










背景
近期opanai对AGI做了等级划分;等级划分意味着AGI有了一个考核定义,有了升级打怪的评价指标。并给出了目前openai正处在第一级,即将达到第二级的论断。预计在一年或者一年半内实现第二级,可以完成基本问题解决任务的系统。
| L1 | 聊天机器人 | 具有对话能力的AI |
|---|---|---|
| L2 | 推理者 | 像人一样能够解决问题的AI |
| L3 | 智能体 | 不仅能思考,还能自主采取行动的AI系统 |
| L4 | 创新者 | 能够协助人类发明创造的AI |
| L5 | 组织者 | 可以完成组织工作的AI |
文章下面部分会简单的介绍一下,如何从第一级进阶到第二级。可能的技术路线,对于第一级AGI实现路径已经有非常多的讨论,并且很多企业、团队也已经实现达到了openAI第一级的水准。也就是数第一级别的pretrain、sft、rlhf三阶段已经是一个事实的实现路径标准了。介绍文章也比较多,不过多介绍;会把跟多篇幅放在如何从第一级到第二级可能实现路径做探讨。
聊天机器人
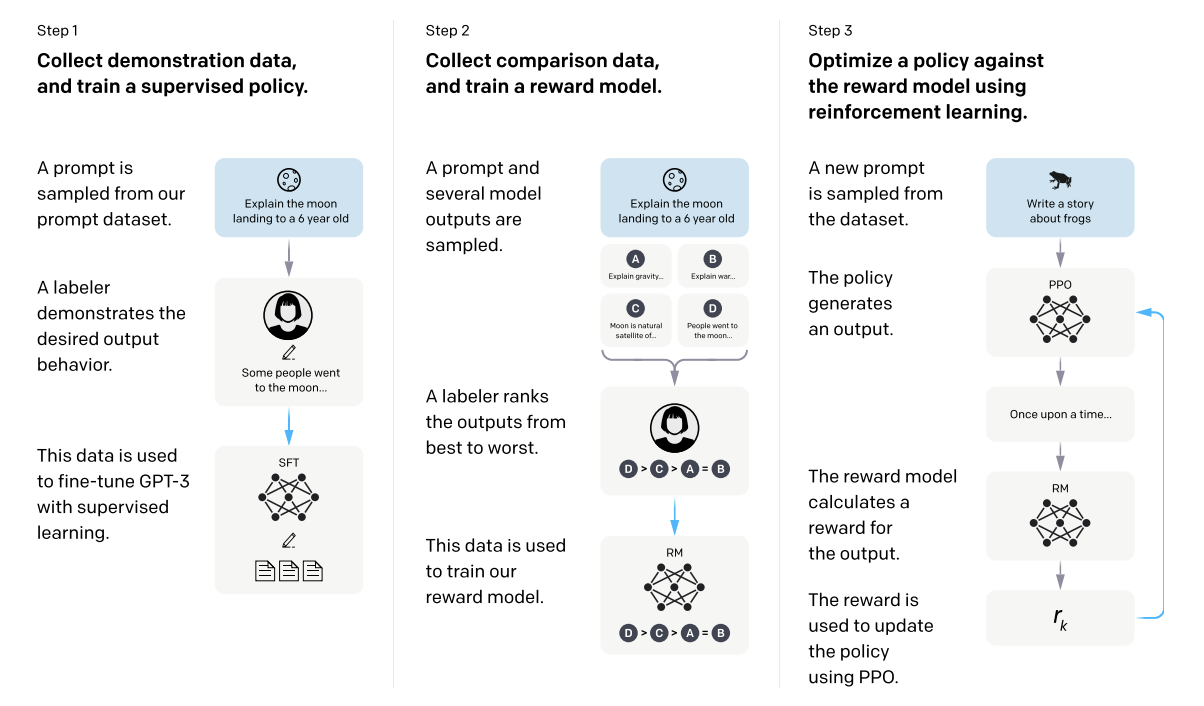
一张图表说明了我们方法的三个步骤:(1)有监督微调(SFT),(2)奖励模型(RM)训练,以及(3)通过基于奖励模型的近端策略优化(PPO)的强化学习。蓝色箭头表示这些数据用于训练我们的模型。在步骤2中,框A-D是我们的模型生成的样本,由标注员进行排序
推理者
策略规划能力
训练方法不变,还是用一阶段的训练方法。
1.内化模型能力:预训练和微调,通过在大量文本数据上预训练语言模型,使其能够捕捉语言的复杂模式和结构。以及在特定任务上对预训练模型进行微调,提高模型在特定推理任务表现。
