







使用本地的Art Generation with Neural Style Transfer - v2.ipynb文件。
先在cmd中运行
jupyter notebook
然后打开Art Generation with Neural Style Transfer - v2.ipynb就可以了。
人脸识别和神经风格转换 Deep Learning & Art: Neural Style Transfer神经风格转换
欢迎来到本周第二个编程作业。在本练习中,你将学习神经风格转换。这个算法由Gatys et al. (2015) 提出。(https://arxiv.org/abs/1508.06576).
在本练习中,你将
- 实现神经风格转换算法
- 使用你的算法生成新颖的艺术图像
之前你学习的大多数算法都会优化成本函数以获得一组参数值。在神经风格转换中,你将优化一个成本函数来获得像素值!
先导入包
import os
import sys
import scipy.io
import scipy.misc
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
from PIL import Image
from nst_utils import *
import numpy as np
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
import imageio
#%matplotlib inline
1-问题描述
神经风格转换(NST)是DL中最有趣的技术之一。如下图所示,它合并两个图像,即“内容”图像( C )和“风格”图像( S ),以创建“生成的”图像( G )。生成的图像G将图像C的“内容”与图像S的“样式”相结合。

在本例中,你将生成巴黎卢浮宫博物馆的图像(内容图像C),与印象派运动领袖克劳德·莫内(Claude Monet)的绘画(风格图像S)混合图像。
下面就来看看怎么做。
2-迁移学习
NST使用先前训练过的卷积网络,并在此基础上构建。
使用一个在不同任务上训练的网络并将其应用于新任务的想法称为迁移学习。
参照NST原文(https://arxiv.org/abs/1508.06576),我们使用VGG网络。具体来说,我们使用 VGG-19,一个19层版本VGG网络。这个模型已经在非常大的ImageNet数据库上进行了训练,因此学会了识别各种低级特征(浅层)和高级特征(深层)。
运行以下代码从VGG模型中加载参数,这需要几分钟时间。
model = load_vgg_model("pretrained-model/imagenet-vgg-verydeep-19.mat")
print(model)
结果
{
'input': <tf.Variable 'Variable:0' shape=(1, 300, 400, 3) dtype=float32>, 'conv1_1': <tf.Tensor 'Relu:0' shape=(1, 300, 400, 64) dtype=float32>, 'conv1_2': <tf.Tensor 'Relu_1:0' shape=(1, 300, 400, 64) dtype=float32>, 'avgpool1': <tf.Tensor 'AvgPool:0' shape=(1, 150, 200, 64) dtype=float32>, 'conv2_1': <tf.Tensor 'Relu_2:0' shape=(1, 150, 200, 128) dtype=float32>, 'conv2_2': <tf.Tensor 'Relu_3:0' shape=(1, 150, 200, 128) dtype=float32>, 'avgpool2': <tf.Tensor 'AvgPool_1:0' shape=(1, 75, 100, 128) dtype=float32>, 'conv3_1': <tf.Tensor 'Relu_4:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_2': <tf.Tensor 'Relu_5:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_3': <tf.Tensor 'Relu_6:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_4': <tf.Tensor 'Relu_7:0' shape=(1, 75, 100, 256) dtype=float32>, 'avgpool3': <tf.Tensor 'AvgPool_2:0' shape=(1, 38, 50, 256) dtype=float32>, 'conv4_1': <tf.Tensor 'Relu_8:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_2': <tf.Tensor 'Relu_9:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_3': <tf.Tensor 'Relu_10:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_4': <tf.Tensor 'Relu_11:0' shape=(1, 38, 50, 512) dtype=float32>, 