






0、 摘要
为了解决数据稀缺及冷启动问题,提出K-DCN(pretrain + fine-tune)方法。
构建了一个10亿规模大小的会话知识图谱CKG。通过引入KGE和GCN来预训练,以编码语义和结构信息。
为了使CTR预测模型能够感知用户的当前状态以及对话和项目之间的关系,引入了基于预训练CKG的用户状态和对话交互表示,并提出了K-DCN。
1、 介绍
主要任务:预测CTR。
实现的两个步骤
- 预训练CKG:采用KGE和GCN相结合方式。
- K-DCN:引入了第一步CKG中的用户状态表示和对话交互表示,以帮助CTR预测模型感知用户的状态以及对话和项目之间的关系。
该论文贡献:
- CKG:集成了user,item和conversation信息于一体
- fine tune DCN
2、模型结构
2.1 CKG

2.1.1 数据介绍
数据来源:真实场景中的user-chitbot谈话。信息共3类。
- user个人信息,以及购物记录等。
- item信息:商品类别、卖家和商品属性等。
- 对话信息:用户意图和关键字。
2.1.2 CKG预训练
结构表示(CGN) + 语义表示(TransE)
2.2 fine-tune DCN
2.2.1 user-state:
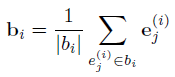
行为向量bi。

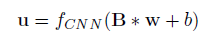
所有行为拼接后通过CNN得到u
2.2.2 对话交互表示

在用户提问的句子中提取关键字。
在候选item中提取该item的关键字。
将上两行关键字拼接后去CKG中取出嵌入表示。
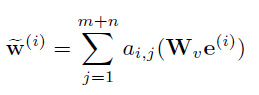
扔进MSA层中以训练query关键字与item关键字的关系。
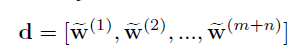
所有w拼接一起。
2.2.3 K-DCN

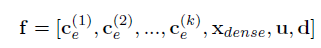
ce为iteme的其他属性表示。Xdense为item e的数字特征(销量、价格等)。
将f作为DCN中的x0。
K-DCN与DCN相比,输入变了。但重头戏就在如何变,为什么如此做。
实验效果















 1995
1995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









