







 文章介绍了在YOLOv7的Backbone和Neck部分引入可变形卷积(DCNv2)以及ELAN-DCN的实践,展示了如何通过DCNv2改进特征提取,特别是对位置信息的处理,以及在保持Flops不变的情况下提升模型性能。实验表明,逐步从最后一层开始添加DCN模块可以找到适合特定数据集的最佳优化策略。
文章介绍了在YOLOv7的Backbone和Neck部分引入可变形卷积(DCNv2)以及ELAN-DCN的实践,展示了如何通过DCNv2改进特征提取,特别是对位置信息的处理,以及在保持Flops不变的情况下提升模型性能。实验表明,逐步从最后一层开始添加DCN模块可以找到适合特定数据集的最佳优化策略。

一、可变形卷积
可变形卷积指卷积核在每个元素上增加了一个参数方向参数,这样卷积核就能在训练过程中扩展到很大的范围
 (a)传统的标准卷积核,尺寸为3x3(图中绿色的点);
(a)传统的标准卷积核,尺寸为3x3(图中绿色的点);
(b)可变形卷积,通过在图(a)的基础上给每个卷积核的参数添加一个方向向量(图b中的浅蓝色箭头),使卷积核变为任意形状;
(c)和(d)是可变形卷积的特殊形式。
卷积核的目的是为了提取输入物的特征。传统的卷积核通常是固定尺寸、固定大小的。这种卷积核存在的最大问题就是,对于未知的变化适应性差,泛化能力差。
- 卷积单元对输入的特征图在固定的位置进行采样;
- 池化层不断减小着特征图的尺寸;
- RoI 池化层产生空间位置受限的 RoI。
网络内部缺乏能够解决这些问题的模块,这会产生显著的问题,同一 CNN 层的激活单元的感受野尺寸都相同,这对于编码位置信息的浅层神经网络并不可取,因为不同的位置可能对应有不同尺度或者不同形变的物体,这些层需要能够自动调整尺度或者感受野的方法。再比如,目标检测虽然效果很好但是都依赖于基于特征提取的边界框,这并不是最优的方法,尤其是对于非网格状的物体而言。
因此,希望卷积核可以根据实际情况调整本身的形状,更好的提取输入的特征。
DCNv2代码实现

将下述代码添加到models/common.py文件中
class DCNv2(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=1, groups=1, act=True, dilation=1, deformable_groups=1):
super(DCNv2, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = (kernel_size, kernel_size)
self.stride = (stride, stride)
self.padding = (autopad(kernel_size, padding), autopad(kernel_size, padding))
self.dilation = (dilation, dilation)
self.groups = groups
self.deformable_groups = deformable_groups
self.weight = nn.Parameter(
torch.empty(out_channels, in_channels, *self.kernel_size)
)
self.bias = nn.Parameter(torch.empty(out_channels))
out_channels_offset_mask = (self.deformable_groups * 3 *
self.kernel_size[0] * self.kernel_size[1])
