







作者:Zeta 来源:投稿
编辑:学姐
最早在知乎上看到的kaggle比赛解析就三年前的座头鲸分类比赛(https://www.kaggle.com/c/humpback-whale-identification),当时我对于深度学习还是一个小白,方案的解析也只是看个热闹。
三年过去了,硕士马上就要毕业,投稿的期刊论文完成后想找找比赛增加一下项目经历,刚好发现了Happywhale比赛,也算是让🐋见证了我的成长。最后很幸运的在团队的合作下拿到了Top2%的成绩,也是第一个kaggle银牌。

比赛链接:
https://www.kaggle.com/competitions/happy-whale-and-dolphin
比赛介绍
如何通过动物的“指纹”识别它们,在大量的数据中准确识别每个个体以及新出现的个体是本次比赛的挑战。
我们使用指纹和面部识别来识别人,但我们可以对动物使用类似的方法吗?事实上,研究人员通过尾巴、背鳍、头部和其他身体部位的形状和标记手动追踪海洋生物。通过照片通过自然标记进行识别(称为照片 ID)是海洋哺乳动物科学的有力工具。
它允许随着时间的推移跟踪个体动物,并能够评估种群状况和趋势。在您对鲸鱼和海豚照片ID自动化的帮助下,研究人员可以将图像识别时间减少99%以上。更有效的识别可以使以前无法负担或不可能的研究规模成为可能。

目前,大多数研究机构都依赖于耗时的——有时甚至是不准确的——人眼手动匹配。手动匹配需要花费数千小时,其中包括盯着照片将一个人与另一个人进行比较、寻找匹配项以及识别新的人。虽然研究人员喜欢看一两张鲸鱼照片,但手动匹配限制了范围和范围。
在本次比赛中,需要开发一个模型,通过独特但通常是微妙的自然标记特征来匹配个体鲸鱼和海豚。
评价指标
本次比赛根据平均平均精度@5(MAP@5)评估提交
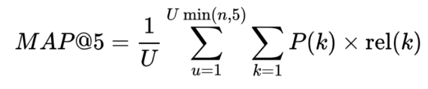
数据介绍
这些数据包括来自28个不同研究机构的30个不同物种的15,000多张独特的海洋哺乳动物个体图像。
海洋研究人员已经手动识别并给出了单独的标签。
对于每张图像,预测个体id(individual_id),测试数据中的一些个体在训练数据中没有观察到,这些个体应该被预测为新个体(new_individual)。

文件
-
Test_images:测试集,提供了27956张图片数据,种类与训练集一致。
-
Train_images:训练集,提供了51033张图片数据,分为2大类(鲸与海豚),细分为30个种类的海洋哺乳动物。
-
Sample_submission.csv:提交格式。
-
Train.csv:提供训练集每一张图片每个种类(species)和个体ID (individual_id)
数据分析及思路
数据裁剪:
根据给出的训练和测试数据可以发现,我们需要识别的主体大小不一,而且由于是海洋生物,多数拍摄距离较远但像素较高,所以我们希望人工减少噪声(背景)对模型的影响。由于数据量过大,只通过人工标注成本过大,所以我们可以标注一部分数据后,训练一个目标检测模型辅助图像裁剪。

