







引言
RAG作为减少模型幻觉和让模型分析、回答私域相关知识最简单高效的方式,我们除了使用之外可以尝试了解其是如何实现的。在实现RAG的过程中Embedding是非常重要的手段。本文将带你简单地了解AI工具都是如何通过Embedding去完成语义分析匹配的。
Embedding技术简介
Embedding是一种将高维数据映射到低维空间的技术。在NLP中,Embedding通常用于将单词、句子或文档转换为连续的向量表示。这些向量不仅保留了原始数据的关键信息,还能够在低维空间中捕捉到语义上的相似性。
简单来说,就是机器无法直接识别人类的语言,所以需要通过Embedding去转化成机器能够理解和处理的数值形式。比如:"猫"和"狗"由于都是动物,所以它们的Embedding向量在空间上比较接近,而"猫"和"书"由于语义上没有直接关系,所以它们的Embedding向量在空间上距离较远。机器就是通过这样去理解人类语言的。
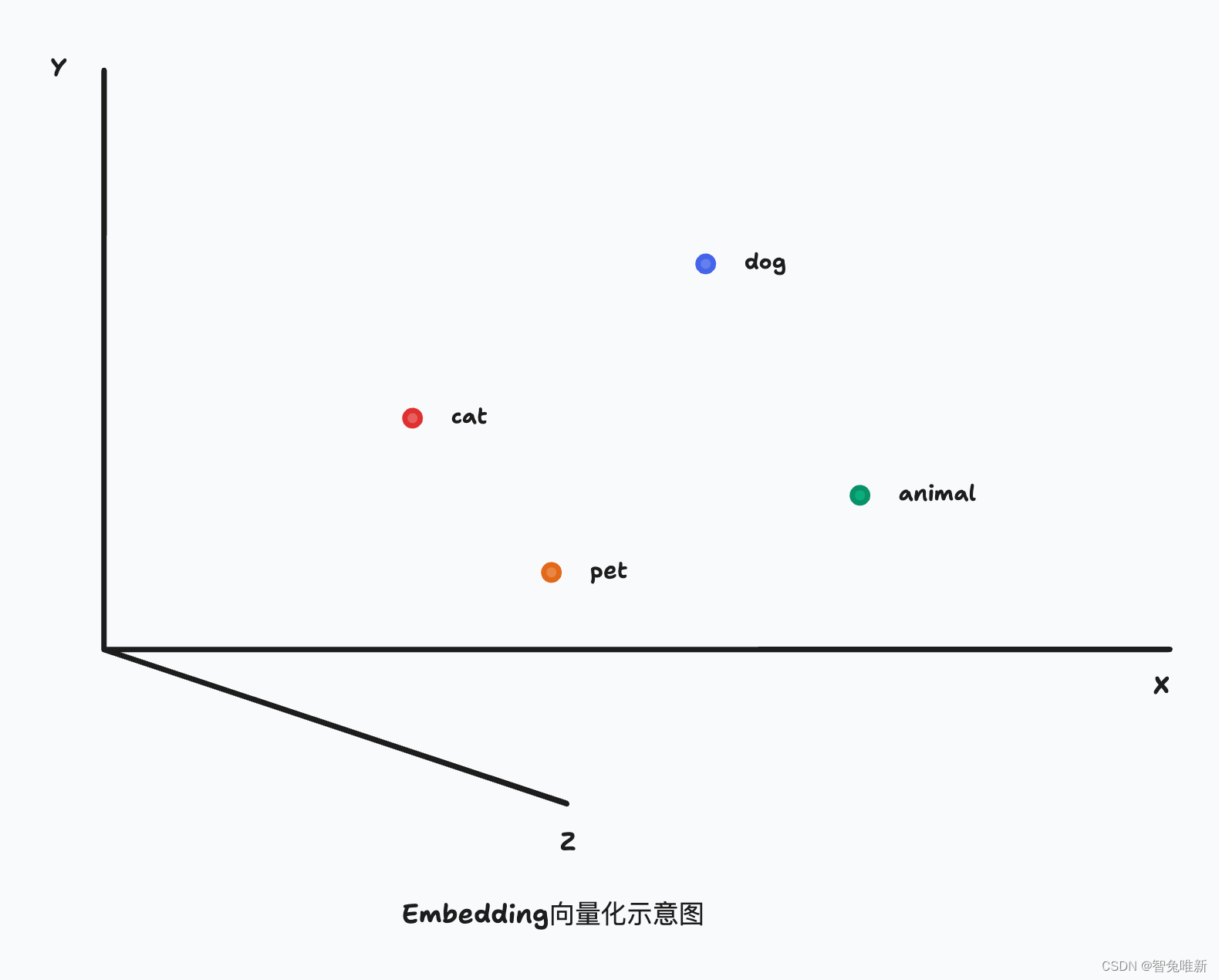
RAG知识库与Embedding的结合
RAG(Retrieval-Augmented Generation)是一种结合了检索和生成的模型架构。在RAG中,知识库的匹配是至关重要的一环。传统的匹配方法通常依赖于关键词匹配,这种方法在处理复杂语义时往往表现不佳。