'avgpool4': <tf.Tensor 'AvgPool_3:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_1': <tf.Tensor 'Relu_12:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_2': <tf.Tensor 'Relu_13:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_3': <tf.Tensor 'Relu_14:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_4': <tf.Tensor 'Relu_15:0' shape=(1, 19, 25, 512) dtype=float32>, 'avgpool5': <tf.Tensor 'AvgPool_4:0' shape=(1, 10, 13, 512) dtype=float32>}
说明:
- imagenet-vgg-verydeep-19.mat文件可以在https://www.vlfeat.org/matconvnet/pretrained/中下载。
- 如果遇到报错
TypeError: conv2d_v2() got an unexpected keyword argument 'filter',那是Tensorflow版本问题。修改一下nst_utils.py代码return tf.compat.v1.nn.conv2d(prev_layer, filter=W, strides=[1, 1, 1, 1], padding='SAME') + b
模型存储在python字典中,其中每个变量名是键,对应的值是包含该变量值的张量。要通过这个网络运行图像,你只需将图像送入模型。在TensorFlow中,你可以使用tf.assign函数来做到这一点:
model["input"].assign(image)
这将图像作为输入给模型。在此之后,如果想要访问某个特定层的激活,比如4_2,你将在正确的tensor conv4_2上运行TensorFlow会话,请这样做:
sess.run(model["conv4_2"])
3-神经风格转换
我们用3步来实现NST算法
- 构建内容损失函数 J c o n t e n t ( C , G ) J_{content}(C,G) Jcontent(C,G)
- 构建风格损失函数 J s t y l e ( S , G ) J_{style}(S,G) Jstyle(S,G)
- 把它们放在一起得到 J ( G ) = α J c o n t e n t ( C , G ) + β J s t y l e ( S , G ) J(G) = \alpha J_{content}(C,G) + \beta J_{style}(S,G) J(G)=αJcontent(C,G)+βJstyle(S,G)
3-1计算内容损失(成本)
在我们的运行示例中,内容图像C将是巴黎卢浮宫博物馆的图片。运行下面的代码可以看到卢浮宫的图片。
#content_image = scipy.misc.imread("images/louvre.jpg")
content_image = imageio.imread("images/louvre.jpg")
imshow(content_image)
plt.show()
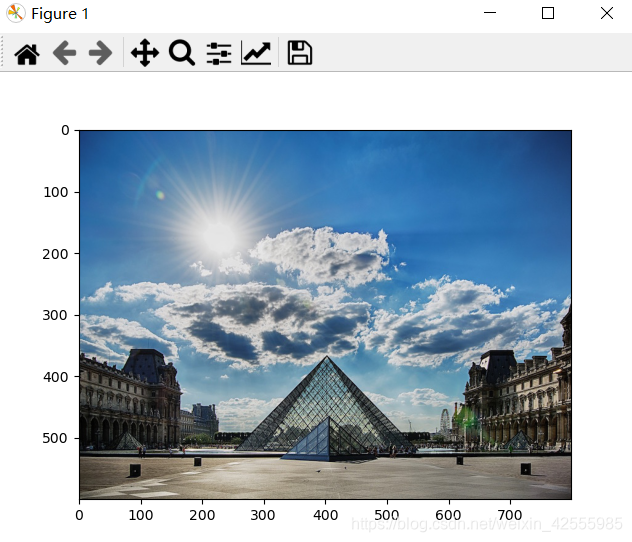
内容图片(C)显示了卢浮宫博物馆的金字塔被古老的巴黎建筑包围,在阳光明媚的天空和几朵云彩的映衬下。
3-1-1如何确保生成图像G与图像C的内容匹配?
正如我们在课程中看到的,ConvNet的浅层倾向于检测较低层次的特征,如边缘和简单纹理;而后面更深层则倾向于检测更高级的特征,例如更复杂的纹理以及对象类。
我们希望“生成的”图像G与输入图像C具有相似的内容。假设你选择了某个层的激活来表示图像的内容。实际上,如果选择网络中间的一个层(既不太浅也不太深),你将获得最令人满意的结果。(完成此练习后,可以回来尝试使用不同的层,看看结果如何变化。)
所以,假设你选择了一个特定的隐藏层来使用。现在,将图像C设置为预训练VGG网络的输入,并运行前向传播。让 a ( C ) a^{(C)} a(C)成为你选择的层中激活隐藏层。(在课程中,我们把这个写为 a [ l ] ( C ) a^{[l] (C)} a[l](C),但在这里我们将去掉上标 [ l ] [l] [l]简化符号。),激活值是 n H n_H nH × n W n_W nW × n C n_C nC的张量。然后用图像G重复这个过程:设置G为输入数据,并进行前向传播。让 a ( G ) a^{(G)} a(G)成为相应的隐层激活,我们将把内容损失函数定义为:
J c o n t e n t ( C , G ) = 1 4 × n H × n W × n C ∑ all entries ( a ( C ) − a ( G ) ) 2 (1) J_{content}(C,G) = \frac{1}{4 \times n_H \times n_W \times n_C}\sum _{ \text{all entries}} (a^{(C)} - a^{(G)})^2\tag{1} J
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