DOLG:
DOLG是一种用于端到端图像检索的信息融合框架(正交Local and Global, DOLG)。该算法首先利用多尺度卷积和自注意力方法集中提取具有代表性的局部信息。然后从局部信息中提取与全局图像表示正交的分量。最后,将正交分量与全局表示法进行互补连接,然后进行聚合生成最终的表征。使用这种方法可以大大提高模型对局部信息及全局信息的表征能力。
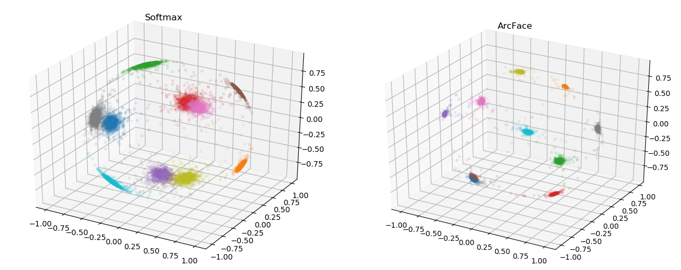
SoftMax和ArcFace:
特征学习任务具有两个关键要素,分别是特征的类内紧凑度和类间分离度。当拥有类别标签时,可以通过使用分类器和分类损失函数来进行训练,从而学习到一个深度特征空间。经典的softmax函数为了向加强类内紧凑度和类间分离度两个方向发展,逐渐演变成ArcFcae。
代码流程
-
图像数据预处理-标志性特征图片裁剪:首先根据开源的标注数据训练YOLOv5目标检测模型,将训练集与测试集数据裁剪出背鳍或者身体部分。
-
背鳍图片特征提取模型:将训练集数据划分为训练与验证两部分,训练EfficientNet-B7(backone)模型,将backone的最后两个模块的特征层输入DOLG(正交特征融合层)融合,使用Arcface作为损失函数,有效增强类内紧凑度和类间分离度。
-
伪标签噪音数据融合:将训练完成的模型提取测试集数据嵌入特征,根据验证结果的confidence采用部分测试集预测结果构建伪标签数据,连同步骤2的训练部分一起重新训练backone模型。
-
聚类与排序:利用最终训练完成的backone模型分别提取训练集与测试集嵌入特征,训练集嵌入特征训练KNN模型,然后推断测试集嵌入特征距离,排序获取top5类别,作为最终结果
部分代码展示
数据增强:
def random_float(minval=0.0, maxval=1.0):
rnd = tf.random.uniform(
[], minval=minval, maxval=maxval, dtype=tf.float32)
return rnd
def choice(p, image1, image2):
rnd = random_float()
image = tf.where(rnd <= p, image1, image2)
# mask = tf.where(rnd <= p, mask1, mask2)
return image
def RandomRotate(Degree,p):
def _do_RandomRotate(image):
degree = random.uniform(-Degree, Degree)
aug_image = tfa.image.rotate(image, degree * math.pi / 180)
return choice(p, aug_image, image)
return _do_RandomRotate
random_rotate = RandomRotate(Degree= 25,p=0.5)
模型代码:
class ArcMarginProduct(tf.keras.layers.Layer):
#Implements large margin arc distance.
#Reference:
#https://arxiv.org/pdf/1801.07698.pdf
#https://github.com/lyakaap/Landmark2019-1st-and-3rd-Place-Solution/
#blob/master/src/modeling/metric_learning.py"
def __init__(self, n_classes, s=30, m=0.50, easy_margin=False,
ls_eps=0.0, **kwargs):
super(ArcMarginProduct, self).__init__(**kwargs)
self.n_classes = n_classes
self.s = s
self.m = m
self.ls_eps = ls_eps
self.easy_margin = easy_margin
self.cos_m = tf.math.cos(m)
self.sin_m = tf.math.sin(m)
self.th = tf.math.cos(math.pi - m)
self.mm = tf.math.sin(math.pi - m) * m
def get_config(self):
config = super().get_config().copy()
config.update({
'n_classes': self.n_classes,
's': self.s,
'm': self.m,
'ls_eps': self.ls_eps,
'easy_margin': self.easy_margin,
})
return config
def build(self, input_shape):
super(ArcMarginProduct, self).build(input_shape[0])
self.W = self.add_weight(
name='W',
shape=(int(input_shape[0][-1]), self.n_classes),
initializer='glorot_uniform',
dtype='float32',
trainable=True,
regularizer=None)
def call(self, inputs):
X, y = inputs
y = tf.cast(y, dtype=tf.int32)
cosine = tf.matmul(
tf.math.l2_normalize(X, axis=1),
tf.math.l2_normalize(self.W, axis=0)
)
sine = tf.math.sqrt(1.0 - tf.math.pow(cosine, 2))
phi = cosine * self.cos_m - sine * self.sin_m
if self.easy_margin:
phi = tf.where(cosine > 0, phi, cosine)
else:
phi = tf.where(cosine > self.th, phi, cosine - self.mm)
one_hot = tf.cast(
tf.one_hot(y, depth=self.n_classes),
dtype=cosine.dtype
)
if self.ls_eps > 0:
one_hot = (1 - self.ls_eps) * one_hot + self.ls_eps / self.n_classes
output = (one_hot * phi) + ((1.0 - one_hot) * cosine)
output *= self.s
return output
DOLG:
class DolgBranch(tf.keras.layers.Layer):
def __init__(self, dolg_s, idx, **kwargs):
super().__init__(name=f'dolg_branch_{idx}', **kwargs)
dolg_s = int(dolg_s)
# Local
self.mam = MultiAtrous(dolg_s, name=f'mam_{idx}')
self.sa2d = SpatialAttention2d(dolg_s, name=f'sa2d_{idx}')
# Global
self.global_branch = GlobalBranch(dolg_s, name=f'g_{idx}')
# Orthogonal Fusion
self.orthogonal_fusion = OrthogonalFusion()
# Pooling
self.pool = GeM()#tf.keras.layers.GlobalAveragePooling2D()
@tf.function()
def call(self, inputs):
inputs_l, inputs_g = inputs
# Local
l = self.mam(inputs_l)
l = self.sa2d(l)
# Global
g = self.global_branch(inputs_g)
# Orthogonal Fusion
f = self.orthogonal_fusion([l, g])
# Pooling
descriptor = self.pool(f)
return descriptor
关注【学姐带你玩AI】公众号
回复 “ALL IN” 领取 5年kaggle比赛
参考资料
代码链接:
https://github.com/ZetaLx/Kaggle-Happywhale
DOLG论文:
https://arxiv.org/pdf/2108.02927.pdf
Arcface论文:
https://arxiv.org/pdf/1801.07698.pdf

















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









