







2022-arxiv-Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning

Paper: https://arxiv.org/abs/2205.05638
Code:https://github.com/r-three/t-few
少样本参数高效微调比上下文学习更好、更便宜
通过提供少量训练样本作为输入的一部分,使预训练的语言模型能够执行以前看不见的任务,而无需任何基于梯度的训练。ICL 会产生大量的计算、内存和存储成本,因为它涉及每次进行预测时处理所有训练样本。参数高效微调 (PEFT)(例如适配器模块、提示调优、稀疏更新方法等)提供了一种替代范式,其中训练一小组参数以使模型能够执行新任务。在本文中,作者严格比较了少样本ICL和PEFT,并证明后者提供了更好的精度以及显着降低的计算成本。在此过程中,作者引入了一种称为 (IA)3 的新 PEFT 方法,该方法通过学习向量缩放激活,获得更强的性能,同时只引入相对较少的新参数。作者还提出了一个基于 T0 模型的简单方法,称为 T-Few,可以应用于新任务,而无需针对特定任务的调整或修改。作者通过将 T-Few 应用于 RAFT 基准测试来验证 T-Few 在完全看不见的任务上的有效性,首次达到超人的性能,并比最先进的绝对性能高出 6%。
模型结构
通过学习向量来对激活层加权进行缩放,从而获得更强的性能,同时仅引入相对少量的新参数,如下图左边所示,它的诞生背景是为了改进 LoRA。
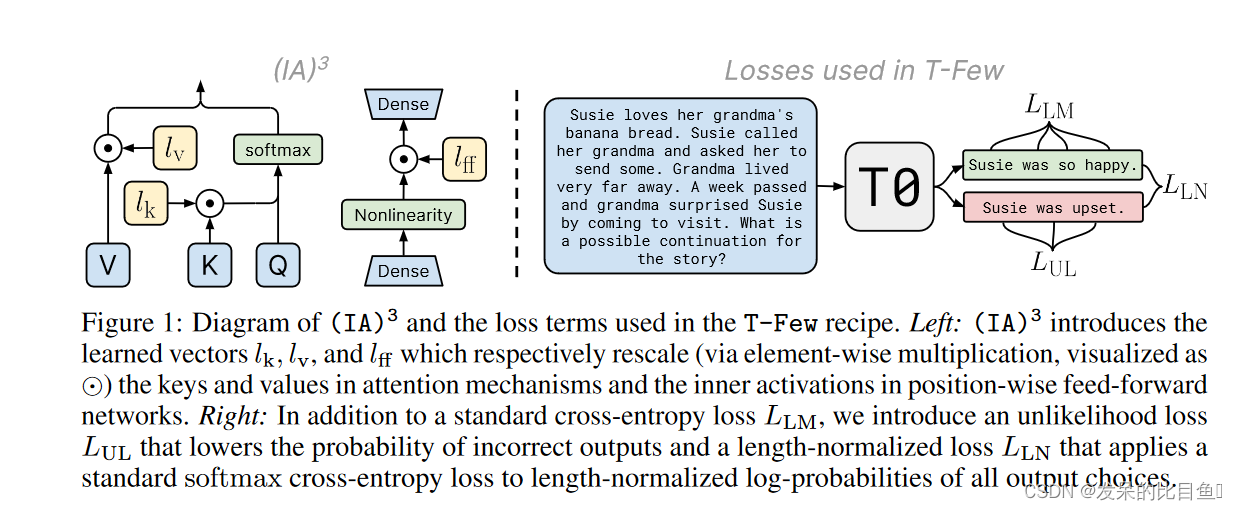
为了使微调更有效,IA3(通过抑制和放大内部激活注入适配器)使用学习向量重新调整内部激活。这些学习到的向量被注入到典型的基于transformer的架构中的attention和feedforward模块中。原始权重保持冻结,这些学习到的向量是微调期间唯一可训练的参数。与学习 LoRA 更新低秩权重矩阵不同,处理学习向量可以使可训练参数的数量少得多。
与 LoRA 类似,IA3 具有许多相同的优点:
IA3 通过大幅减少可训练参数的数量,使微调更加高效。对于 T0 模型,使用 IA3 只有大约 0.01% 的可训练参数,而使用 LoRA 有 > 0.1% 的可训练参数。
原始的预训练权重保持冻结状态,这意味着您可以拥有多个轻量级、便携式 IA3 模型,用于在其之上构建的各种下游任务。
使用 IA3 微调的模型的性能与完全微调的模型的性能相当。
IA3 不会增加任何推理延迟,因为适配器(adapter)权重可以与基础模型合并。
原则上,IA3 可以应用于神经网络中权重矩阵的任何子集,以减少可训练参数的数量。根据作者的实现,IA3 权重被添加到 Transformer 模型的 key, value 和 feedforward 层。给定注入 IA3 参数的目标层,可训练参数的数量可以根据权重矩阵的大小确定。















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









