






LayoutLMv2使用了现有的屏蔽视觉语言建模任务,新的文本图像对齐(将文本行与相应的图像区域对齐)和文本图像匹配任务(文档图像和文本内容是否相关)进行pre-train。不同于普通的LayoutLM模型,在fine-tune阶段结合视觉嵌入,LayoutLMv2在pre-train阶段集成视觉信息。同时,将空间感知的自注意机制集成到Transformer架构中,该机制涉及token对的二维相对位置表示。不同于LayoutLM用于建模页面布局的绝对二维位置嵌入,相对位置嵌入明确地为上下文空间建模提供了更广阔的视角
采用五种数据集作为下游任务:表单理解,收据理解,长文档理解,文档图像分类,DocVQA

2. Model Architecture
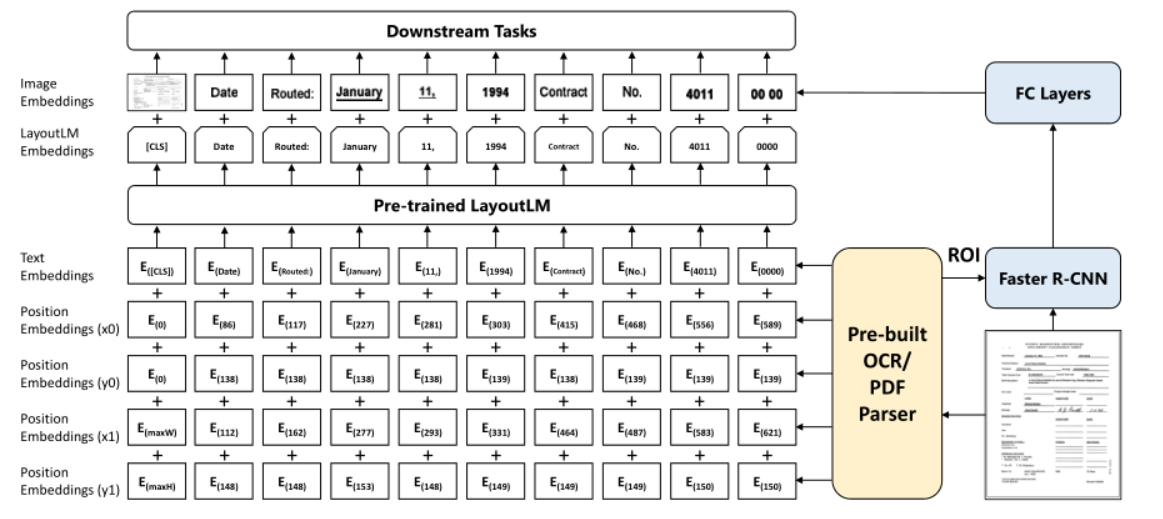
Text Embedding
由WordPiece标记OCR文本序列,并分配segment([A]/[B]),以及token idx

Visual Embedding
使用ResNet FPN作为视觉编码器主干的体系结构,给定一个文档页面图像I,大小调整为224×224,然后输入到视觉主干中,输出特征映射被平均化为固定尺寸w * h.接下来,将其展平,形成visual token embedding,长度为W×H的序列,然后用线性投影到text embedding的维度
由于无法捕获位置信息,还将一维位置嵌入添加到这些visual token embedding中
对于segment embedding,将所有visual tokens附加到可视段[C]

Layout Embedding
将所有坐标标准化并离散为[0,1000]范围内的整数,并使用两个embedding layer分别嵌入x轴特征和y轴特征,对于text/visual token box计算2D-positional embedding

一个空的边界框=(0,0,0,0,0,0)被附加到特殊标记[CLS]、[SEP]和[PAD]上。
Multi-modal Encoder with Spatial-Aware SelfAttention Mechanism

concatenate visual embedding和text embedding 后加上layout embedding作为第一层的输入
为了有效地建模文档布局中的局部不变性,需要显式地插入相对位置信息。因此,将空间感知自注意机制引入自注意层
这是由两个向量计算的attention score

加入可学习的语义相对位置和空间相对位置的偏差项,在heads之间是不同的,在所有encoder layer中共享,假设(xi,yi)锚定第i个边界框的左上角坐标,获得空间感知注意力

最后,输出向量表示为所有投影值向量相对于标准化空间感知注意分数的加权平均值

3. pre-train tasks
Masked Visual-Language Mode(MVLM)
随机屏蔽一些文本标记,并要求模型恢复被屏蔽的标记。但布局信息仍然存在,模型知道每个mask token在页面上的位置
Text-Image Align(TIA)
在文档图像上随机按行遮盖一部分文本,利用模型的文本部分输出进行词级别二分类,预测每个词是否被覆盖(即[Covered]还是[Not Covered])。文本—图像对齐任务帮助模型对齐文本和图像的位置信息。当同时执行MVLM和TIA时,不考虑MVLM中mask的tokenTIA损失。防止模型学习无用的从[MASK]到[Covered]
Text-Image Matching(TIM)
构造图文失配的负样本,随机地替换或删除一部分文档图像。并对负样本中的图像执行相同的掩蔽和覆盖操作。TIA目标标签在负样本中均设置为[Covered]。
以文档级二分类的方式预测图文是否匹配,以此来对齐文本和图像的内容信息。
4. Result
LayoutLM 2.0 在表单理解数据集 FUNSD 上的实验结果

LayoutLM 2.0 在票据理解数据集 CORD 上的实验结果

LayoutLM 2.0 在票据理解数据集 SROIE 上的实验结果

LayoutLM 2.0 在复杂布局长文档理解数据集 Kleister-NDA 上的实验结果

LayoutLM 2.0 在文档图像分类数据集 RVL-CDIP 上的实验结果和在视觉问答数据集 DocVQA 上的实验结果

5. 消融实验

从1到 2a,在不改变预训练策略的情况下添加了视觉模块,结果表明,仅使用MVLM预训练的LayoutLMv2可以有效地利用视觉信息。
然后,比较了两种跨模态对齐训练TIA和TIM。根据2中的四个结果,这两项任务都显著提高了模型的性能,并且TIA比TIM更有益于模型。同时使用这两项任务比单独使用其中一项更有效。
保留了这三个在模型架构中引入空间感知自我注意机制(SASAM)。将结果2d和3进行比较,SASAM可以进一步提高模型的精度。
最后,在3和4中,UniLMv2可以更好的初始化LayoutLMv2。















 668
668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