2.外挂策略能力:生成思考链。显示的给定解决某类推理问题的思考链路和流程步骤,提高模型的策略规划能力。
3.训练语言模型进行推理(包括推理轨迹、自我生成推理),在挖掘的推理轨迹或类似推理数据上训练语言模型推理能力。
训练方法上做优化,引入强化学习方法来训练策略规划能力(过程监督)。
4.利用模型自己生成推理过程,而不是人为外在的显示输入推理过程。通过设定自我博弈策略规则,通过模型自我迭代训练来准确解决越来越难、复杂问题。
5.模型同时自我博弈训练生成解决问题的策略、步骤,同时优化每个阶段模型的生成回答的准确性(对话准确性)
后训练(post-trainng)
6.在模型初始预训练阶段之后,进一步对模型进行训练。这个阶段数据比预训练阶段数据更专注在某个领域或任务,但比微调使用的数据集更大、更广泛。
STaR
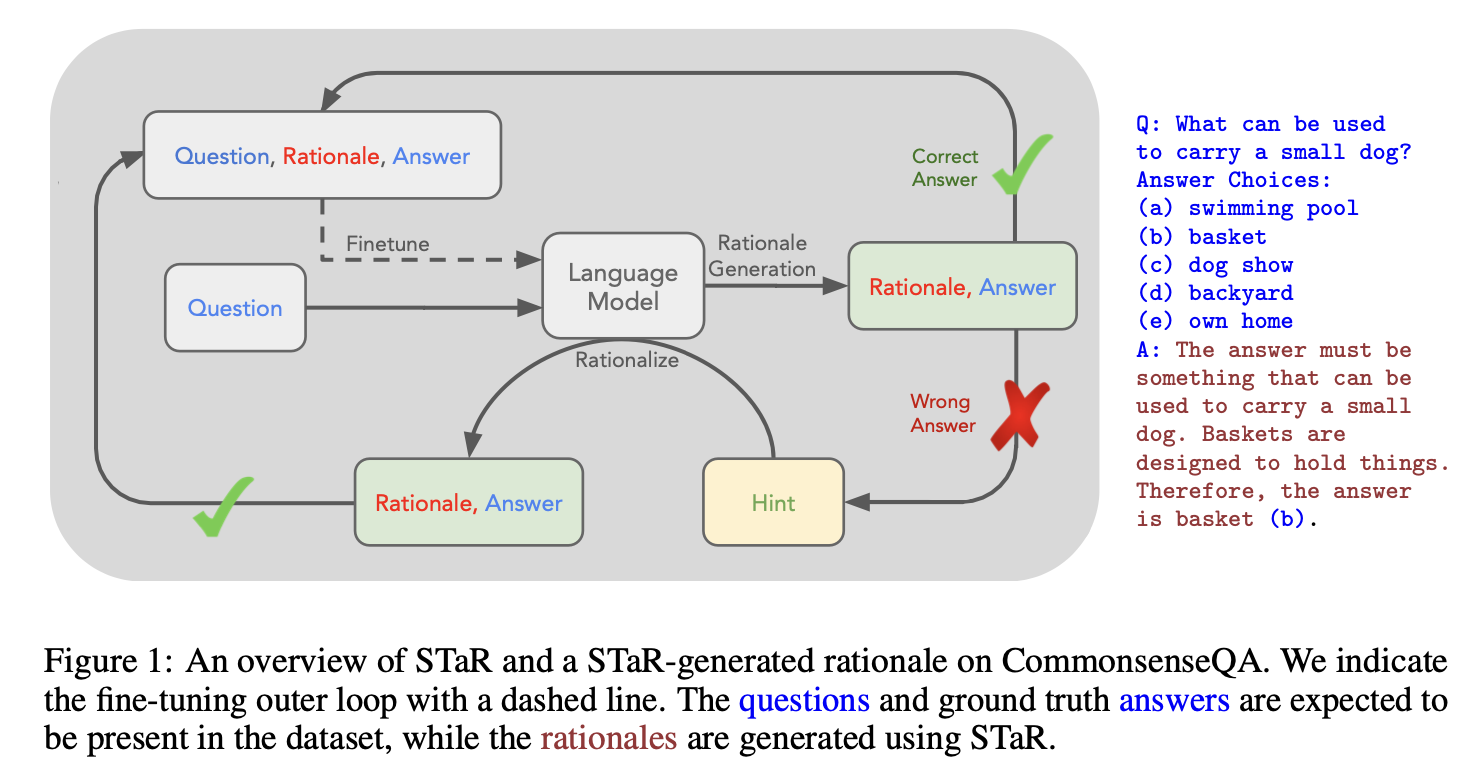
大语言模型在复杂推理任务中的表现问题。具体来说,现有的方法在生成中间推理步骤(即“推理链”)时存在一些局限性,例如需要大量人工标注的数据集或依赖于手工设计的模板,这些方法在处理新的或复杂的问题时表现不佳。此外,少样本学习(few-shot learning)虽然能在一定程度上改善模型的推理能力,但通常表现不如使用大规模数据集进行微调的模型。STaR方法通过迭代的方式,利用少量的推理示例和大规模的非推理数据集,逐步提升模型的推理能力。
核心思路是通过这种自举(bootstrapping)的方式,让模型利用自己生成的推理来不断改进自身的推理能力,将少量示例转化为大量训练数据。这种方法避免了人工标注大量推理数据的需求,同时比单纯的few-shot提示效果更好。
