






背景
《RepPoints: Point Set Representation for Object Detection》是最近挂在arxiv上的论文(也是2019 ICCV的论文),作者杨泽来自于微软和北大,其他作者如微软的Han Hu和Stephen Lin同时也是deformable v1和v2、relation network,GCNet的作者,产出很高。本篇的一个创新点也是deformable 卷积的巧妙应用。
论文地址:
https://arxiv.org/pdf/1904.11490.pdfarxiv.org代码暂时未开源。
一、研究动机
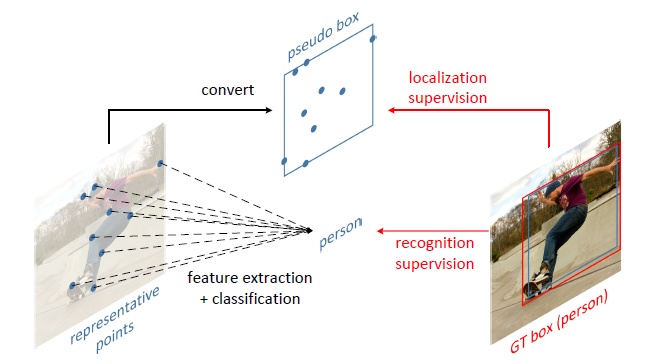
目前检测中通常是用一个矩形框来表征目标,优势是做法简单(只需回归左上和右下两个点就能确定目标),但是这种表示是粗糙的,比如在两阶段方法中提取的proposal的特征包含很多的背景特征(很多方法也是基于此改进的,比如2018 AAAI的论文RFCN++)。该论文提出了一种新的方法,不需要额外的标注(groundtruth还是目标框),用n个点来表征目标框,从而取得了更好的性能。
二、具体方法
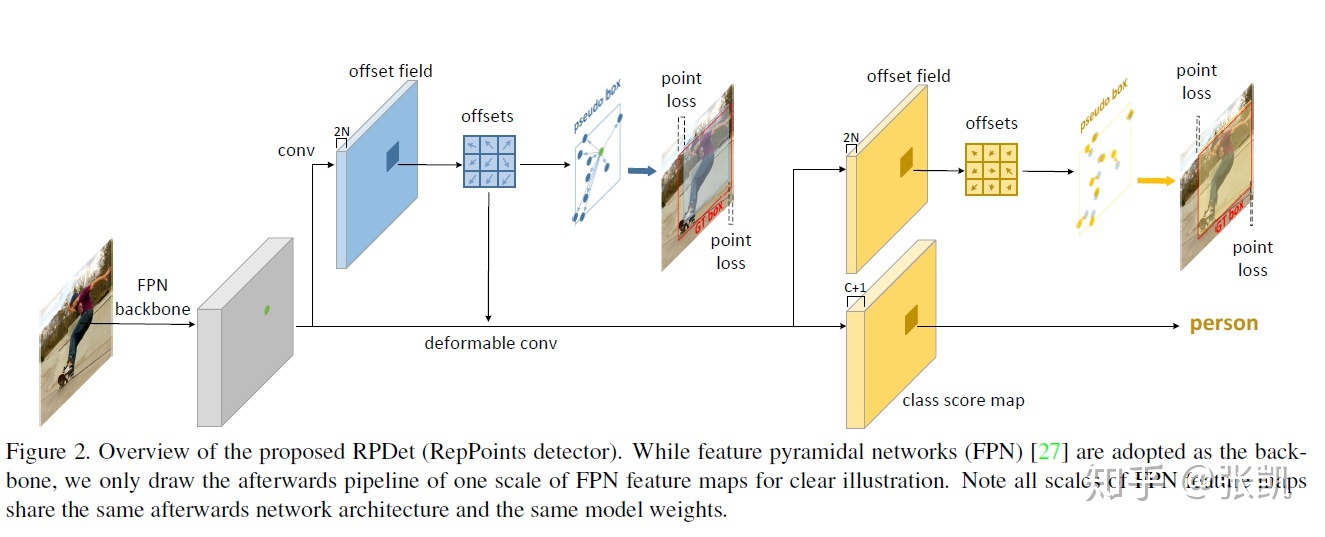
整体框架如图所示,注意此处backbone包含了特征融合部分。
1)在feature map上的每一个点预测一个n个点(n默认为9)用来表征目标,对比基于anchor的方法,此处只需预测(x,y,w,h),或者是左上右下两个点。然后再将n个点转化为一个矩形框,并用ground truth作为监督,产生损失,反传梯度。
2)同时对feature map做一次deformable卷积,其offset来自于1)中的9个点的值,然后在该feature map分别进行分类和回归的预测,注意此处回归依然是预测n个点,然后转化为矩形框,和真值进行匹配。
