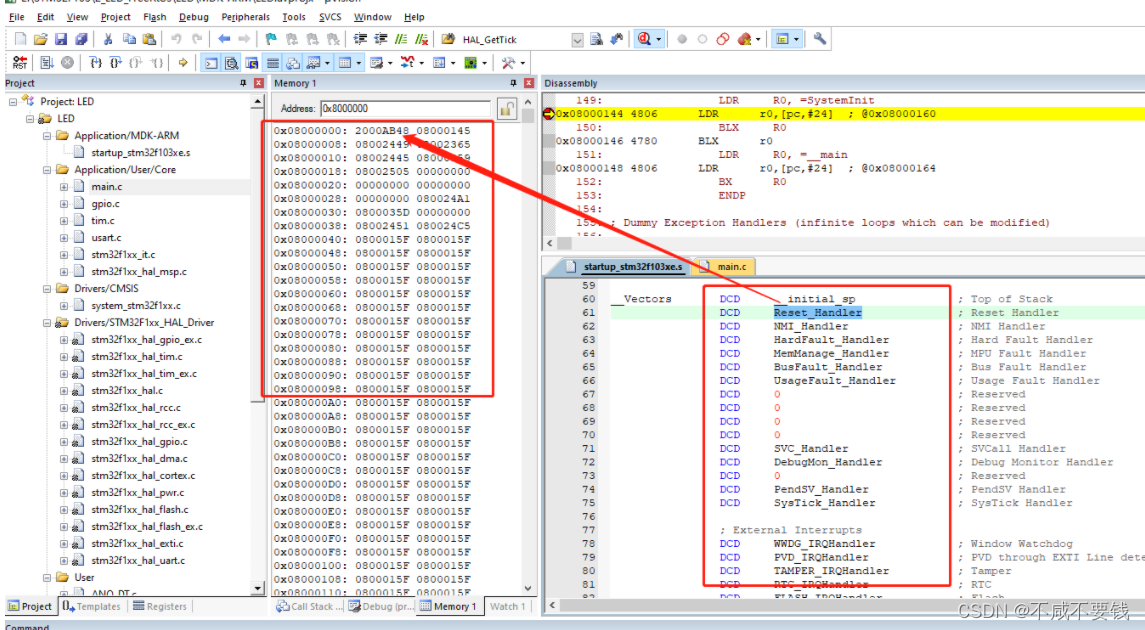
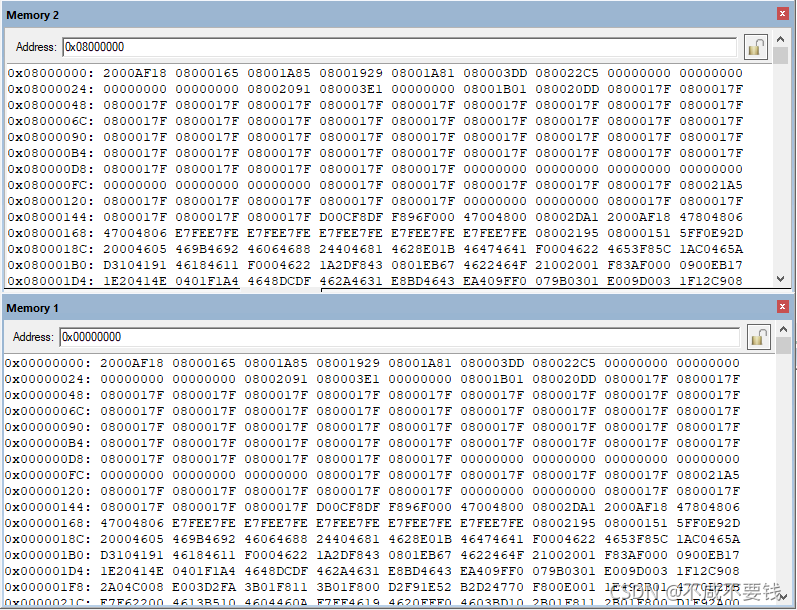
下图可以看出STM32F105实际读出的0x0000 0000和0x0800 0000内容一样
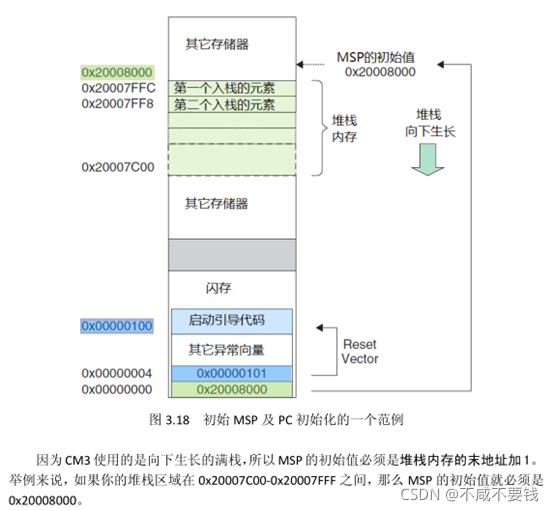
R13:栈顶指针寄存器SP
SP寄存器有两个,MSP或者PSP,PSP是为了RTOS特意设置的,如果使用RTOS,则在RTOS的任务中就是使用的PSP,在中断服务函数中则使用MSP。如果不使用RTOS,则默认一直使用MSP。