具体步骤如下
(1) 从少量带推理过程的示例开始,用few-shot提示让模型为大量问题生成推理过程和答案。
(2) 对于模型回答错误的问题,给出正确答案并让模型反向生成推理过程(称为"rationalization")。
(3) 用模型生成的正确推理过程和答案对模型进行微调。
(4) 重复上述过程,让模型逐步提高推理能力,解决越来越复杂的问题。
(5) 每次迭代都从原始预训练模型开始微调,避免过拟合。
关键技术点,核心思路
**推理生成(Rationale Generation):**通过生成中间推理步骤来解决问题,而不是直接预测最终答案。这样可以帮助模型更好地理解和解决复杂问题。
**合理化(Rationalization):**对于模型未能正确回答的问题,通过提供正确答案生成新的推理步骤。这一过程可以帮助模型更好地理解正确答案的推理过程,从而改进其推理能力。
迭代训练(Iterative Training):通过不断迭代的方式,逐步提升模型的推理能力。每次迭代都基于前一次迭代生成的推理步骤和合理化步骤,从而逐步扩展和改进训练数据集。
**少样本学习(Few-Shot Learning):**利用少量的推理示例作为初始输入,逐步生成更多的推理数据,从而提升模型的推理能力。
STaR方法通过自我生成和合理化推理的迭代循环,显著提高了大语言模型在复杂推理任务中的表现。该方法不仅在数学和常识推理领域表现优异,还能与更大规模的预训练模型相媲美。STaR方法展示了通过自我学习和迭代训练提升模型推理能力的巨大潜力。
Quiet-STaR
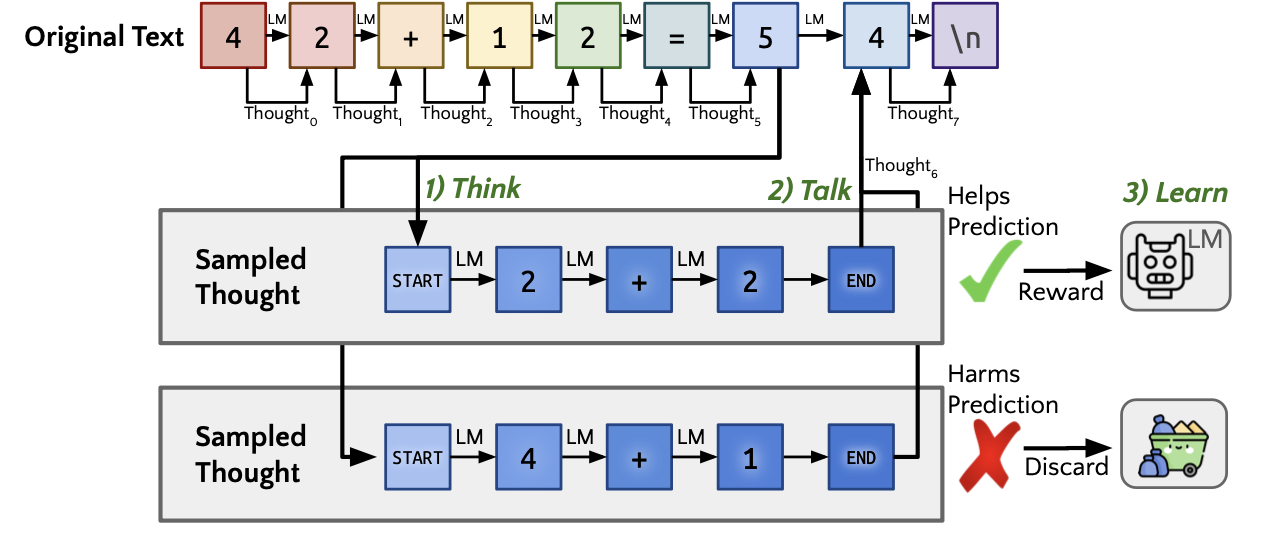
通过让语言模型在生成文本时学习生成内部理性(rationales)来提高其性能的论文。
