







A Divide-and-Conquer Approach to the Summarization of Long Documents
一种分治方法运用于长文档摘要

Paper: https://arxiv.org/pdf/2004.06190
code: https://github.com/AlexGidiotis/DANCER-summ
文章的主要思想:
提出了一种新的分治法用于长文档的神经摘要。 利用文档的语篇结构,并使用句子相似性将问题拆分为较小的摘要问题的集合。将一个长文档及其摘要分成多个源-目标对,用于训练一个模型,该模型学习分别总结文档的每个部分。然后将这些部分摘要组合起来以产生最终的完整摘要。
优势
将长文档摘要问题分解为更小更简单的问题,降低计算复杂度并创建更多训练集,同时与标准方法相比,目标摘要中的噪声更少。可以提高摘要性能。在两个公开可用的学术文章数据集中取得了与最先进的结果相当的结果。
介绍
长文档输入和输出长度的增加导致神经摘要方法具有更高的计算复杂性,从而使得训练具有足够能力来执行此任务的模型变得极为困难。某些方法试图通过限制输入文档的大小来解决这些问题,方法是选择更具信息性的特定部分,或者先采用更有效的提取模型来学习识别和选择输入中最重要的部分。
相关工作
抽取式方法旨在从输入中选择突出的句子,并通常通过串联将它们组合起来,以生成摘要。这通常被视为二分类问题,其中模型针对每个句子决定是否应将其包括在摘要中。另一方面,生成式方法尝试将输入编码为隐藏的表示形式,然后使用以该表示形式为条件的解码器生成摘要。
基于RNN或卷积网络的编码器的不同变体,如RUM,在某些摘要方案中可以优于常规LSTM。还有大型预训练的Transformers模型。
长文本摘要
在输入序列和目标序列较长的情况下(例如,学术文章),一次处理完整文章的模型的复杂性会急剧增加,使得这种方法不可行。不同的方法试图通过利用文档的结构来解决此问题。使用一种混合模型,该模型具有一个用于选择重要句子的“提取器agent”和一个分别重写每个抽取的句子的“生成器”。BigBird尝试通过使用稀疏的注意力机制替换Transformer模型的完全自注意力来解决冗长的文档摘要问题,该机制可以扩展为输入长度的很多倍。而本文每个部分都视为一个单独的摘要实例,因此,我们的方法很容易并行化。
方法
引入了Divide-ANd-ConquER(DANCER)摘要,采用ROUGE度量标准,以使摘要的每个部分与文档的一部分相匹配。
P
L
C
S
(
x
,
y
)
P_{LCS}(x,y)
PLCS(x,y)的计算: 给定两个分别具有长度
I
I
I和
L
L
L的单词序列
x
=
(
x
1
,
.
.
.
,
x
I
)
x=(x_1, ...,x_I)
x=(x1,...,xI)和
y
=
(
y
1
,
.
.
.
y
+
L
)
y=(y_1,...y_+L)
y=(y1,...y+L),最长的公共子序列(LCS)是最大的公共子序列长度。如果
L
C
S
(
x
,
y
)
LCS(x,y)
LCS(x,y)表示
x
x
x和
y
y
y的最长公共子序列的长度,则
x
x
x和
y
y
y之间的ROUGE-L准确率
P
L
C
S
(
x
,
y
)
P_{LCS}(x, y)
PLCS(x,y)如下:
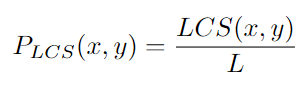
在训练期间,文档的每个部分都用作输入文本,摘要的相应部分则是目标输出摘要。训练过程是通过简单的teacher forcing执行的,其中,在给定输入序列
x
x
x的情况下,最小化目标摘要序列
y
=
(
y
1
,
.
.
.
y
N
)
y=(y^1,...y^N)
y=(y1,...yN)的最大负对数似然。
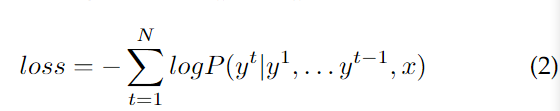
基于启发式关键字匹配部分标题中一些常见的关键字,将每个节分为不同的节类型,如引言、方法和结论。基于对arXiv和PubMed数据集的实验,我们发现对于每个文档,摘要平均分别有6.5个和6.3个句子。如下图所示:

模型变体
与DANCER结合不同摘要模型。 第一个模型是基于RNN的Pointer-Generator模型,第二个是基于Transformers的PEGASUS模型。
Pointer-Generator