在MCU中,RAM只是负责暂存数据,真正的运算是在寄存器中完成的,例如要对两个变量进行加法运算,就需要将两个变量的值从RAM中取出存入寄存器中,然后操作寄存器进行计算,最后将计算结果存入RAM中。因此常说的在进入子函数或者中断服务函数时需要保存现场,其实也就是保存寄存器中的值,将寄存器值PUSH在栈中。
SP寄存器指向栈顶地址,因此随着PUSH和POP,SP寄存器会跟着自动变化。
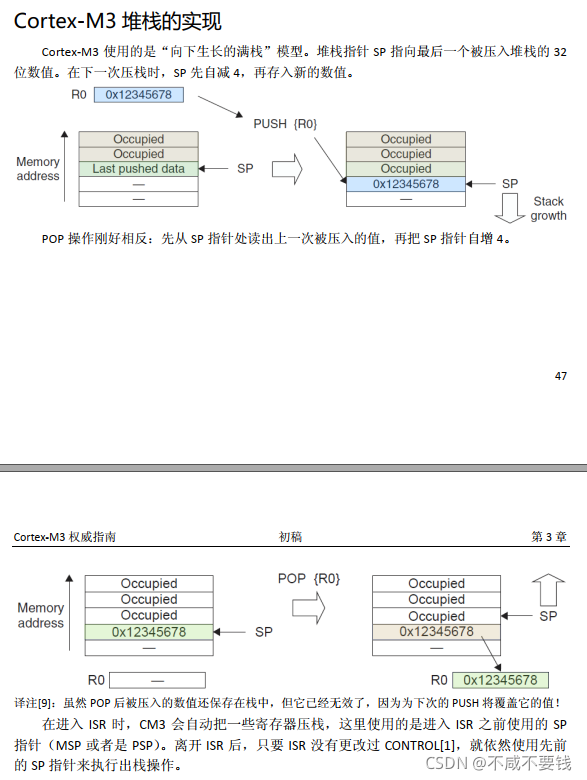
MSP寄存器存放栈顶指针,栈中存放局部变量、函数参数以及进入子函数、中断服务函数前寄存器的值,当从子函数或者中断服务函数中跳出时,会从栈中POP寄存器值,也就是恢复现场,确保程序可以正常执行。平时尽量不让使用递归就是为了防止多次调用自身,多次保存现场导致栈溢出。

入栈和出栈操作由编译器自动生成代码,但是入栈时默认只会将R0-R3入栈,如果中断服务函数过于复杂,则编译器也会将R4-R11入栈,这也就是为什么中断服务函数尽量简短的原因之一。

R15:程序计数寄存器PC
PC寄存器指向当前的程序地址。如果修改它的值,就能改变程序的执行流(很多高级技巧就在这里面)

