









重要度采样是为了解决PG算法采样数据只是用一次造成数据浪费的情况或者策略P不易采样的状况。重要度采样使得从策略Q中采集到的样本,经过权重的计算修正得到策略P的样期望。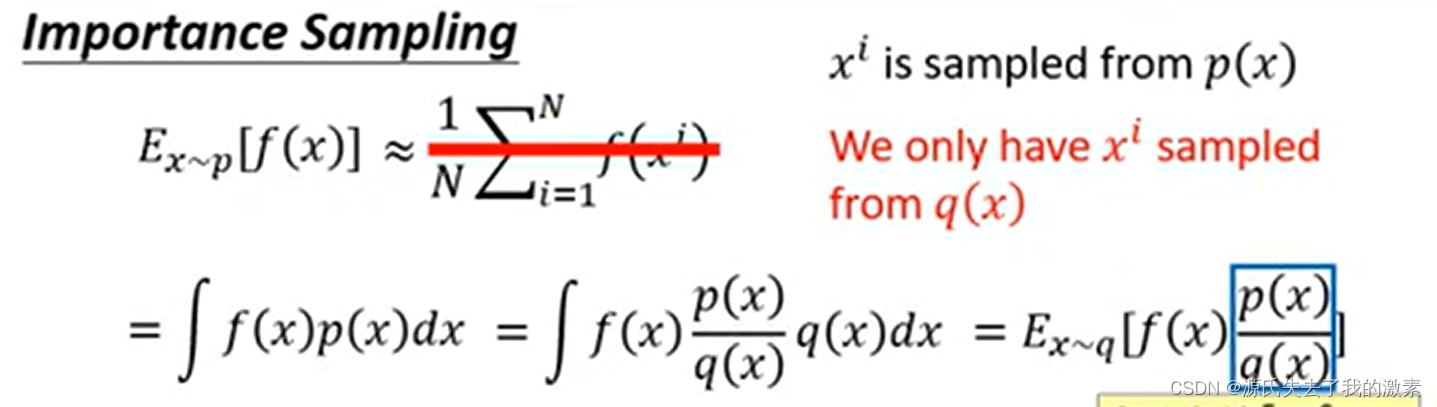
也就是说我们需要在原来的函数那里乘以一个权重来进行修正

虽然我们可以通过权重修正使得两个期望值相等,但是会发现遵循两个分布分样本方差很大,这就说明我们需要充分采样才可以保证数据的可用性。
结合PG算法的公式,我们可以得到下式

由于对于两个策略来说差异不能很大,因此状态s出现的概率差异不是很大,或者也可以理解说s出现的概率不好表示,因此我们去除掉
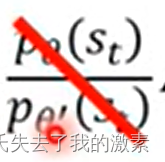 。
。
依据公式

我们可以得到梯度更新的函数为
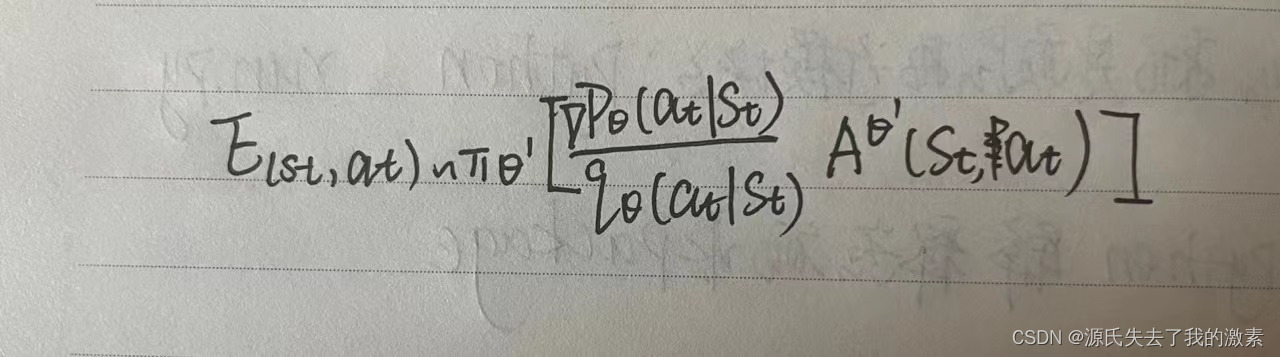
回到当初的PG算法,梯度是用于策略更新的▽R,我们的目标是需要使得R最大化,因此我们的目标函数可以写成下式:
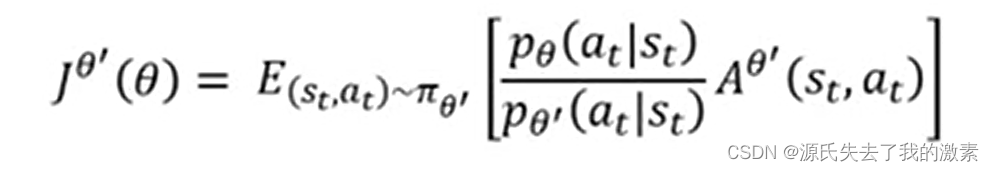
但是由于θ是不断更新的,我们又需要θ与θ'不要差太多,因此不能无休止地使用θ'需要及时地对两个策略进行调整,这就延申出了PPO















 2785
2785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