通过使用Embedding技术,我们可以将知识库中的文档和查询语句转换为向量表示。这样,我们就可以利用向量之间的相似度来实现更精确的匹配。具体来说,我们可以通过计算查询向量与知识库中每个文档向量的余弦相似度,来确定最相关的文档,也就是类似上面提到的通过计算能用"猫"匹配出"狗",而不是"书"。
而通过这个我们就可以用用户输入的句子去匹配我们的数据库找到最相关的文档,从而实现RAG。
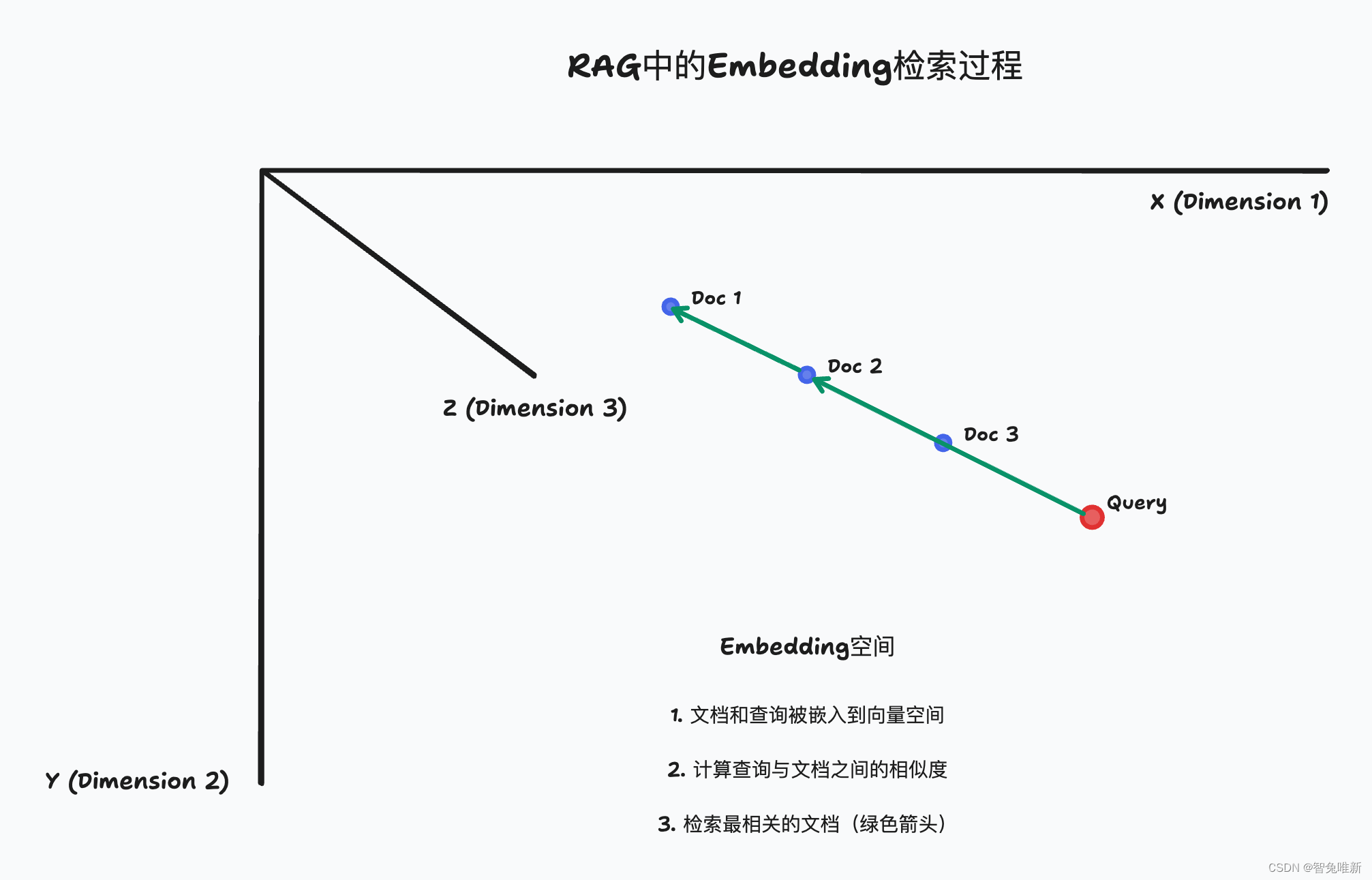
实践案例:Embedding在RAG知识库匹配中的应用
现在我们来做个简单的实践帮助大家去理解Embedding在RAG知识库匹配中的应用。
使用Qwen的embedding模型
import dashscope
from http import HTTPStatus
import numpy as np
# 设置Qwen API密钥
dashscope.api_key = 'sk-xxx'
def embed_text(text):
"""
将输入的文本转换为嵌入向量
Args:
text (str): 需要转换的文本
Returns:
list: 文本的嵌入向量
Raises:
Exception: 如果获取嵌入向量失败,抛出异常
"""
resp = dashscope.TextEmbedding 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