self.conv_offset_mask = nn.Conv2d(
self.in_channels,
out_channels_offset_mask,
kernel_size=self.kernel_size,
stride=self.stride,
padding=self.padding,
bias=True,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
self.reset_parameters()
def forward(self, x):
offset_mask = self.conv_offset_mask(x)
o1, o2, mask = torch.chunk(offset_mask, 3, dim=1)
offset = torch.cat((o1, o2), dim=1)
mask = torch.sigmoid(mask)
x = torch.ops.torchvision.deform_conv2d(
x,
self.weight,
offset,
mask,
self.bias,
self.stride[0], self.stride[1],
self.padding[0], self.padding[1],
self.dilation[0], self.dilation[1],
self.groups,
self.deformable_groups,
True
)
x = self.bn(x)
x = self.act(x)
return x
def reset_parameters(self):
n = self.in_channels
for k in self.kernel_size:
n *= k
std = 1. / math.sqrt(n)
self.weight.data.uniform_(-std, std)
self.bias.data.zero_()
self.conv_offset_mask.weight.data.zero_()
self.conv_offset_mask.bias.data.zero_()
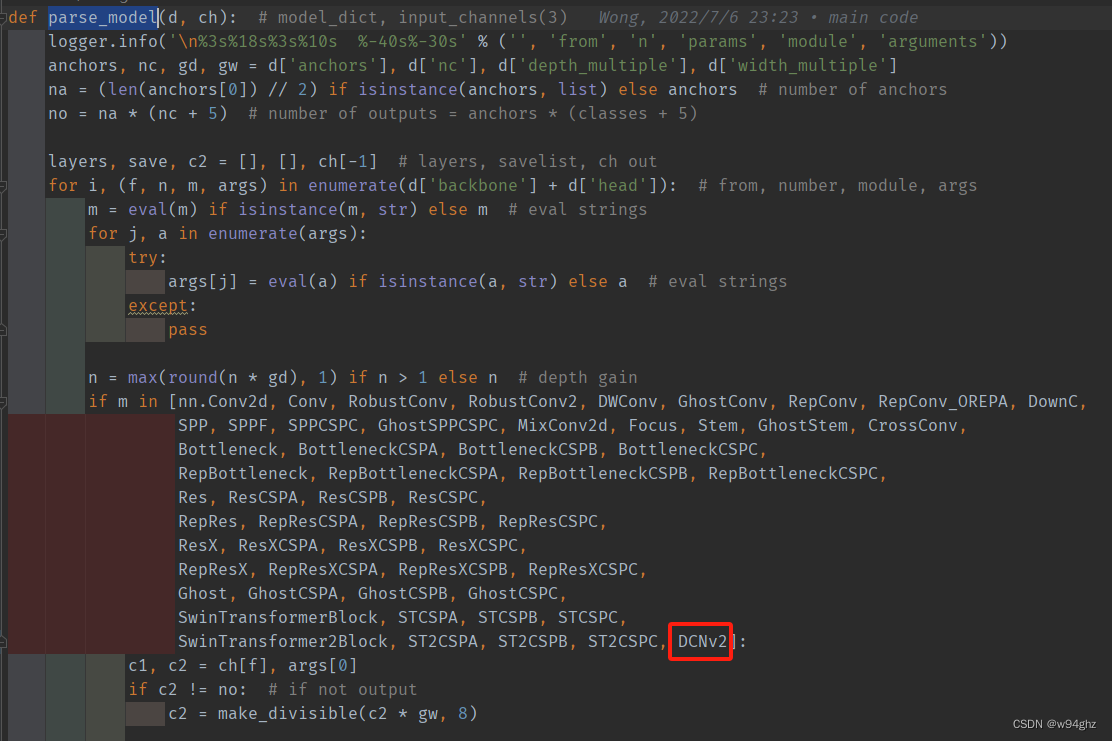
修改models/yolo.py文件中的parse_model函数:
二、Backbone添加DCN
MP-DCN
将Backbone中的MP模块替换成MP-DCN模块,模块实现如下图所示:
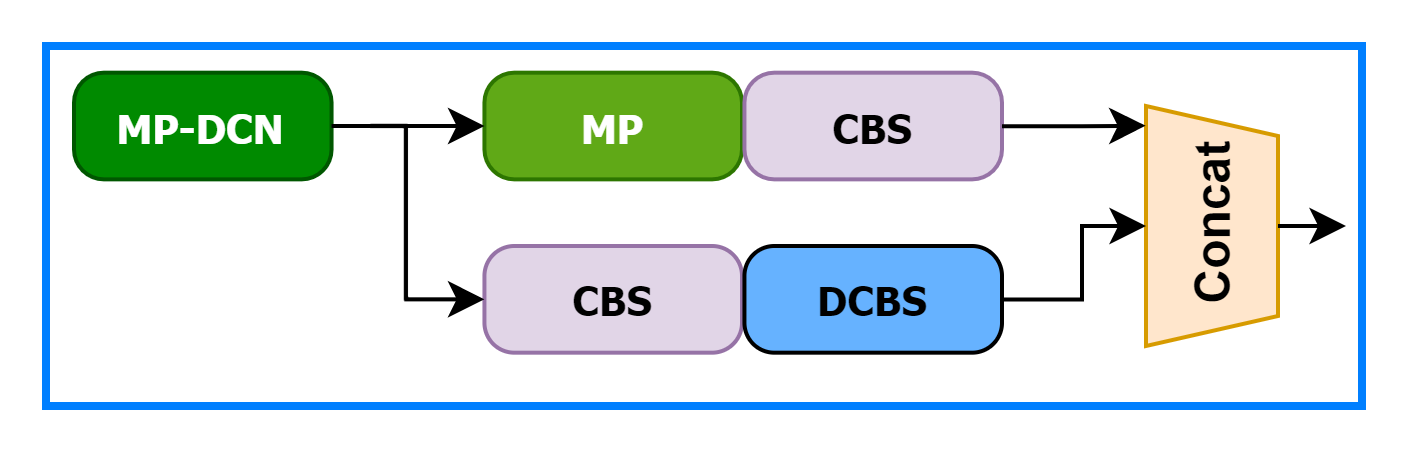
yaml文件配置如下:
# parameters
nc: 2 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, DCNv2, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, DCNv2, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, DCNv2, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]], # 75
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 88
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[101, 1, RepConv, [1024, 3, 1]],
[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
Flops不增反减!