1.主要解决的问题是,当前的语言模型在生成文本时,往往缺乏对文本背后的理性和逻辑的理解,这限制了它们在需要复杂推理的任务上的性能。
- 如何让语言模型从大规模、非结构化的文本数据中学习推理能力,而不是仅依赖于特定的推理任务或数据集。
- 如何在语言建模过程中引入和优化内部推理过程,以提高模型对未来文本的预测能力。
2.提出的解决方案
Quiet-STaR提出了一种新的训练方法,通过在每个标记后生成内部“思考”来解释未来文本,并使用强化学习(REINFORCE)来优化这些思考的生成。具体方案包括:
- 并行采样算法:在每个标记后生成多个内部思考,并行处理以提高效率。
- 混合头:将有无思考的预测结果进行加权组合,以平滑训练初期的分布偏移。
- 可学习的思考标记:引入思考开始和结束的标记,控制思考的生成过程。
- 非近视损失函数:考虑多个未来标记的预测,提高思考的效果。
3.关键技术点,核心思路
- 并行生成思考:在每个输入序列的多个标记位置并行生成思考,使用<|startofthought|>和<|endofthought|>标记来标识思考的开始和结束。
- 混合预测结果:通过混合头(一个浅层的多层感知机)将有无思考的预测结果进行加权组合,减小训练初期的分布偏移。
- 优化思考生成:使用REINFORCE算法优化思考的生成,奖励那些有助于预测未来文本的思考。
非近视损失函数:在损失函数中包含多个未来标记的预测,提高思考的效果。 - 实验验证:在GSM8K和CommonsenseQA等零样本推理任务上进行实验,验证方法的有效性,结果显示显著提升。
通过这些技术点,Quiet-STaR不仅提高了语言模型在零样本推理任务上的表现,还展示了其在处理复杂推理任务时的潜力。
