






随着OpenAI o1近期的发布,业界讨论o1关联论文最多之一可能是早前这篇斯坦福大学和Notbad AI Inc的研究人员开发的Quiet-STaR,即让AI学会先安静的“思考”再“说话” ,回想自己一年前对于这一领域的思考和探索,当初也将这篇论文进行了引用,现将部分内容以节选回忆的方式再一次分享给大家:
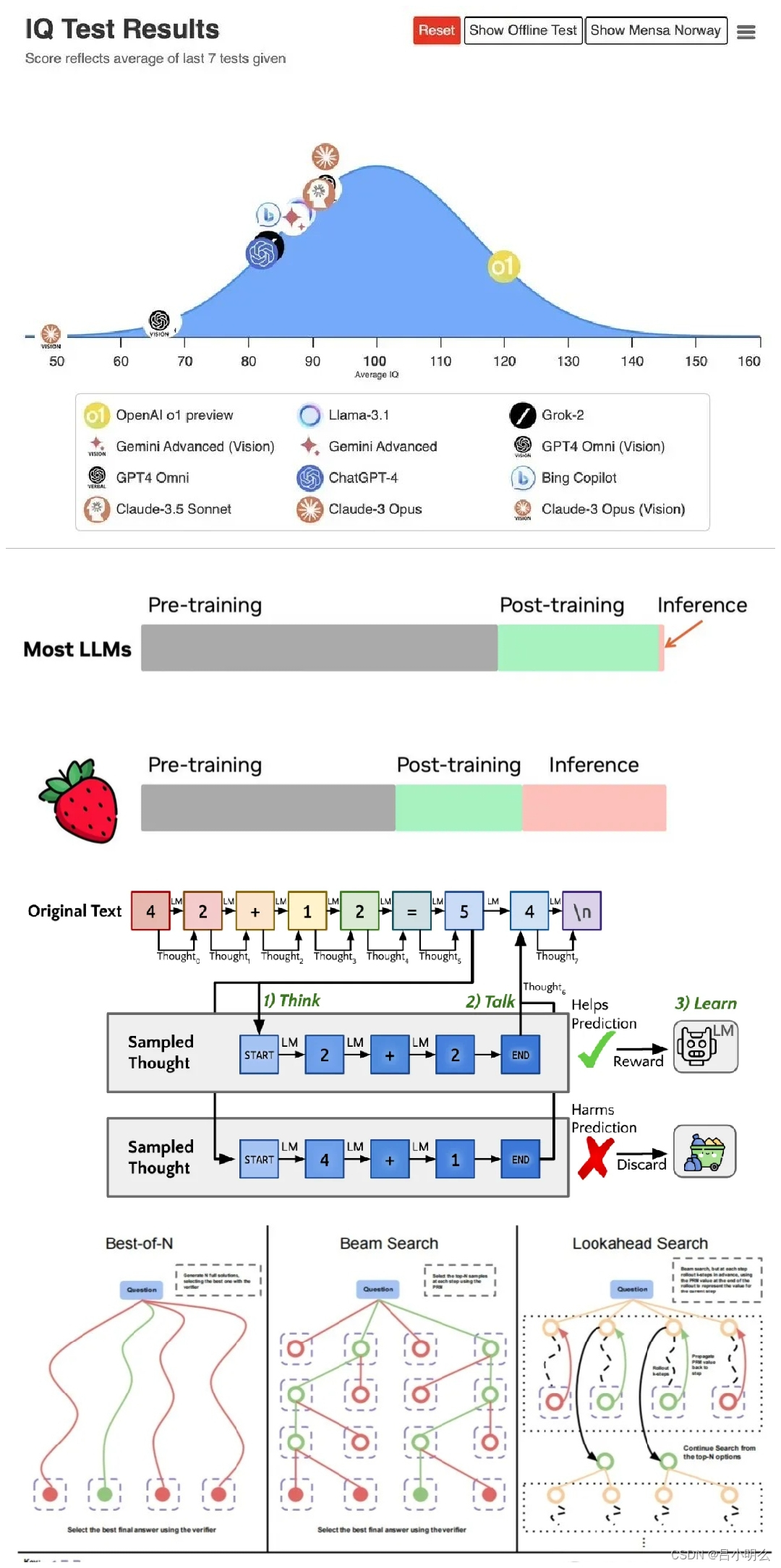
笔记节选自我半年前那篇「融合RL与LLM思想探寻世界模型以迈向AGI」10万字文章,感兴趣完整的小伙伴儿可以访问我的主页置顶或专栏收录
内容节选:↓
“...另外,论文中尝试了验证性任务,这项任务的几个方面都有可能引入不稳定性。首先,也许最重要的是,生成的思考(或思考token)的效用是思考到其对语言预测的贡献的映射的函数。基本上,从 LM 输出到下一个token预测的映射越复杂,论文观察到的不稳定性就越多。→这里引出一个问题:token级的强化过程是否是可行或有效的?
最后,论文总结到:虽然思维链提示和论文的方法之间存在自然的相似之处,但它们本质上是正交的。在思维链中,用户会积极提示模型“大声思考”,否则使用其普通的生成分布;而 Quiet-STaR 则会在每个token处安静地思考,生成的推理链的分布被其有效训练。这两种方法很可能是互补的。
例如,在可能提示语言模型使用思维链的情境中,没有任何阻止论文允许模型在输出每个token的推理之前进行思考。论文进行了一个初步实验,表明内部隐式推理可能使模型能够生成更有结构和连贯性的思维链。
通过对上述两篇论文的核心观点进行总结,我们发现其两篇论文中都在尝试将中间推理过程与原始问题上下文进行联合采样,以对其隐空间状态的中所表征的推理(思维)的潜变量进行学习,即“过程学习”,不同的是两者所采用的模型结构及数据样本各有差异和独特性。
同时,为了更深入的探究「系统二·慢思考」认知模式的本质,而不应仅仅停留在对思维的表征学习和其潜在变量对思维的简单表示这一静态表象层面,如这里提到的表征学习和潜变量的表示在认知推理过程中是如何体现和运用的?
如在香港大学发布思维扩散DoT中所提及的:「本质上,DoT逐渐更新表示隐藏空间中思维的一系列潜变量,允许推理步骤随时间扩散」,其「潜变量」「隐藏空间」「思维」其对于模型系统二的推理或思维路径的背后更底层的本质是指什么..















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