上电时将中断向量表中的第二个字加载到PC寄存器中,也就是让程序跳转到复位中断服务函数中。
不过复位中断服务函数是一个汇编函数。
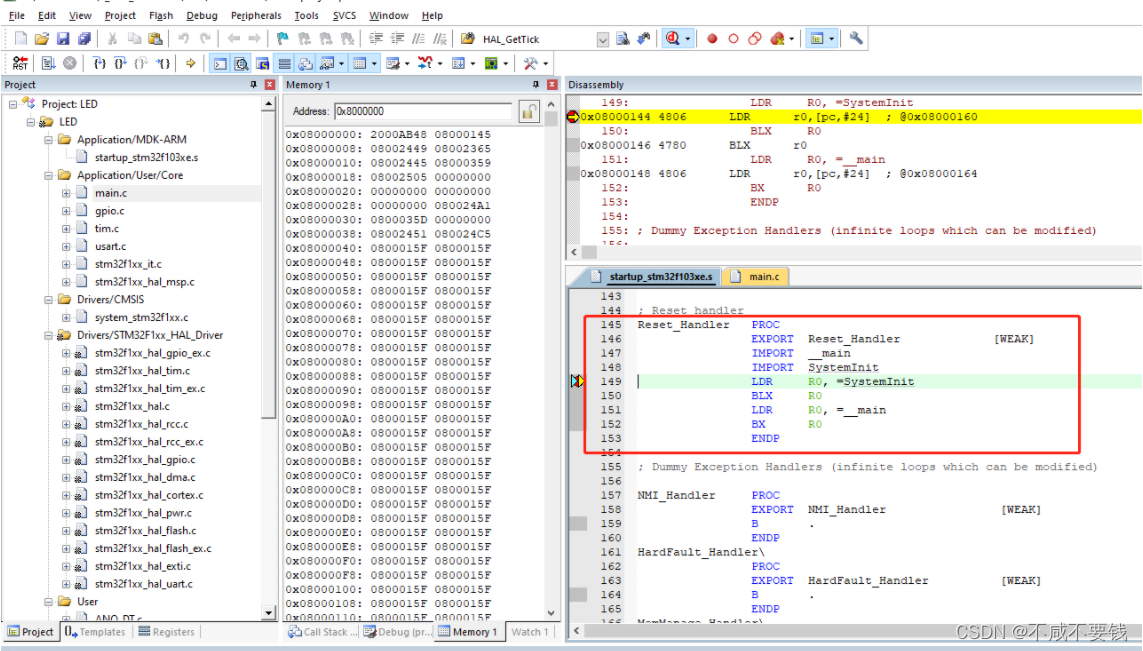
复位中断服务函数中调用了SystemInit()函数,该函数主要作用是设置中断向量表的偏移地址。也就是说中断向量表位置是可变的,当使用BOOT后,就需要在APP修改该偏移地址。
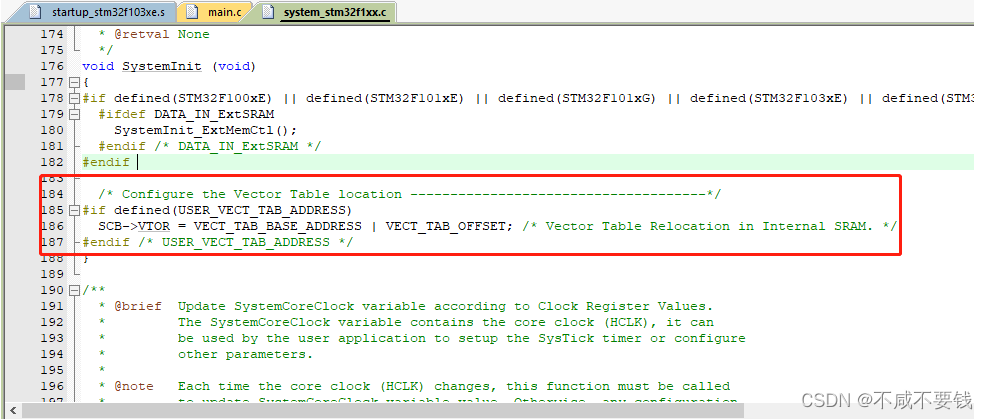
接着复位中断服务函数跳转到__main()函数中,__main()和我们平时说的main()函数是有区别的。
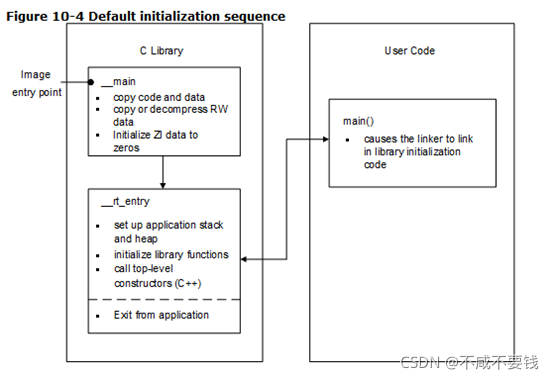
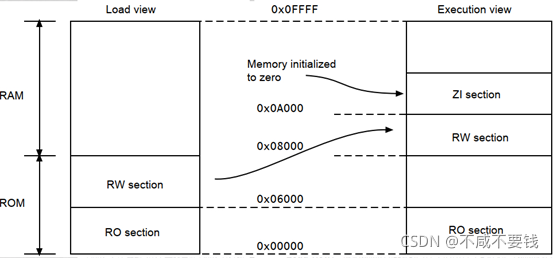
RAM掉电会丢失数据,在上电后,RAM中的数据是不确定的,在运行main()函数之前需要将RAM中的数据初始化,也就是下图左边到右边的过程,将flash中的RW数据加载到RAM中,并将RAM中的ZI段数据进行初始化操作。MDK中__main()函数帮我们自动完成了这个操作,也就是所谓的准备C语言环境,C语言环境准备好之后会跳到 main() 函数。
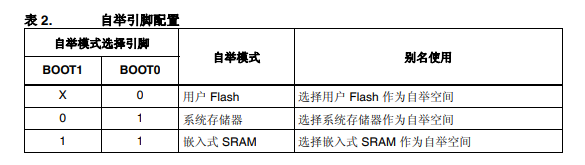
最后,其实还少说了一个,在上电后会根据boot0,boot1 的状态确定自举空间的位置,如果从系统存储器自举(系统bootLoad,出厂时,官方固化在单片机中的一段代码,用户无法修改的。在STM32中,常用的串口下载,DFU就是系统bootLoad中的功能),系统bootLoad执行完毕后才是我们上面说的哪些,文章中的图大部分来自《Cortex-M3 权威指南》














 5803
5803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