Model Summary: 415 layers, 37665225 parameters, 37665225 gradients, 98.5 GFLOPS
总结:本人亲测将Backbone最后一层即P5/32层中的MP模块的 3 ∗ 3 3*3 3∗3卷积替换成MP-DCN可以实现对我的数据集的提点,后将Backbone中的所有MP模块的 3 ∗ 3 3*3 3∗3卷积替换,在此基础上又实现提点。做实验的小伙伴可以考虑从最后一层开始添加,逐渐增多,找到最适合自己数据集的改进方式。
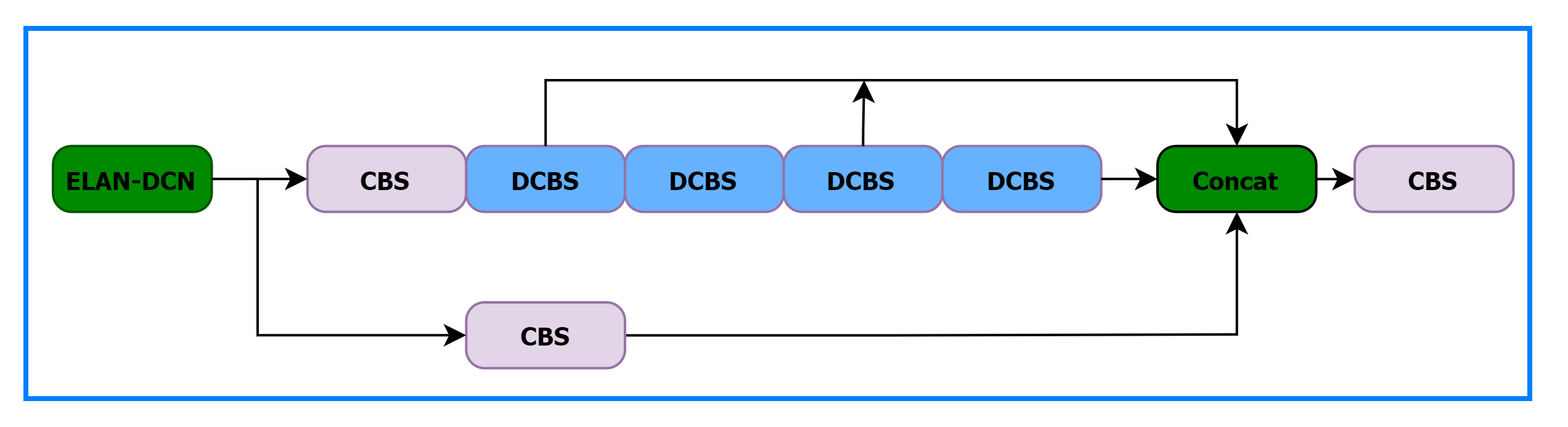
ELAN-DCN
将Backbone中的ELAN模块的
3
∗
3
3*3
3∗3卷积CBS替换成DCBS,结构如下图所示:
yaml文件配置如下:
# parameters
nc: 2 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, DCNv2, [256, 3, 1]],
[-1, 1, DCNv2, [256, 3, 1]],
[-1, 1, DCNv2, [256, 3, 1]],
[-1, 1, DCNv2, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]], # 75
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 88
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[101, 1, RepConv, [1024, 3, 1]],
[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
注意:上述yaml配置只替换了Backbone中最后一层P5/32中的ELAN模块
总结:做实验的小伙伴可以考虑从最后一层开始添加,逐渐增多,找到最适合自己数据集的改进方式。
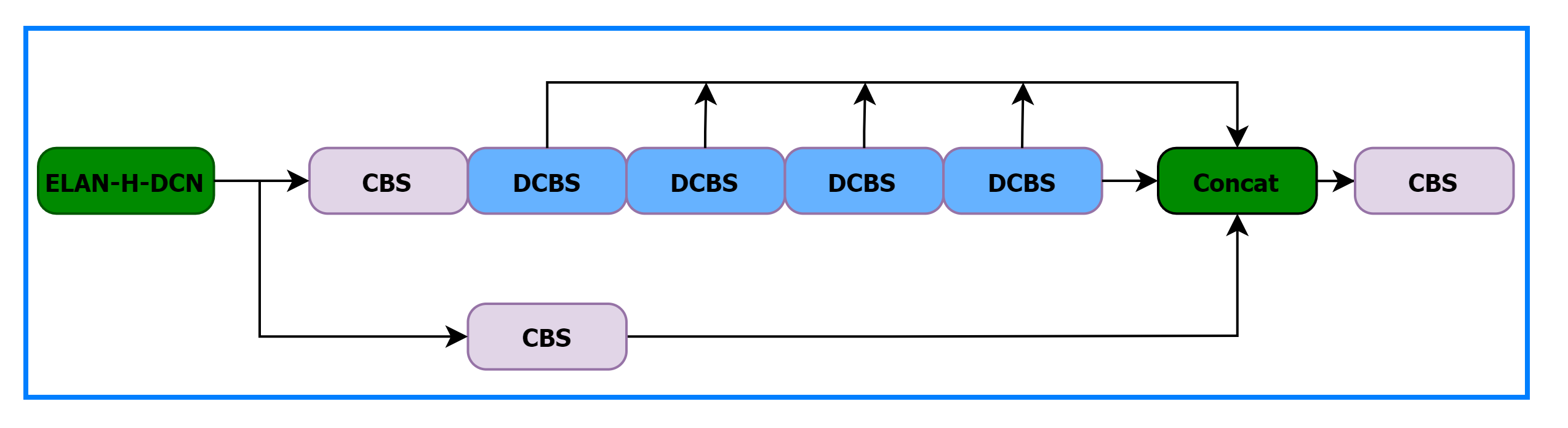
三、Neck添加DCN
ELAN-H-DCN



















 3314
3314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