核心思路是通过让语言模型在生成文本时学习生成内部理性,从而提高其对文本背后的理性和逻辑的理解,从而提高其在需要复杂推理的任务上的性能。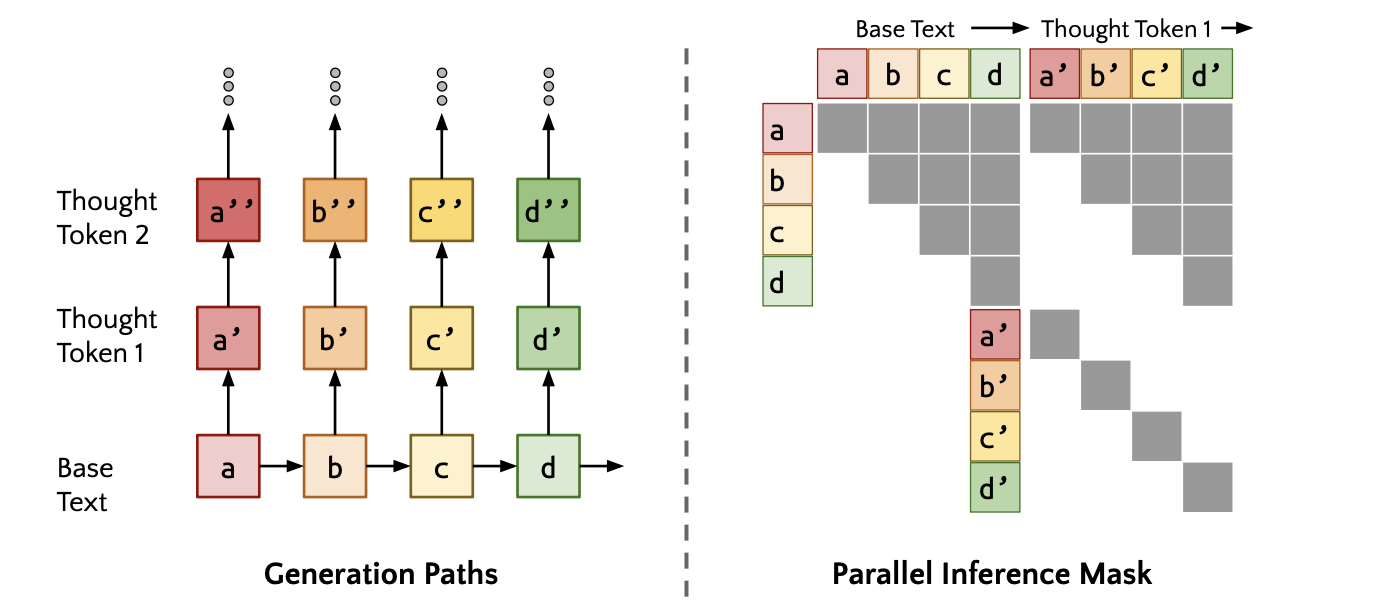
Quiet-STaR方法中的内部理性生成对模型性能的影响主要体现在以下几个方面:
- 提高推理能力:通过生成内部理性,模型能够更好地理解和推理文本中的内容。内部理性可以提供额外的上下文和信息,帮助模型更好地理解文本中的概念、关系和逻辑。这对于需要复杂推理的任务,如问答、摘要生成和文本生成等,尤其重要。
- 提高生成质量:内部理性的生成可以帮助模型生成更准确、连贯和有意义的文本。通过生成内部理性,模型可以更好地理解和组织文本中的内容,从而生成更高质量的输出。这对于需要生成高质量文本的任务,如机器翻译、摘要生成和对话系统等,尤其重要。
- 提高泛化能力:Quiet-STaR方法中的内部理性生成可以帮助模型更好地泛化到新的领域和任务上。通过生成内部理性,模型可以学习到更通用的推理和生成能力,从而在面对新的领域和任务时能够更好地适应和表现。
- 提高可解释性:内部理性的生成可以增加模型的可解释性。通过生成内部理性,模型可以提供关于其决策和推理过程的额外信息,从而帮助用户更好地理解模型的行为和输出。这对于需要可解释性的任务,如医疗诊断、金融预测和法律分析等,尤其重要。
总的来说,Quiet-STaR方法中的内部理性生成可以提高模型的推理能力、生成质量、泛化能力和可解释性,从而在各种任务上提高模型的性能。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