指针生成器模型基于序列到序列的RNN范式,该范式在transformer之前的文献中被广泛采用。该序列到序列体系结构包括双向LSTM单元编码器,该编码器在其隐藏状态下对输入进行编码,以及单向LSTM解码器,该解码器每次自回归生成一个单词的输出。给定一个输入序列
x
=
(
x
1
,
.
.
.
,
x
T
)
x = (x^1,...,x^T)
x=(x1,...,xT),编码器产生一个隐藏状态序列
h
h
h。在每一个时间步
t
t
t上,解码器将编码器状态
h
h
h,即前一个单词作为输入,并具有一个隐藏状态
s
t
s^t
st。
该模型还配备类似注意机制,在每个解码器步骤上产生一个注意分布,如下图所示,其中
v
v
v,
W
h
W_h
Wh,
W
s
W_s
Ws和
b
a
t
n
b_atn
batn是在训练中学习的。

从注意力分布中,我们得到一个上下文向量
h
∗
t
h^{*t}
h∗t,如下图所示。上下文向量是由注意分布
α
t
\alpha_t
αt加权的编码器隐藏状态的和。

上下文向量与解码器状态
s
t
s^t
st连接,并通过两层线性层馈送,产生词汇表分布
P
v
o
c
a
b
P_{vocab}
Pvocab,如公式6所示。这本质上是给定输入序列
x
x
x和目前生成的序列
y
y
y的词汇表中所有单词的概率分布。这里
V
′
V'
V′,
V
V
V
b
′
b'
b′和
b
b
b都是可学参数。
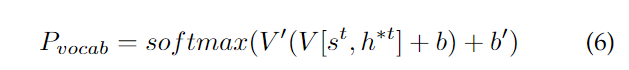
最后,该模型还使用了复制机制和,该机制能够基于切换机制直接从输入中复制特定的令牌。每个时间步长生成的令牌由词汇表分布
P
v
o
c
a
b
P_vocab
Pvocab和指针生成器概率
p
g
e
n
p_gen
pgen决定,公式如下。向量
w
h
∗
T
w_{h_*}^T
wh∗T、
w
s
w_s
ws、
w
x
t
w^t_x
wxt和标量
b
p
t
r
b_{ptr}
bptr为可学习参数,
σ
σ
σ为sigmoid函数,
P
f
i
n
a
l
(
w
)
P_{final}(w)
Pfinal(w)为生成字
w
w
w的概率。

Rotational Unit of Memory
将旋转记忆单元(RUM)纳入序列到序列模型可以改善摘要结果。特别是,在模型中包含RUM单位会导致训练过程中出现较大的梯度,从而导致训练更稳定且收敛性更好。
PEGASUS
PEGASUS模型是基于Transformer的序列到序列模型,该模型在大量无监督数据(网络和新闻文章)上进行了预训练。该模型本身是类似于和[的标准Transformer编码器/解码器。可以对预训练模型进行进一步的微调以完成摘要任务。在此处选择该模型,因为它在各种摘要基准(包括CNN / Daily Mail,Gigaword,NEWSROOM,arXiv和PubMed)上显示出了巨大的潜力。
使PEGASUS模型成为摘要任务有效的方法的是其预训练策略。间隔句生成(GSG)是一个自监督的目标,专为生成式摘要而设计。通过MASK文档中的整个句子并从文档的其余部分生成这些句子,可以鼓励模型理解整个文档并以类似摘要的方式生成句子。此外,他们提出了一种策略,旨在选择要MASK的重要句子,而不是随机选择的句子。
PEGASUS模型与Pointer-Generator模型的主要区别在于,它在子词级别而不是单词级别上运行。这是许多Transformer模型的常见做法,并使模型仅用有限的词汇就能学习和使用各种各样的单词。特别是,PEGASUS的预训练版本使用了SentencePiece Unigram算法构建的词汇表,尽管该论文的作者还尝试了字节对编码(BPE)。实际上,子词的使用非常有效,因此在此模型的上下文中无需采用复制机制。
结果
在arXiv和PubMed数据集上的实验结果分别如表所示。我们报告全长F-score的ROUGE-1, ROUGE- 2和ROUGE- l度量计算使用官方pyrouge包。所有ROUGE分数的95%置信区间最多为0.25,这是由官方的ROUGE脚本报告的。
不同的DANCER变种之间的比较,我们可以看到,PEGASUS模型是明显的赢家。这是预期的,因为它是一个更强大和先进的模型,利用广泛的未经监督的预训练。另一方面,两个RNN模型都表现出类似的性能,在arXiv数据集上,RUM模型优于LSTM模型,而在PubMed上表现略差。
















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