3)矩形框和reppoints转换方法:包括(1)采用极值点来表示矩形框,最多采用4个坐标值就能表示目标框,最少两个就行。(关于此处,如果只用四个点,那其余五个点岂不是起不到作用,也不会进行优化)(2)选取采用9个点的子集,然后采用(1)的方法。(3)采用9个点的均值作为目标框的中心,二阶矩作为目标框的宽和高。
4)训练样本:和yolo的方式类似,如果目标框真值的中心点落在对应feature map的点,就负责预测该框。(不知道是不是得益于这种方式,该方法的AP50较其他方法较高,在相同mAP的情况下)。
三、实验结果
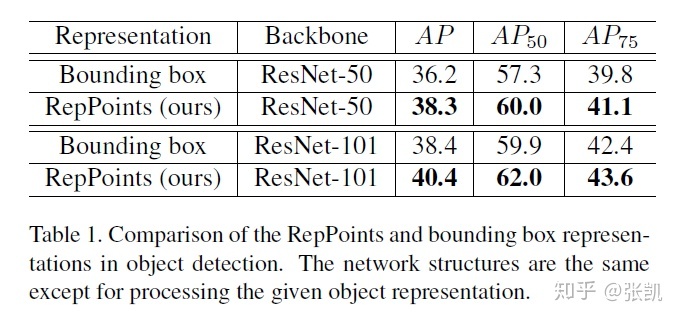
相比于基于bounding box的方法,在不同的backbone上均有两个点的提升。
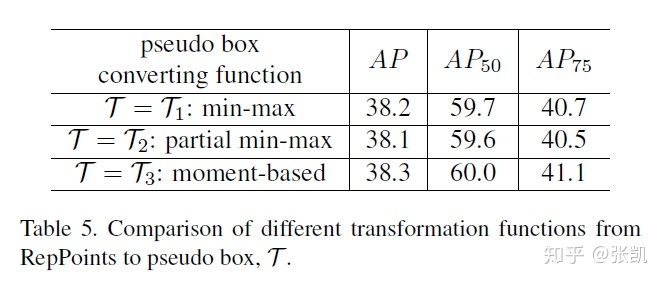
消融实验,不同框的转换方法,最后性能基本是一致的,按照之前的分析来说,moment-based利用到了所有的信息,应该会好很多,估计主要还是提升了AP50到AP75,对框的准确度提升不大。
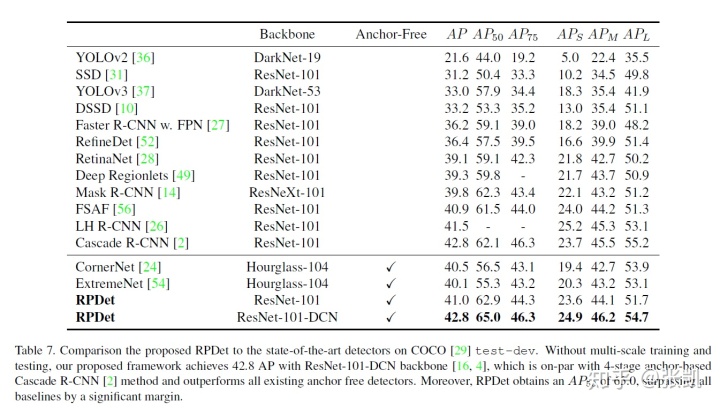
最后和其他方法的对比,可以看到RPDet最后性能还是非常好的,特别是AP50上,和FSAF有相似的mAP,但是AP50却高了1.5个点,相比CorNerNet更是高了6个点,而AP50只差0.5个点。
四、总结分析
优点:
该方法一方面采用n个点来表征目标框,anchor-free而且更加精细,另一方面又用这些点作为deformable 卷积的offset,其物理意义更加明确,最后性能提升也很明显。特别是在AP50特别高,这在主要提升目标检出的场景中是非常有意义的。















 1899
1899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









